注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
16 - ユーティリティファイルを適用してデータの前処理を行う
learn.palantir.com でも以下の内容をご覧いただけますが、アクセシビリティの観点から、ここに掲載しています。
📖 タスクの概要
このリポジトリ内のどのファイルからもアクセスできるユーティリティを作成したので、それらを使って生のデータセットに前処理を行い、前処理済みのデータセットを作成します。このタスクでは、前回の演習で行った手順の一部を再現しますが、説明は簡略化されているので、最小限の指示で学んだことを実践する機会が得られます。
🔨 タスクの説明
-
リポジトリの Files パネルで
/datasetsフォルダーを右クリックし、New folder を選択します。 -
新しいフォルダーに
preprocessedという名前を付け、ファイル作成ウィンドウの右下にある Create をクリックします。 -
新しい
preprocessedフォルダーに以下の3つのファイルを作成します。flight_alerts_preprocessed.pypriority_mapping_preprocessed.pystatus_mapping_preprocessed.py
-
すべての3つのファイルに、リポジトリ内の utils ファイルを参照して使用できるようにするために、次のコードスニペットを 2 行目に追加します。
from myproject.datasets import type_utils as types, cleaning_utils as clean -
これら3つの新しい変換ファイルのそれぞれについて、SOURCE_DATASET_PATH を前回の演習で生成された生の出力ファイルの RID に置き換えます。以下の画像は、
flight_alerts_preprocessed.pyファイルのコピーペーストワークフローを示しています。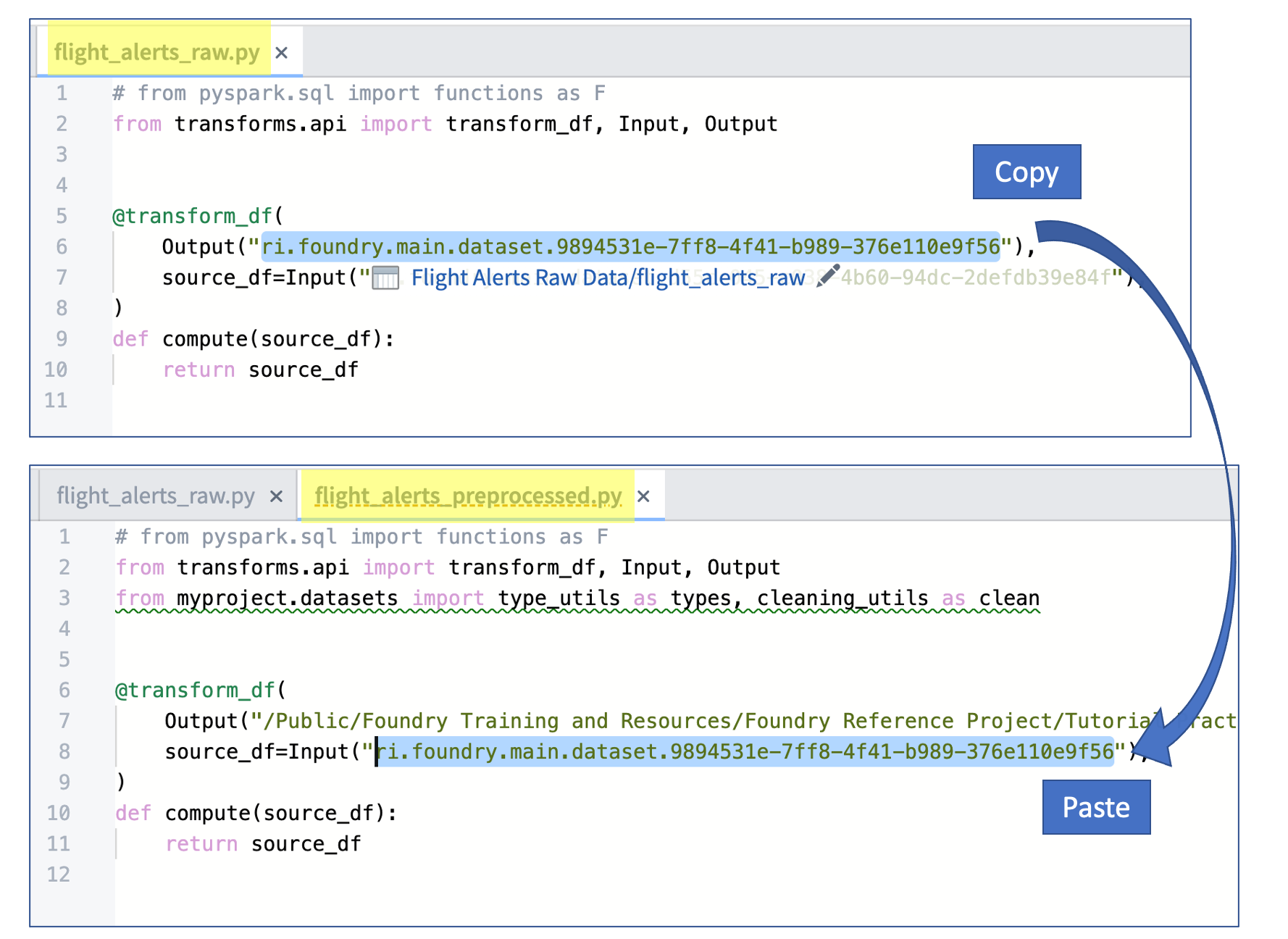
-
これら3つの新しい変換ファイルのそれぞれについて、10 行目以降のすべてを対応するコードブロックに置き換えます。
-
以下は
flight_alerts_preprocessed.pyファイルのコードです。def compute(source_df): # normalize する文字列の列を定義 normalize_string_columns = [ 'category', ] # 文字列にキャストする列を定義 cast_string_columns = [ 'priority', 'status', ] # 日付にキャストする列を定義 cast_date_columns = [ 'flightDate', ] # utils ファイルからの関数を使って列を適切な型にキャスト typed_df = types.cast_to_string(source_df, cast_string_columns) typed_df = types.cast_to_date(typed_df, cast_date_columns, "MM/dd/yy") # utils ファイルからの関数を使って文字列と列名を normalize normalized_df = clean.normalize_strings(typed_df, normalize_string_columns) normalized_df = clean.normalize_column_names(normalized_df) return normalized_df -
以下は
priority_mapping_preprocessed.pyおよびstatus_mapping_preprocessed.pyファイルのコードです(それぞれ同じコードブロックを使用します)。def compute(source_df): # normalize する文字列の列を定義 normalize_string_columns = [ 'mapped_value', ] # 文字列にキャストする列を定義 cast_string_columns = [ 'value', ] # utils ファイルからの関数を使って列を適切な型にキャストし、文字列を normalize normalized_df = types.cast_to_string(source_df, cast_string_columns) normalized_df = clean.normalize_strings(normalized_df, normalize_string_columns) return normalized_df
前処理済みの変換でクリーニングとタイプユーティリティがどのように呼び出されるか、コードコメントと構文を確認してください。
-
-
Preview オプションを使って各変換ファイルをテストし、ユーティリティ関数の適用によって出力がどのように変わるかを確認します(例:
flightDate列が date タイプになり、マッピングファイルのmapped_values列が適切にフォーマットされる)。 -
「feature: add preprocessing transforms」といった意味のあるメッセージでコードをコミットします。
-
CI チェックが通ったら、フィーチャーブランチで各データセットを
Buildします。 -
ブラウザを更新する必要があるかもしれませんが、各前処理済みの変換ファイルに戻って、ハイパーリンクされたテキスト「Replace paths with RIDs」をクリックしてみてください。
-
データセットアプリケーションでブランチ上の出力データセットを検証した後、(Squash して)フィーチャーブランチを
Masterにマージします。 -
フィーチャーブランチを削除します。
-
Masterブランチでデータセットをビルドし、データセットアプリケーションで出力を確認します。