- Capabilities
- Getting started
- Architecture center
- Platform updates
Create match conditions
Sensitive Data Scanner comes with a set of built-in match conditions; you can also define your own custom match conditions to use with Sensitive Data Scanner.
Built-in match conditions
Sensitive Data Scanner provides a range of built-in match conditions to detect common types of PII, such as Social Security numbers, e-mail addresses, or phone numbers. You can find these by selecting the arrow to expand the Built-in Match Conditions section in the right sidebar:
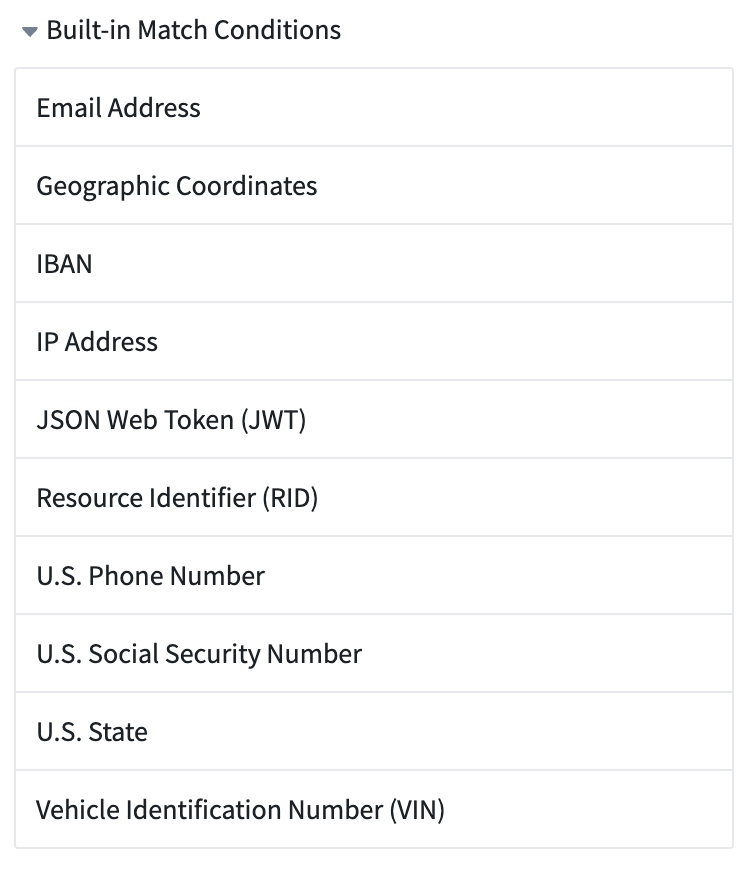
Built-in match conditions are designed to detect common types of personal data. However, their effectiveness varies based on your specific data structure and format. Ensure these conditions align with your unique data standards, potentially creating custom conditions as needed. Consult your data protection officer if you have further questions.
Create custom match conditions
To create a custom match condition for your space, there are two ways to get started:
- From the Sensitive Data Scanner landing page.
- While creating a sensitive data scan.
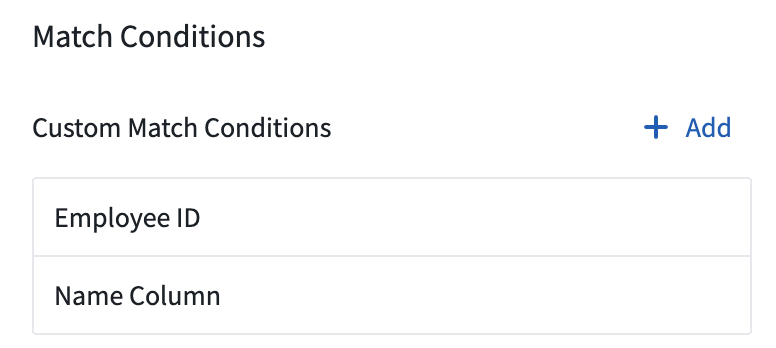
From the landing page, select Add above the Custom Match Conditions listed in the match conditions sidebar.
