- Capabilities
- Getting started
- Architecture center
- Platform updates
Set up and use a live deployment
A live deployment is a persistent, scalable deployment for your releases that you can interact with via an API endpoint. Live deployments can be managed together with your batch deployments in a modeling objective, receiving all the same benefits of automated upgrades, observability, and permissions structure. Live deployments can now also be configured on the model page directly without requiring objectives.
Requirements
Before creating a new live deployment, the modeling objective must contain an existing release with the corresponding tag (either Staging or Production).
Create deployment
To create a new live deployment, navigate to the Deployments section at the bottom of your modeling objective, and select the blue + Create a deployment button.
Fill out the deployment name, a description, and whether this deployment should be based on the current staging or production released model. Once configuration is complete, select Create deployment.
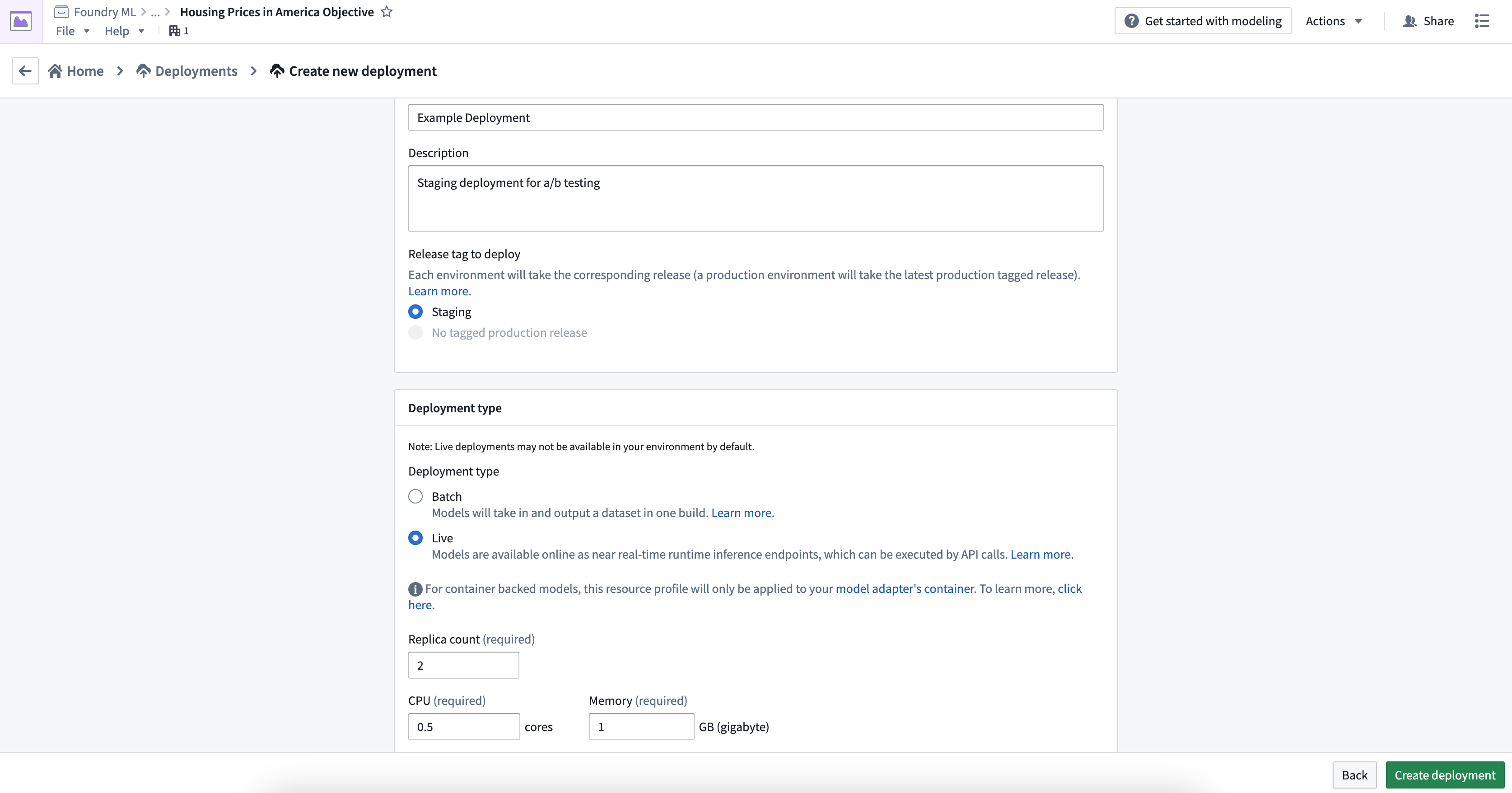
Select the newly created deployment to open the details where you will see interim statuses, indicating that the container image containing the latest release and inference code is being deployed.
