Mini Project - Your Data Engineering Challenge!
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
You are working for a manufacturing company called Odyssey. Odyssey has different manufacturing plants around the world that produce electronics units. Due to global supply chain disruptions and sudden changes in demand, it has become important for the company to understand how well-equipped they are at delivering electronics units to their clients at any given moment. In other words, they want to understand their readiness.
Context
Odyssey uses the terms Units, Parts, Assemblies, and Components to describe their production:
- A Plant is the manufacturing site where electronics units are produced.
- A Unit is a physical object at the Plant - it can either be a
- Component which is bought from a supplier, or an
- Assembly, which consists of Components, is produced at the Plant, and delivered to clients via Orders.
- A Part is the type of the unit. For example, a part could be the class of all 23-inch bolts, whereas a unit corresponds to one specific real-world 23-inch bolt. A part is either an assembly part or a component part.
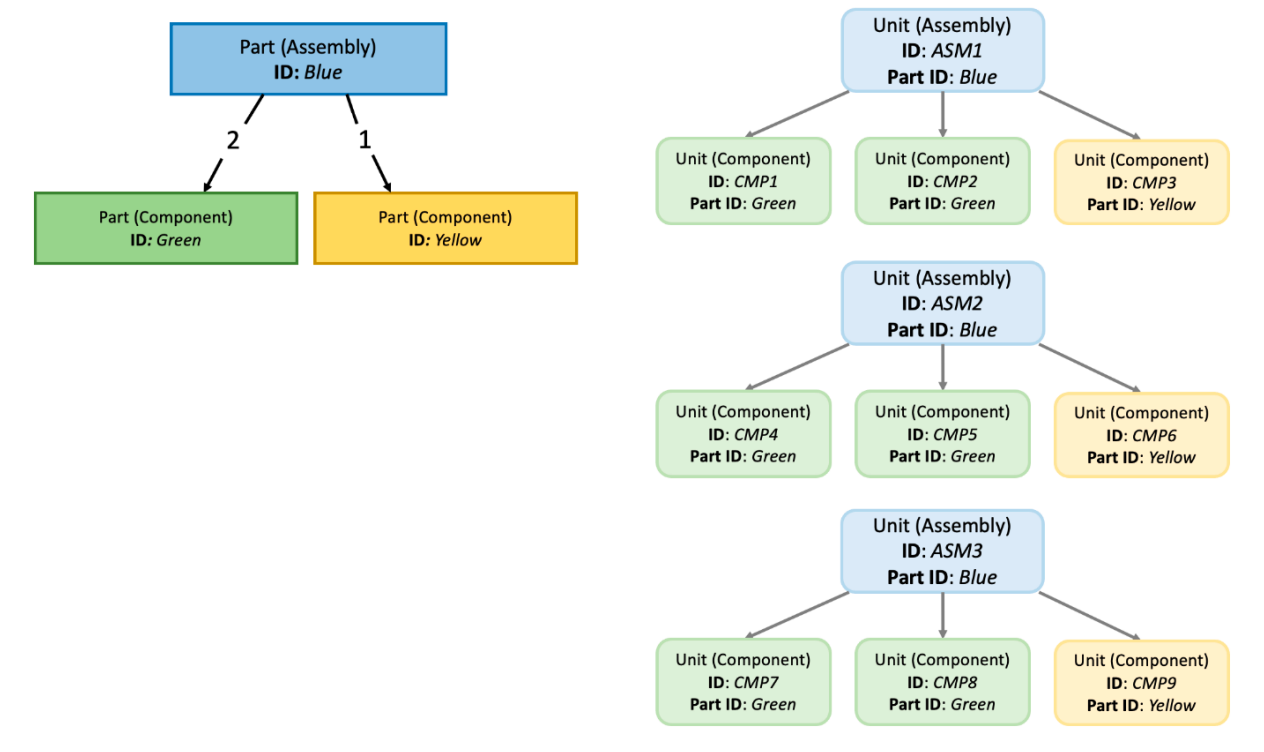
The diagram below illustrates the relationships. Part Blue is an assembly part consisting of 2 components parts Green and 1 component part Yellow. You can think of the part as a blueprint for the units. On the right-hand side, you are shown 3 assembly units of part Blue. Each of them consist of 3 component units; 2 of part Green and 1 of part Yellow.
Use Case: Plant Readiness
To determine a plant’s readiness, the plant manager wants a simple workflow where they can input two targets: Low Target and High Target. These numbers specify, respectively, the minimum number and the preferred number of Assembly units the plant should be able to deliver for each part. The Readiness Count of a given part from a given plant is the number of units of that part type that can currently be delivered. For Component units, it’s the available unit count. For Assemblies, it must be calculated based on the sum of:
- Available Unit Count: Existing units at the plant that are not already in use.
