注: 以下の翻訳の正確性は検証されていません。AIPを利用して英語版の原文から機械的に翻訳されたものです。
4 - 表形式データの質問レビュー
この内容は learn.palantir.com ↗ でもご覧いただけますが、アクセシビリティの観点から、ここに掲載しています。
このデータセットは何個のファイルで構成されていますか?
データセットアプリケーションの詳細タブには、ファイルフィールドがあり、データセットファイルの数と合計ファイル数が表示されます。これは通常、データベースファイルの数 + トランザクション中に生成された Spark ログファイルの数です。
答えは Spark がトランスフォームを実行した方法によって異なる場合がありますが、おそらく 5 個から 8 個の間です。これは Data Analysts にとって重要です。なぜなら、Contour や Code Workbook などの表形式データを使用するアプリケーションのパフォーマンスは、Spark がデータセットファイルをどれだけ効率的に生成したか(つまり、ファイルのサイズと数)に依存するためです。Spark の動作についてさらに詳しく知りたい場合は、Spark の概念を確認するか、記録された Spark 最適化トレーニング ↗を視聴してみてください。
これらのファイルを一貫したデータセットにまとめた最後の成功したトランザクションはいつですか?
履歴タブで、このデータセットのすべての試行ビルドを確認できます。リストには、成功したジョブ、失敗したジョブ、実行されなかったジョブなどが表示されることがあります。現在のデータセットビューのトランザクションの日付、ステータス、および種類を最も早く確認するには、詳細タブを開き、画面の左側にある Current transaction view オプションをクリックしてください。
以下の画像(ユーザーのエンロールメントによって異なる場合があります)では、最新の成功したトランザクションは 2022 年 10 月 6 日午前 9 時 4 分の スナップショット でした。
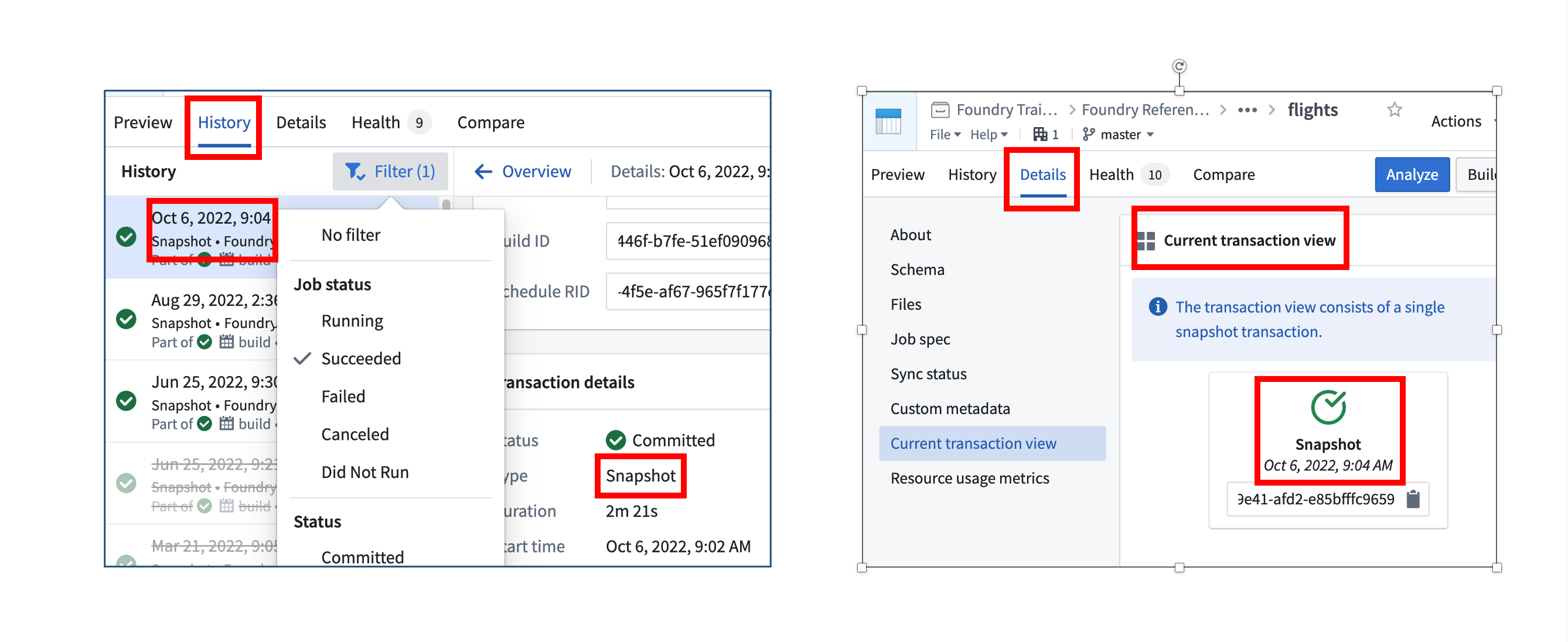
現在のビューを作成したトランザクションの種類は何ですか?