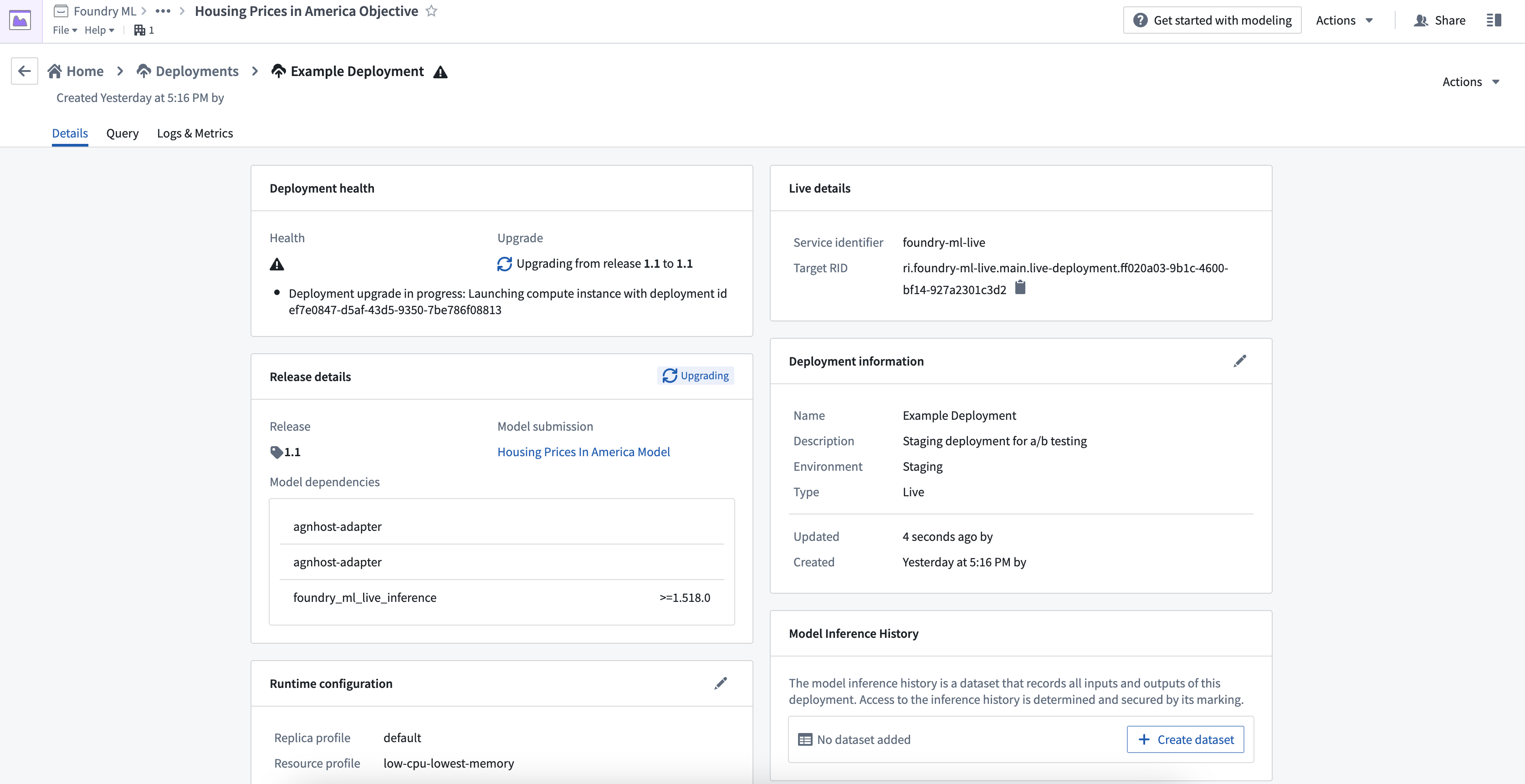
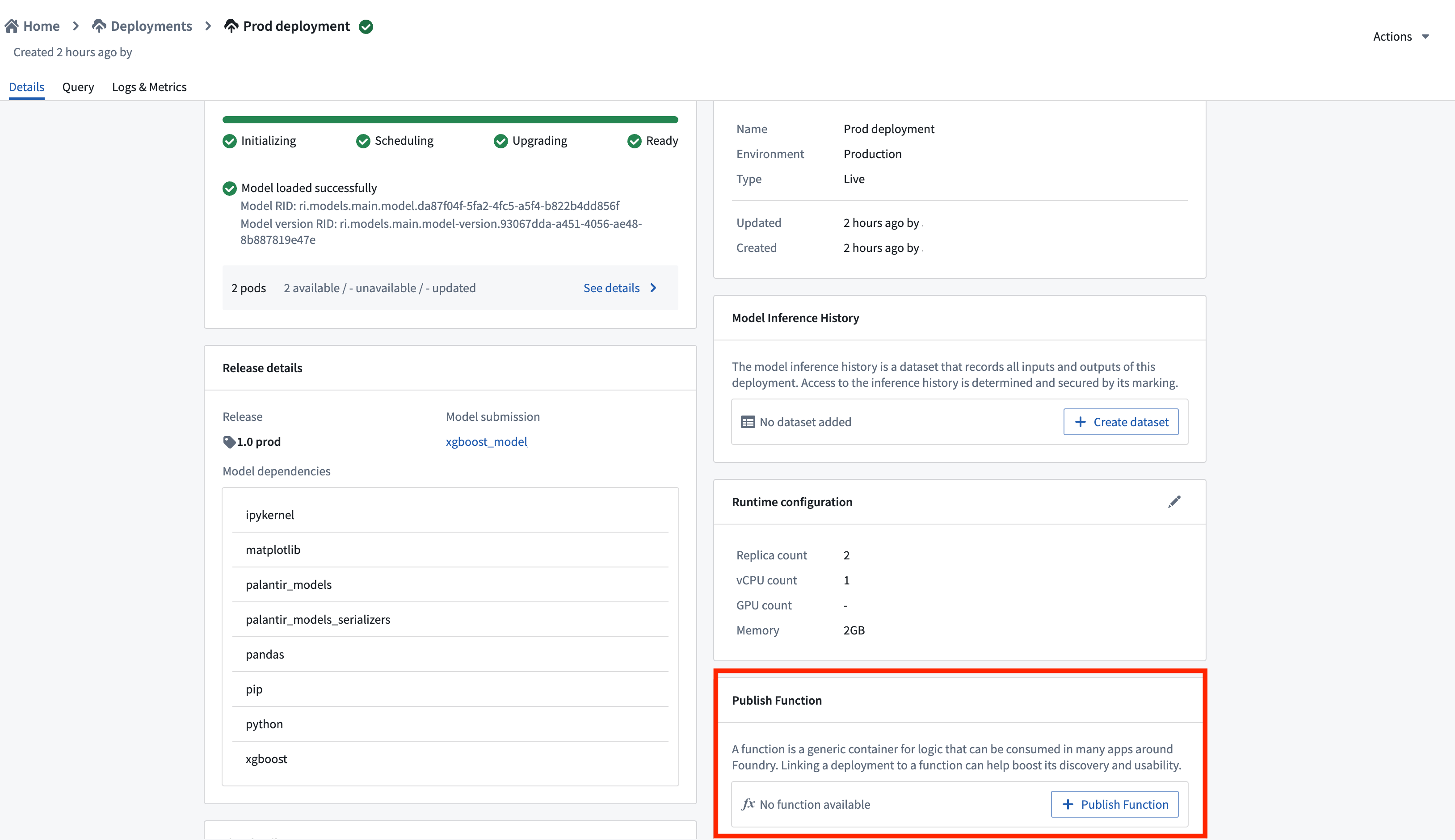
Publish function
You can publish a function for the deployment, enabling usage of models for live inference in Workshop, Vertex, and other end-user applications.
To publish a function, navigate to the Details page of your deployment and select Publish Function. This creates a wrapper function with the same input and output API as your model, which can be imported and called from a functions repository to add custom business logic.
For details on function behavior, version upgrades, and configuration options, see the Model functions developer guide.
Status and health
After the deployment finishes updating, the status and health should both appear as green checkmarks. These indicate the deployment is ready for querying and has been successfully updated to contain the latest released model.

Test live deployment
You can test the live deployment endpoint by going to the Query tab on the deployment details page. You can author the input request, send it to the live endpoint, and view the model output response. Two query types are available: single I/O and multi I/O.
Single I/O queries only support single tabular input/output, while multi I/O queries only support the ModelAdapter API defined in a model asset. Model assets support both single I/O and multi I/O query types, while dataset-backed deployments only support single I/O queries.