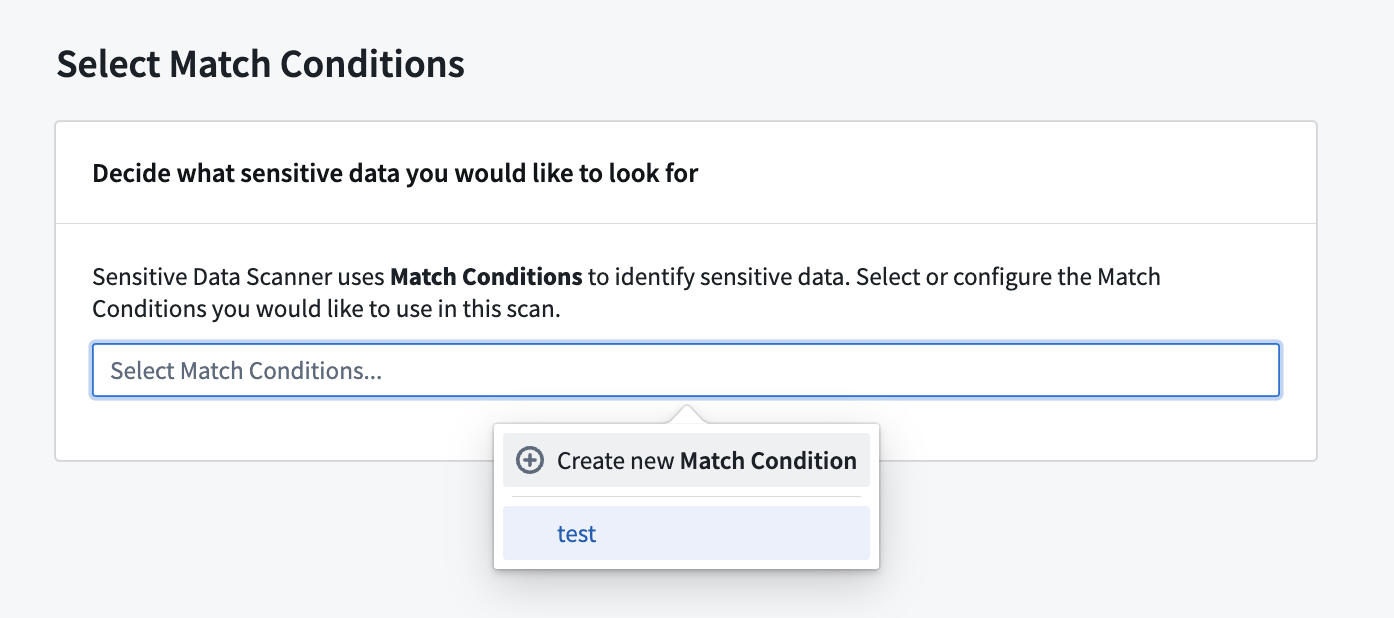
While creating a sensitive data scan, on the Select match conditions page, you can also create a new match condition and immediately use it in your scan by selecting Create new match condition.
Both of these starting points open the same match condition creation process. From there, you can choose whether to create a regex (Regular expression) match condition, or an overlap (Value overlap) match condition.
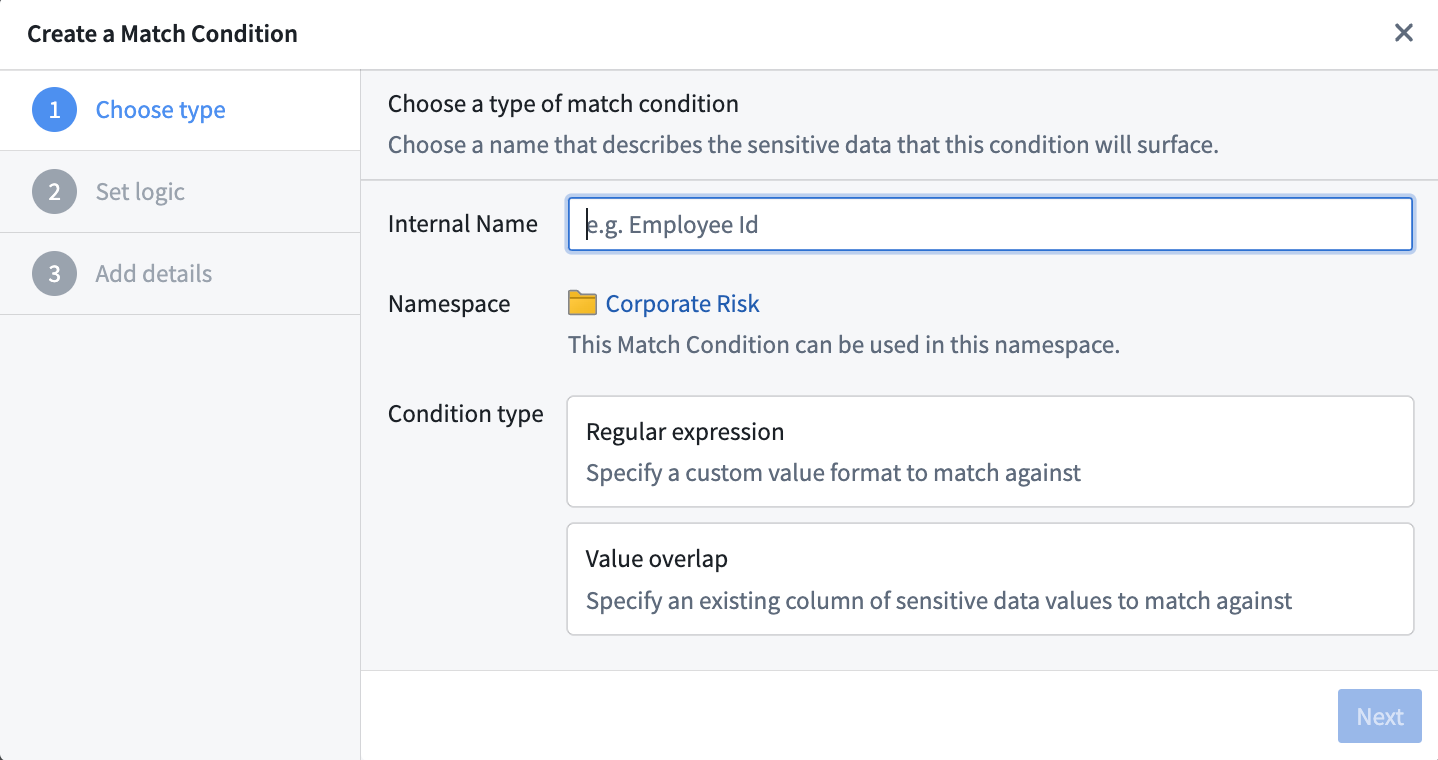
Create a regex match condition
When creating a regular expression (regex) match condition, there are two types of regex options you can specify; content regex and column name regex.
- Content regex: A regex that Sensitive Data Scanner will check against the content of a dataset (not the column names of the dataset).
- Column name regex: A regex that Sensitive Data Scanner will check against the column names of a dataset (not the content itself).
Sensitive Data Scanner allows you to combine these two regex options for maximum specificity:
- Highlight a dataset if the content regex matches.
- Highlight a dataset if the column name regex matches.
- Highlight a dataset if both content and column name regexes match.
- Highlight a dataset if either content or column name regexes match.
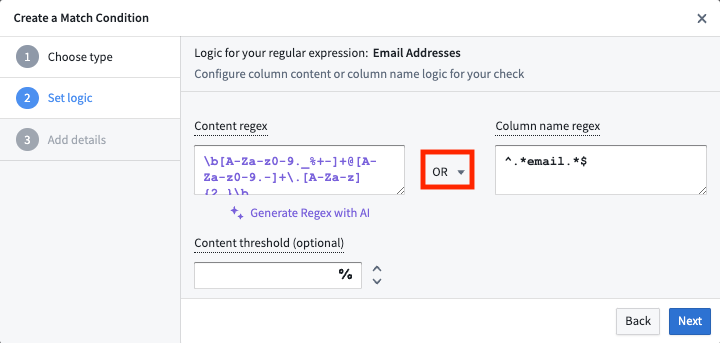
The content regex contains an optional content threshold field in which you can specify a number greater than 0 and less than or equal to 100; this content threshold is the percentage of the cells in a particular column of a given dataset that must match the content regex in order for that dataset to be highlighted as a match. The content threshold field is optional. If no value is specified, Sensitive Data Scanner will highlight a dataset as a match if there is at least one match of the content regex.
Regex generation with AIP
If AIP is enabled for your enrollment in Foundry, you also have the ability to specify the content regex with the help of AI. You can do this with the Generate Regex with AI button. Selecting this button will prompt you to describe the type of sensitive data to detect, for instance "all email addresses", show you examples that match the proposed regex, and then generate the regex for use in the application. The graphic below demonstrates this process.
Create an overlap match condition
Overlap match conditions are useful when looking for sensitive data that cannot be distilled into regex. For example, it can be difficult to create a content regex to match names, although creating a column name regex can be sufficient in some instances. However, the overlap match condition can be useful if you already have a dataset with an exhaustive list of sensitive data that you want to scan for.
The screenshot below is an example of how to select a specific column. In this example, the EL_employee_name column of the accounts_with_context dataset is set as the overlap column to which we will match other data. If any cell in the overlap column matches any other cell in another dataset, that other dataset will be highlighted as a match for this match condition.