2 - Previewing data in Data Lineage
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
The Data Lineage application allows you to zoom out to view an entire data pipeline. In this task, you will see how the passengers_clean table was derived and explore its "ancestors". Each line (arrow) represents a data transformation that could be a cleaning step, a step combining information from multiple tables into a single more comprehensive dataset, or a step adding new derived columns to a table.
🔨 Task Instructions
-
Zoom out to view the entire data pipeline. You'll see a purple node at the far left called source/passengers_json_raw and a yellow node to its left called raw/passengers_json_raw. Each represent raw json that was brought into Foundry and isn't yet tabular data.
-
Click on the node titled
passengers_preprocessedon the graph. This is tabular data derived from transforms on those raw json datasets. We can explore its contents in just a few clicks. -
Click on the Preview tab located on the bottom of the graph. The Preview tab shows a snapshot of the selected dataset in a tabular format, previewing the first 300 rows in the table. Preview is useful for spot-checking your data to make sure it looks as you expect.
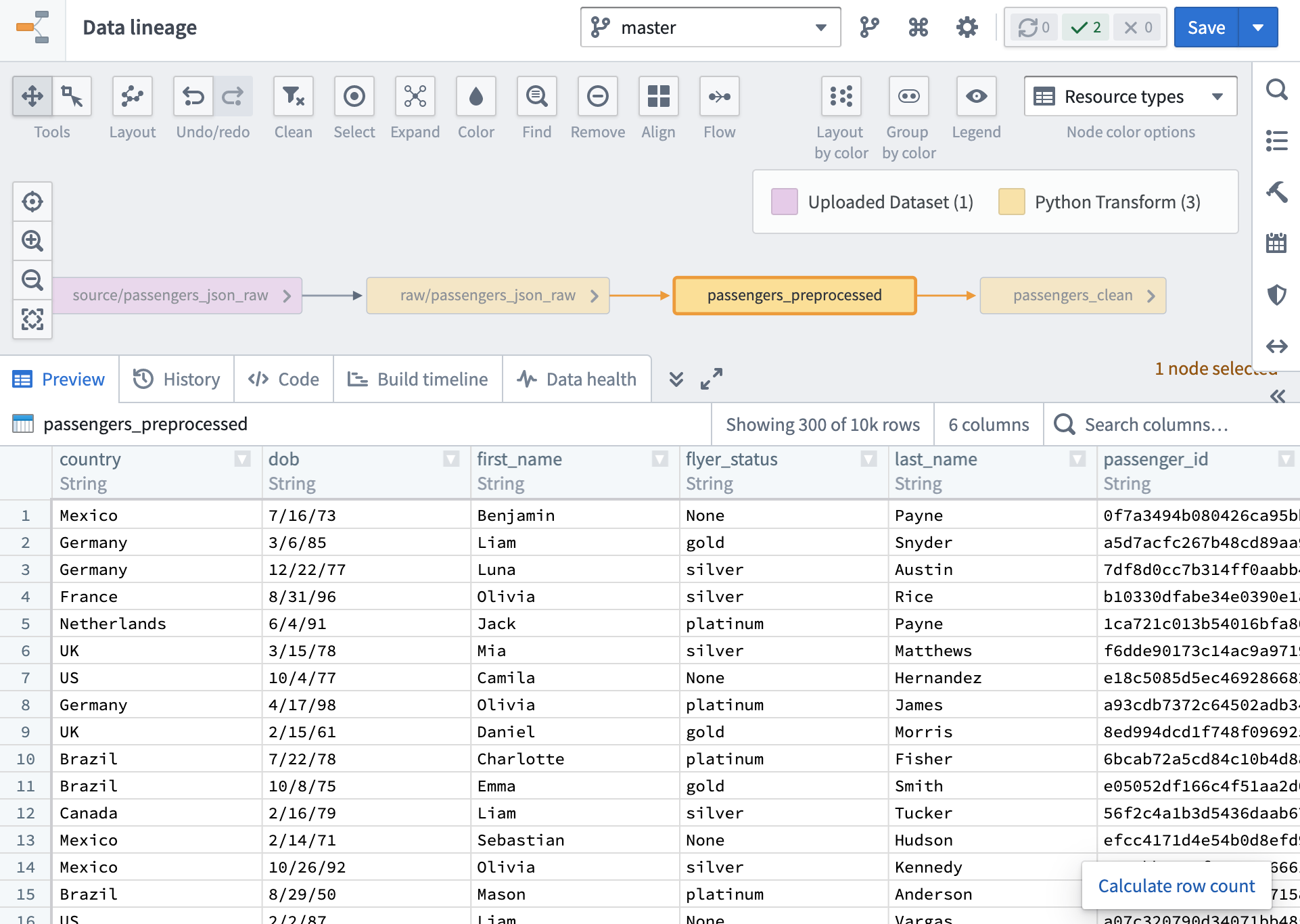
Note: The name data in this dataset is notional.