Example command
Below is an example of how to query a live deployment via curl using single I/O with the transform endpoint:
Copied!1 2 3 4curl -X POST https://<URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.main.live-deployment.<RID> -H "Authorization: <BEARER_TOKEN>" -H "Accept: application/json" -H "Content-Type: application/json" -d '{"requestData":[{"house-location":"New York", "bedrooms":3,"bathrooms":1.5}], "requestParams":{}}'
Alternatively, the example below shows how to query a live deployment via curl using multi I/O with the transformV2 endpoint:
Copied!1 2 3curl -X POST https://<URL>/foundry-ml-live/api/inference/transform/ri.foundry-ml-live.main.live-deployment.<RID>/v2 -H "Authorization: <BEARER_TOKEN>" -H "Accept: application/json" -H "Content-Type: application/json" -d '{"input_df":[{"house-location":"New York", "bedrooms":3,"bathrooms":1.5},{"house-location":"San Francisco", "bedrooms":2,"bathrooms":1}]}'
Deployment actions
Management actions
There are two options to take on a running live deployment:
- Disable to turn off the deployment but still allow for re-enablement to leverage the same Target RID.
- Delete to remove the deployment completely. The old Target RID will no longer be able to be queried.
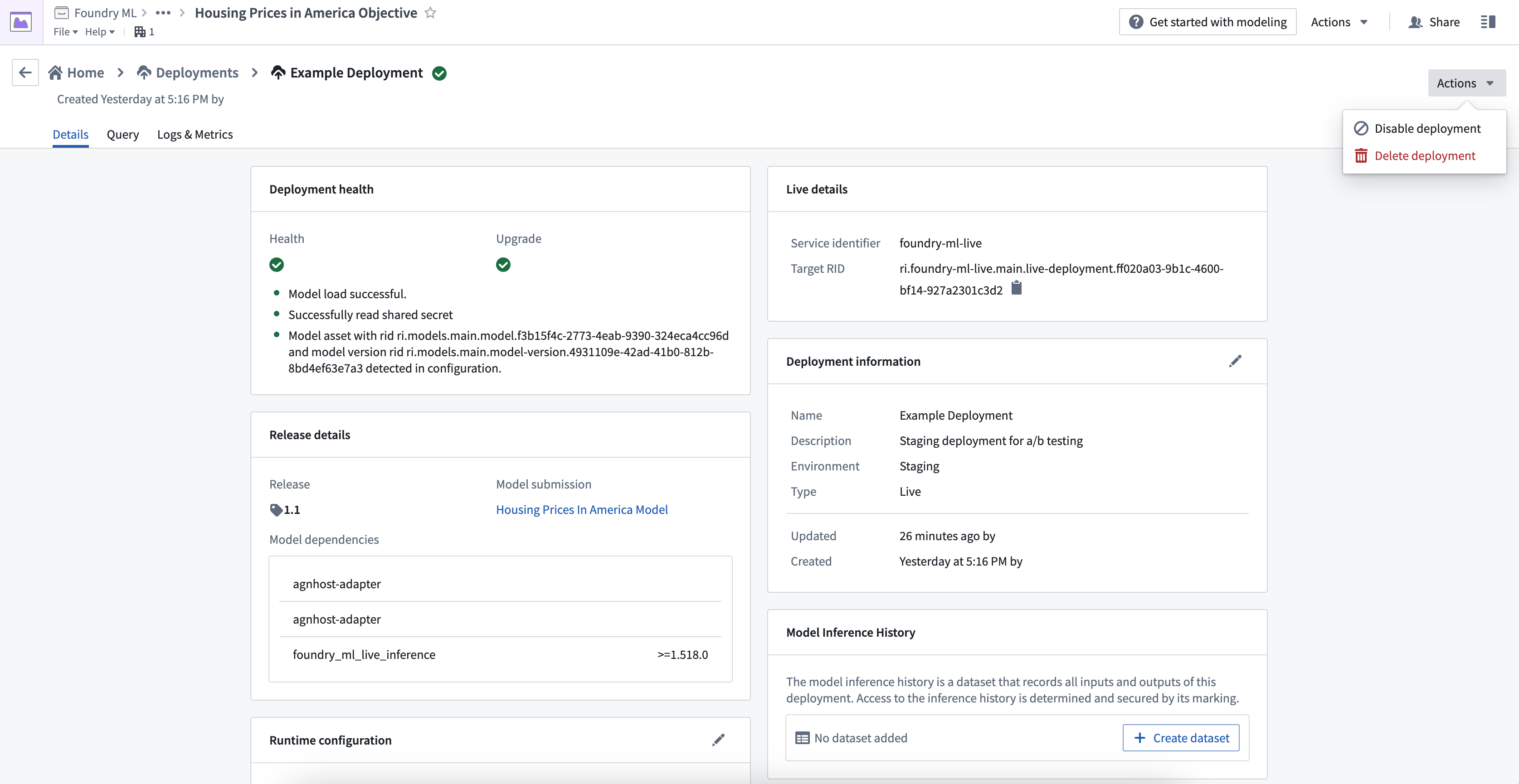
A disabled live deployment will still appear in the Deployments page on an objective and is available to be enabled again.

