Warning
注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
7 - 前処理ロジック:データセットのマッピング
learn.palantir.com でも以下の内容をご覧いただけますが、アクセシビリティの観点から、ここに掲載しています。
📖 タスクの概要
ユーザーの二つのマッピングデータセットに同様の変換を適用してみましょう。どちらのデータセットも、行名の正規化と値の文字列キャストと標準化が必要です。
🔨 タスクの説明
-
priority_mapping_rawとstatus_mapping_rawのそれぞれに変換ノードを追加します。 -
それぞれのデータセットの変換について:
- 変換の名前を(アプリケーションの左上隅で)Preprocess priority mapping と Preprocess status mapping とそれぞれつけます
- 値の行を文字列として キャスト します
- mapped_value行をタイトルケースに変換します
-
さらに、
status_mapping_rawについては、空白を削除し、アンダースコアなしで値をタイトルケースに変換する変換を見つけて設定できるか確認してみてください。詰まった場合は、ヒントを参照して実装の提案をご覧ください。ヒント:
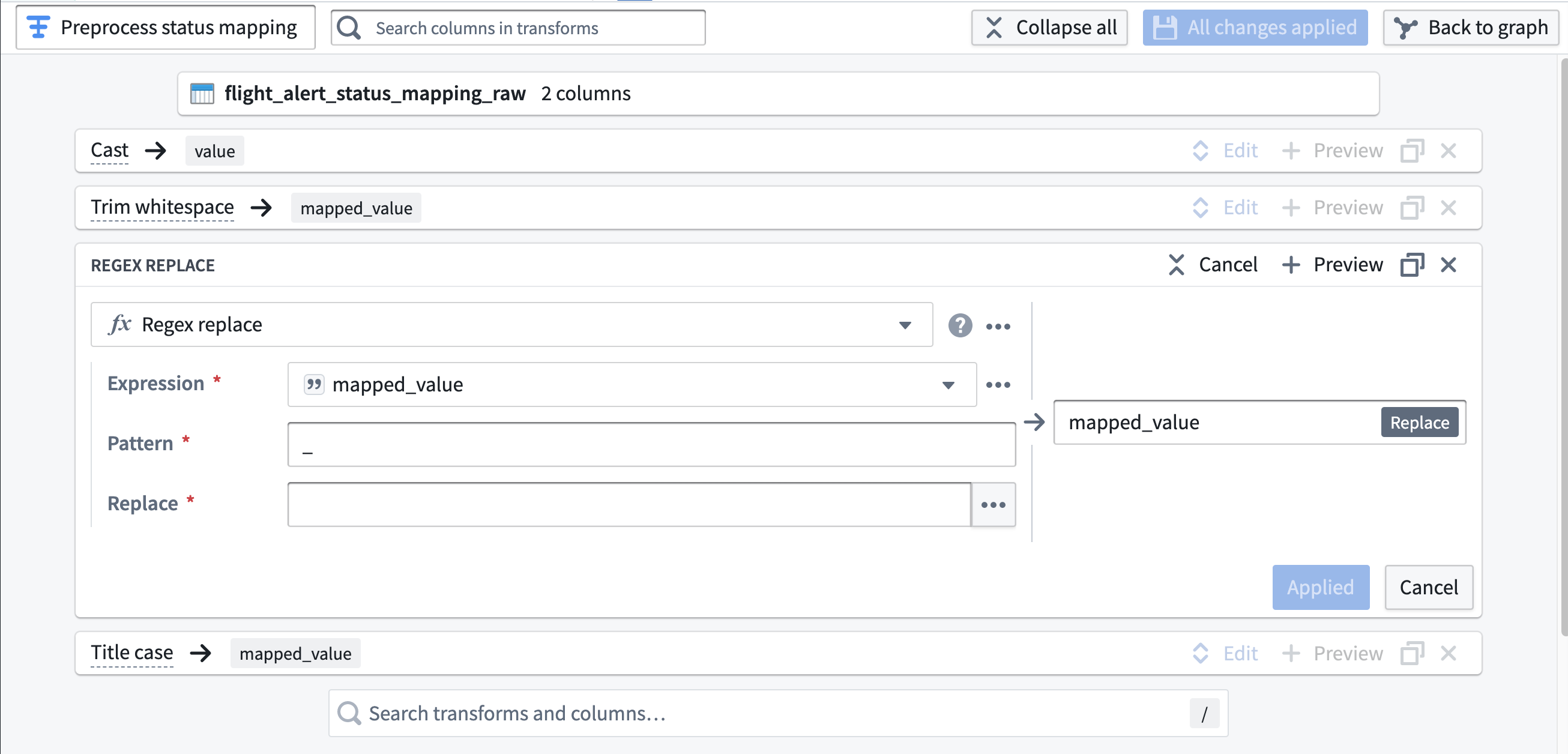
-
それぞれに
priority_mapping_preprocessedとstatus_mapping_preprocessedと名付けたパイプライン出力を追加します。 -
パイプラインを 保存 し、ユーザーの
/preprocessedフォルダーに出力をビルドするためにパイプラインを デプロイ します。