- Buildable Unit Count: The number of assembly units that could be produced from existing available component units at the plant
The Readiness Status of the part is determined by the Readiness Count based on the targets:
- Below Target - if the readiness count does not hit any of the targets
- At Low Target - if the readiness count hits the low target, but not the high target
- At High Target - if the readiness count hits the high target
Based on the two input targets, the manager would like to see the readiness status of each part for the plant.
Workflow
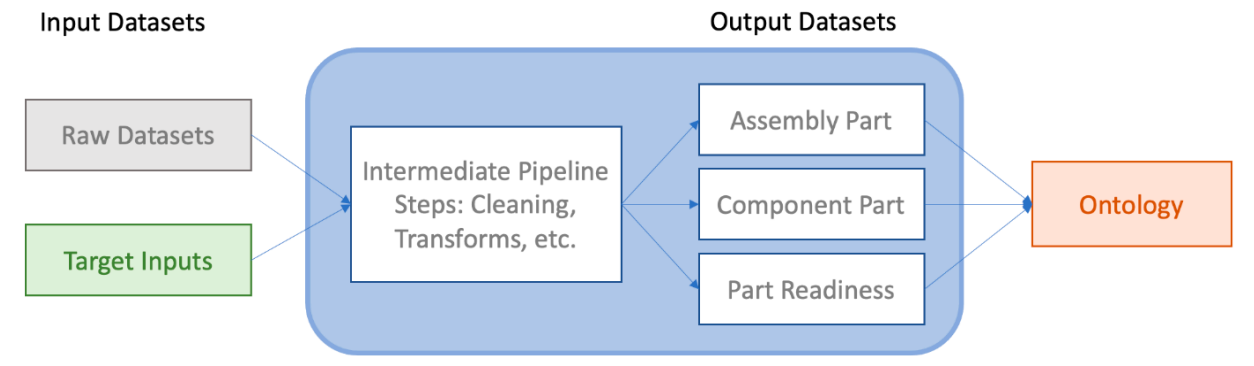
Your task is to build a pipeline which calculates the readiness count and readiness status of each part based on the input targets. The circled part of the below diagram represents the main deliverables of the project.
Data
The following raw datasets are available from Odyssey’s source systems: Part, PartInventory, PartMapping, Plant. You will have to explore the data to understand how it fits together, but the following info might be useful:
- You can ignore parts that are neither specified as Assembly nor Component.
- The PartMapping dataset maps Assembly parts (parent_part_id) to their constituent Component parts (child_part_id), and how many of each type (child_part_count).
- The PartInventory dataset shows the available unit count of each part (such as Assembly units that are not attached to an order and Component units that are not already built into an Assembly unit). If a part is not in this dataset, it means the available unit count is 0.
Input
The pipeline should take as input:
- Raw datasets from Odyssey's source systems
- Manual input for readiness targets specified by Plant Managers in Pipeline Builder
To allow Plant Managers input data manually, refer to the manual data entry functionality in Pipeline Builder. Your manual entry table should consist of the following 3 columns:
- plant_id (string, primary key)
- low_target (long)
- high_target (long)
To test your implementation, fill in the first row of your manual entry table with initial values:
- plant_id: "1234"
- low_target: 10
- high_target: 50
Your table should look like the example below:

Output
The pipeline should output datasets that can back Ontology object types. Each dataset must include columns that can be the object types’ Primary Key (PK) and Title properties. The 3 object types you must support are:
- Assembly Part: This object type represents an Assembly part.
- Component Part: This object type represents a Component part.
- Part Readiness: This object type represents the readiness information for each Part (Assembly or Component) for each Plant, i.e., there should be one row per part per plant. Aside from PK and Title, your dataset must include columns that can back the following Ontology properties:
- Readiness Status: ‘Below Target’, ‘At Low Target’, or ‘At High Target’ for Assembly parts (null for Components).
- Readiness Count: Number of deliverable units (Assemblies) or available unit count (Components).
- Buildable Unit Count: Number of Assembly units that could be built based on existing available component units (null for Components).
- Available Unit Count.
The datasets need to be linkable as objects. Your output must enable such a link, either with a 1-1 foreign key, a 1-many foreign key, or a many-many join dataset, depending on the relationship between the datasets.
Readiness Count Example
Let’s look at the part ABC-720-CB050940:
-
One unit is built from 2 units of part ABC-000064 REV 00C-x and 1 unit of part ABC-000080 Rev 00A-x.
-
The available unit counts of each involved part are:
- ABC-720-CB050940 (Assembly): 9
- ABC-000064 REV 00C-x (Component, need 2x): 3686
- ABC-000080 Rev 00A-x (Component, need 1x): 813
-
The most units of part ABC-720-CB050940 that can be built from existing components is 813, as we’re limited by the number of ABC-000080 Rev 00A-x units. The readiness count for ABC-720-CB050940 is therefore 9 + 813 = 822 units.
-
If the low target is 10 and the high target is 50, this part would have readiness status At High Target.