Resource configuration
A live deployment is configured with both a replica count as well as CPU and GPU counts.
You can configure resource requirements upon deployment creation, as well as edit after the fact. Editing the runtime configuration will automatically trigger a re-run of the deployment, which will upgrade the endpoint with no downtime.
To configure a new live deployment, select Create deployment, select Live under Deployment type, then input a replica count and resource configuration.
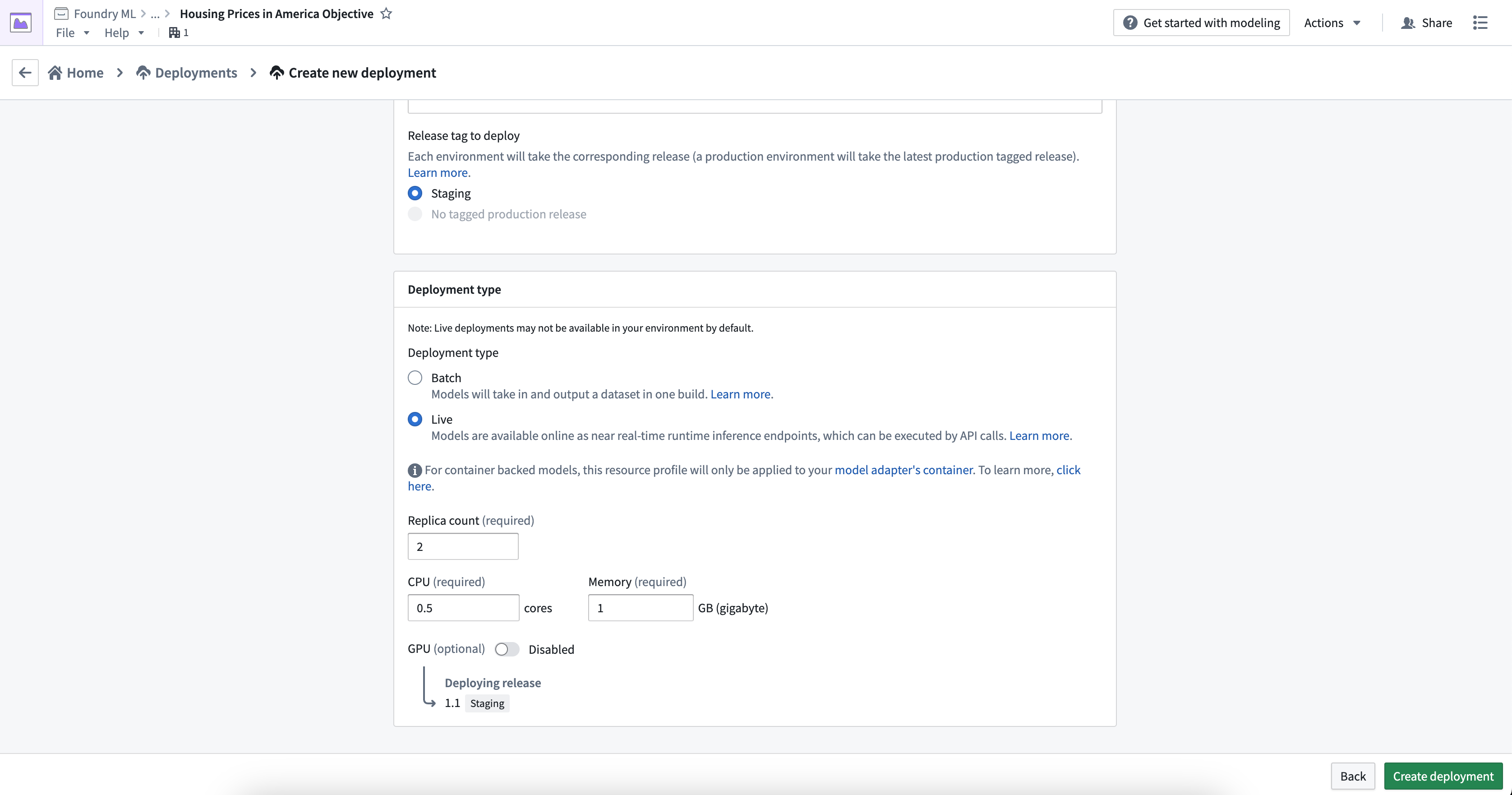
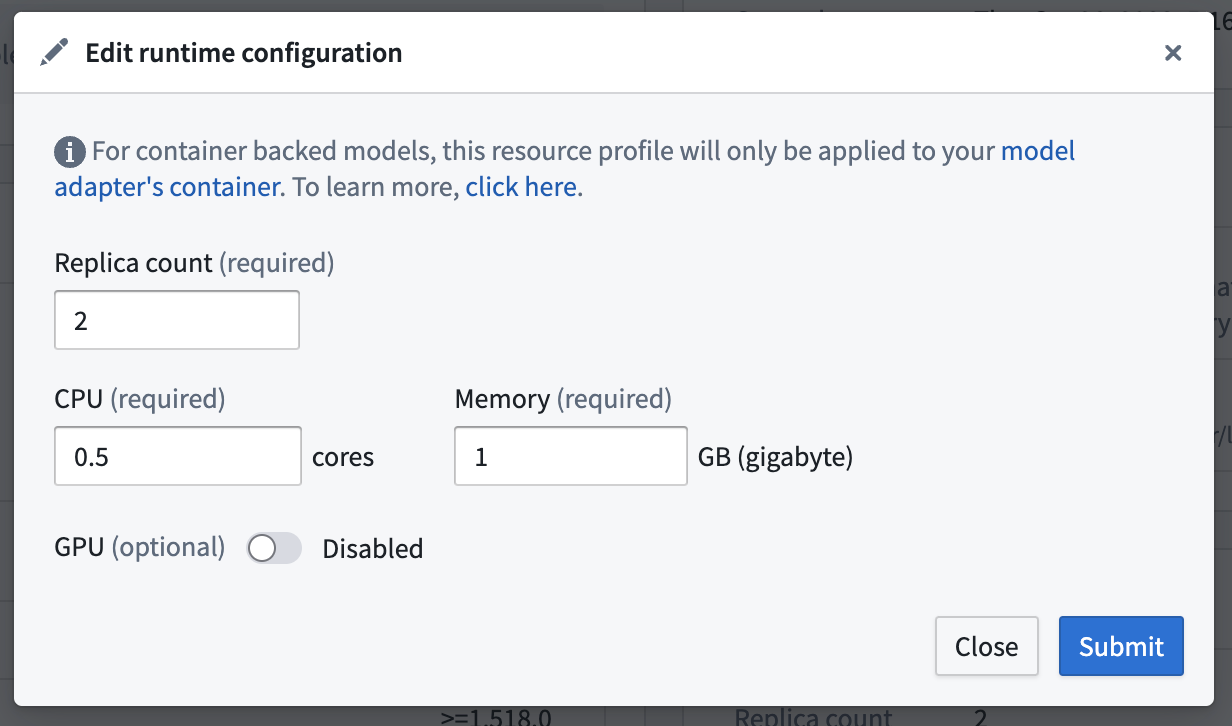
To edit the configured replica and resources, navigate to the Deployments section in your modeling project, choose your deployment from the listed deployments, and select the edit button under Runtime configuration to edit the replica or resource configuration.
View deployment service logs
A series of logs that describe the deployment's startup progress are emitted from each live deployment; these logs include the URIs of the Conda packages in the release environment that the deployment will attempt to download and install, as well as details around downloading the model itself. In the event that a deployment fails to start successfully, there may be a relevant warning or error level log that can help you understand what happened.
To view service logs directly from the running live deployment, navigate to the Logs & Metrics tab on the deployment details page. You can specify a time window to search within, filter logs by any of the fields, and add or remove columns from the view. You can also download all logs as a text file using the download button in the top right corner.