上記の答えを参照してください。
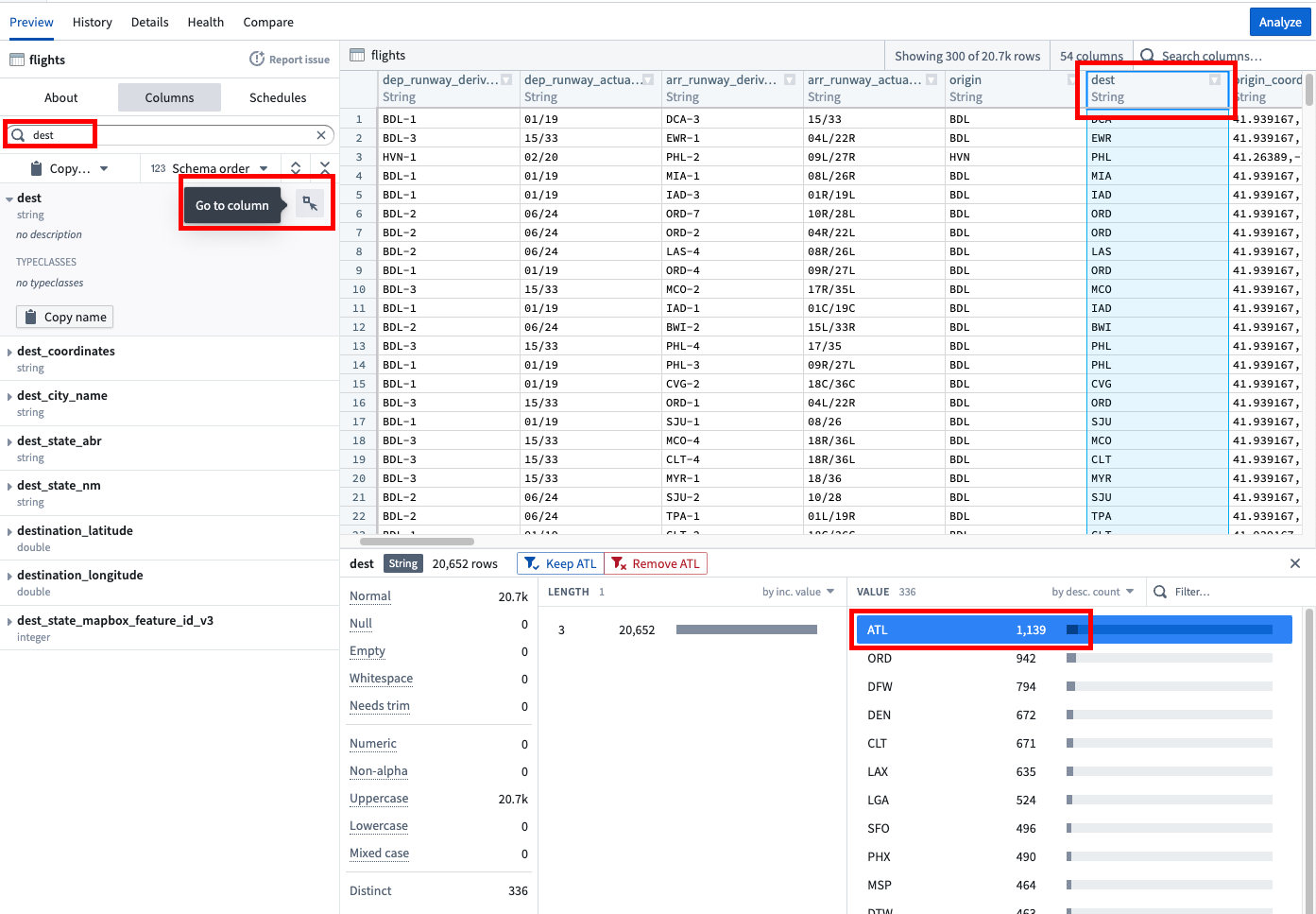
最も一般的なフライトの目的地はどこですか?
Foundry の分析アプリケーションのいずれかにデータセットを取り込む前に、プレビューテーブル を使用してデータ構造を理解し、データセットの値を迅速に探索できます。以下の画像のアナリストは、目的地の列を検索し、データビューを by desc. count に切り替えて、降順でカウントされた目的地を確認しました。
ヒストグラムを確認すると、ATL が最も多くのフライトを持っていることがわかります。