- Capabilities
- Getting started
- Architecture center
- Platform updates
Conclusion and next steps
In this tutorial, we created a supervised machine learning project in Foundry, in which we:
- Created a project for iterative model experimentation and development,
- Performed initial feature preparation and pipelining,
- Trained a production-ready model,
- Deployed our model to a live-hosted endpoint and a batch pipeline that automatically updates.
Foundry automatically tracks the lineage of all resources you produce in the platform. At the end of this tutorial, you will have a pipeline resembling the below screenshots.
Action: Navigate to your house_price_predictions dataset, select Explore pipelines > Explore data lineage.
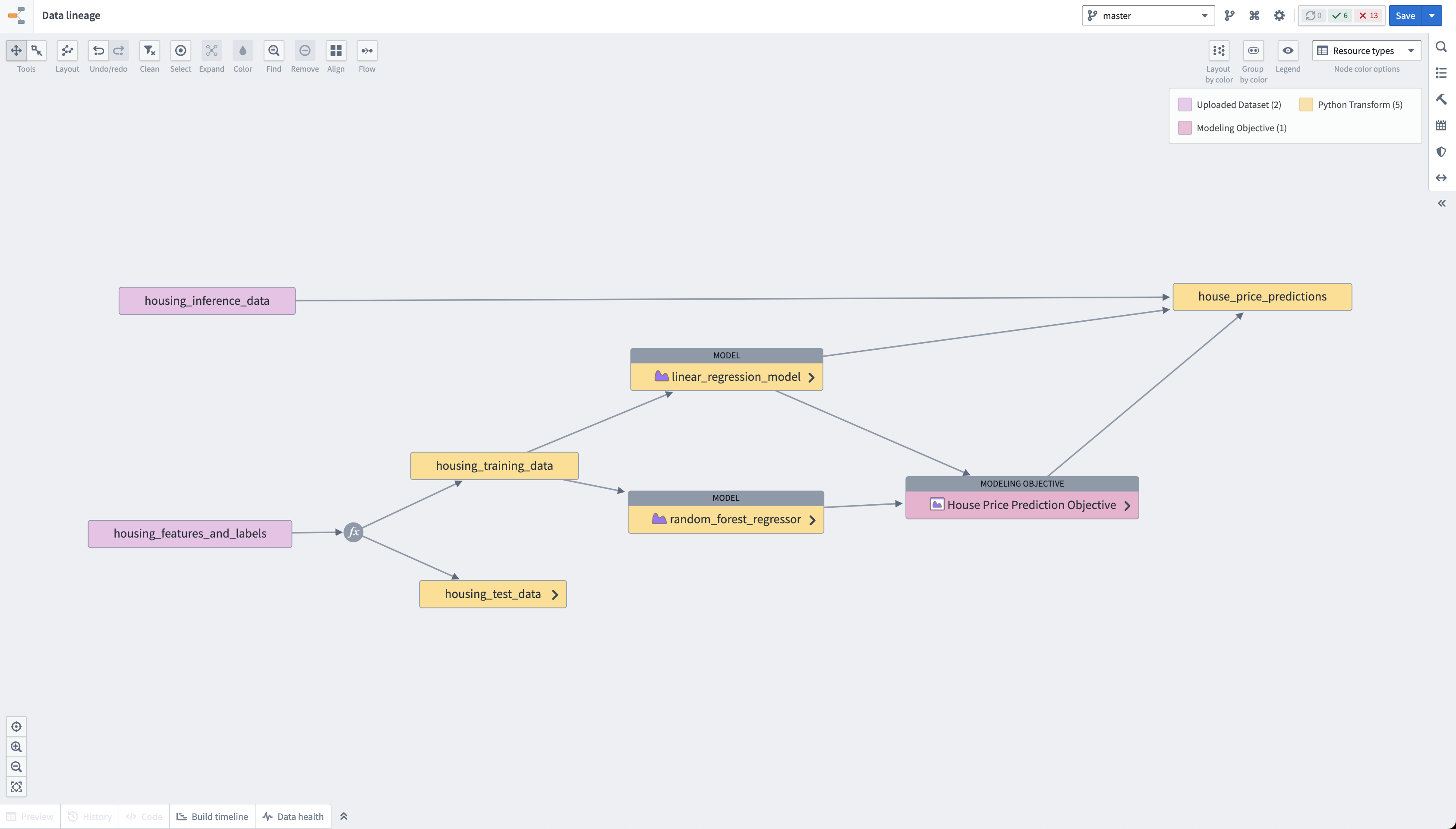
Next steps
The next step is to convert this example workflow to a real workflow at your organization.
This typically includes:
- Integrate data from a range of data sources into Foundry to create a
features_and_labelsdataset that can be used for training and testing different models. - Try different model architectures, parameters, and features to get the best performance for your model.
- Integrate your model's predictions into the Foundry Ontology for use in operational applications either through a batch deployment, live deployment, or Python transforms.
- Create pre-release checks in your modeling objectives to ensure models are approved before release.
- Create "writeback" actions to capture user actions as a new dataset and use this data for continuous re-training and improvement of your model.
- Create a model inference history to improve and iterate on your model for more accurate performance and usage.