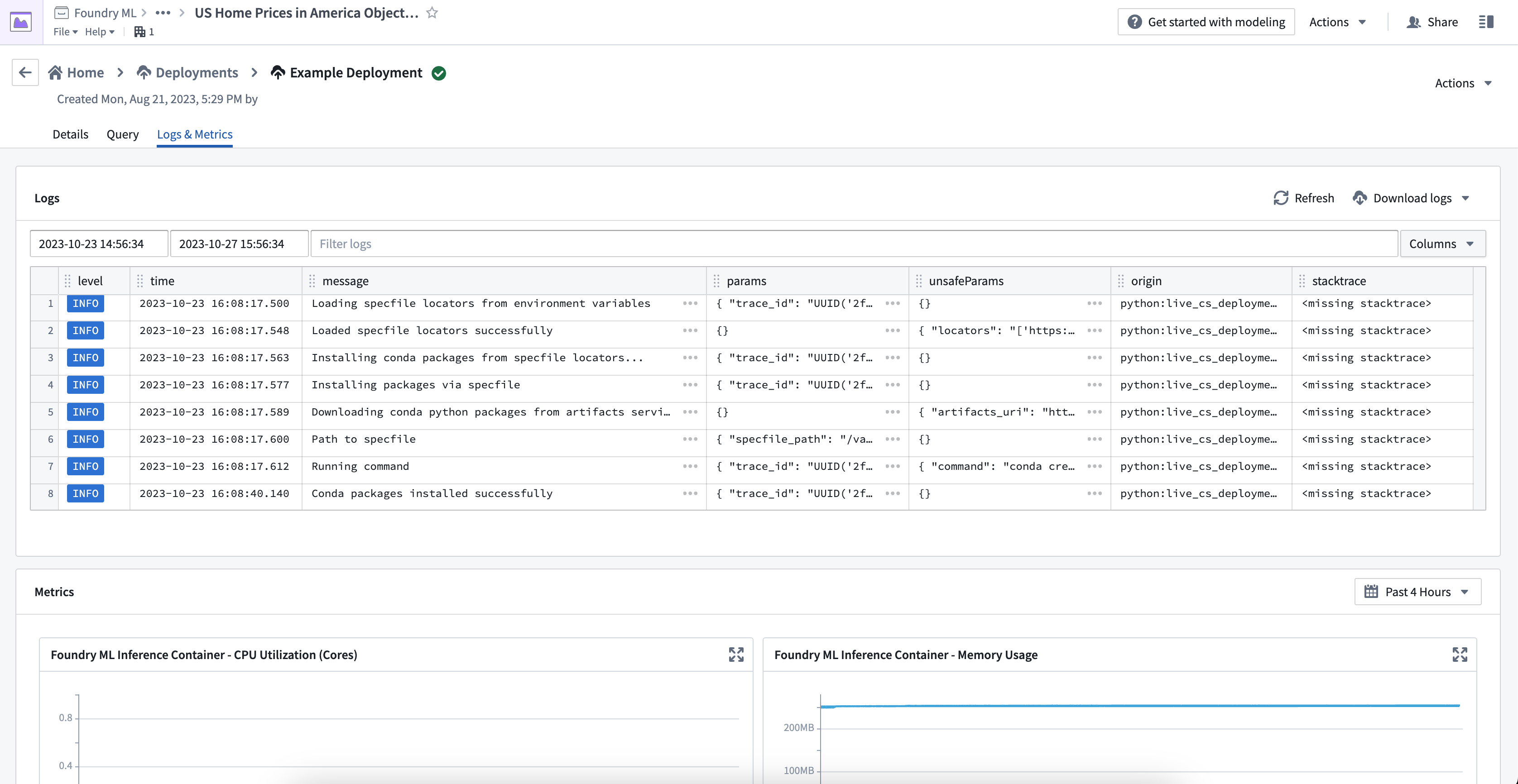
Because you may have configured your deployment to run with multiple replicas, you may see seemingly duplicated logs - each set coming from a different replica. However, each log includes a tag with a unique node_id which you can use to filter by replica if needed. You can use the following notation for this:
Copied!1tags.node_id:{Insert UUID here}
To emit logs directly from your model, you can use the standard python logging module. Live deployments will make each log line available to be queried from within the Logs & Metrics tab.
Copied!1 2 3 4import logging log = logging.getLogger('model-logger') log.info("Emitting info directly from the model")
To emit logs from a container-backed model, enable telemetry when configuring a model version.
Logs from your live deployment have a retention period of 7 days, after which time they will be unavailable to either view or download.
View deployment metrics
The Logs & Metrics tab provides two types of metrics: Kubernetes host and inference container. Be sure to understand the difference between these metric types to properly monitor and debug your models.
Kubernetes host metrics
Kubernetes host metrics show the percentage of memory and CPU usage used by all processes running on the host, not just the processes related to a specific model. These metrics are important for debugging issues related to scheduling and resource throttling. For instance, if your model's performance is slow but the host metrics are at 100%, your model might be getting throttled by the Kubernetes host.
Inference container metrics
Inference container metrics are helpful for debugging resource usage in Python models and model adapter logic. These metrics provide the exact memory usage and CPU core usage of the inference container, independent of the entire Kubernetes host. Currently, usage metrics are not available for container-based models.
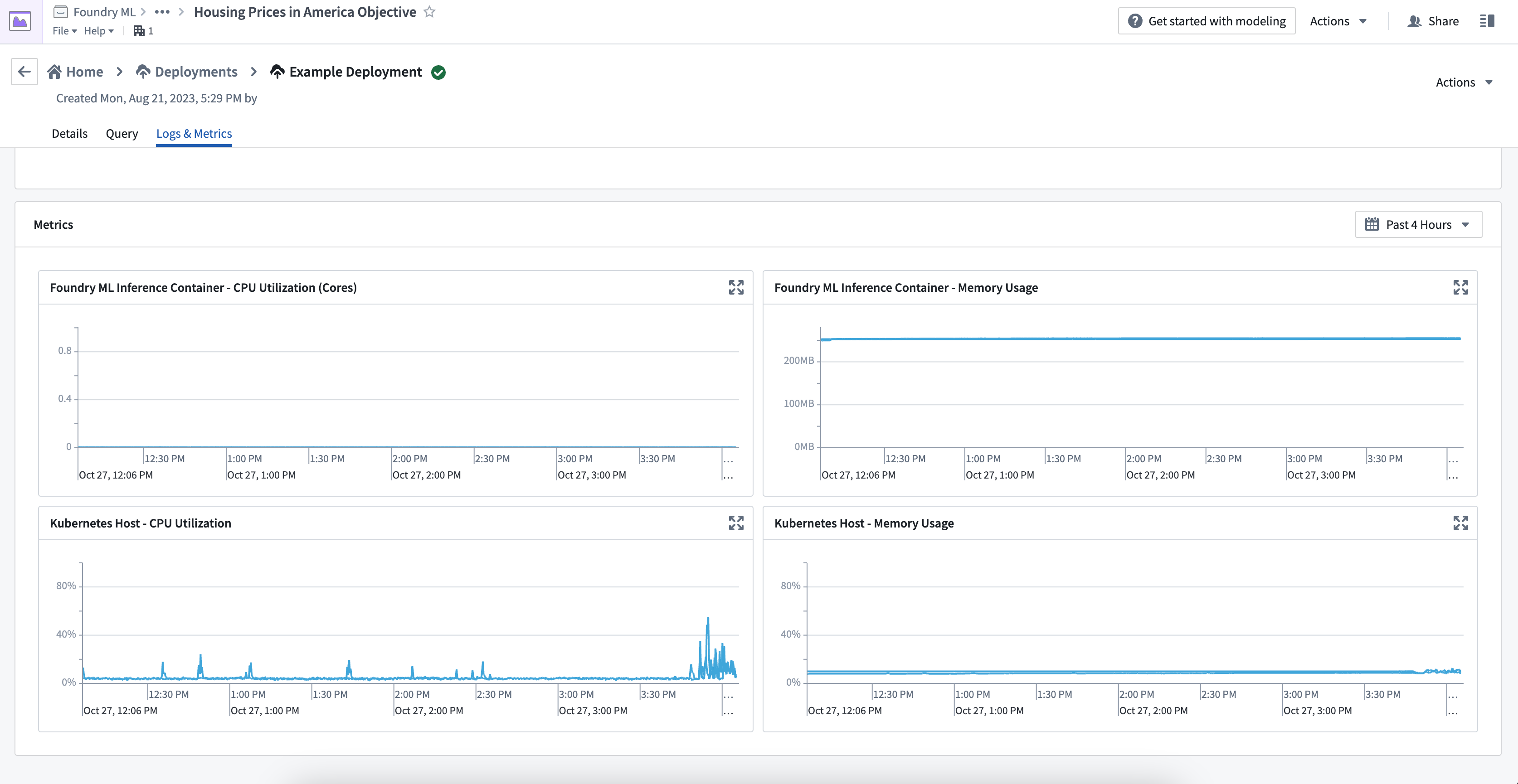
If you can only view the Kubernates host metrics and not the inference container metrics, your container may be running on an outdated version of live deployments. Restart your live deployment to update the version and view all metrics.
Spark model support
Supported Spark versions are subject to change in upcoming releases and back-compatibility is not guaranteed. If your model is not compatible with the current Spark version, you may need to rebuild it.
All live deployments are now initialized with both a JDK and a Spark distribution installed. This allows Spark models to be compatible with live deployments. In this interactive environment, only local Spark is supported, meaning all processing is done within a single JVM.
If your model expects a Spark DataFrame input, data conversion issues are more likely to occur since the requests are sent as JSON. When developing a custom model which expects Spark dataframes, you should perform this conversion manually either in a pre-processing stage or directly in the transform function. A simple example of this is below:
Copied!1 2 3 4 5 6 7import pandas as pd from pyspark.sql import SparkSession def _transform(model, df): if isinstance(df, pd.DataFrame): df = SparkSession.builder.getOrCreate().createDataFrame(df) return model.predict_spark_df(df)