29 - Additive Backing Dataset Changes: Part 1
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
In this exercise, you'll practice addressing two primary scenarios involving changes to backing datasets and Ontology configurations.
- Additive changes to your backing dataset.
- Destructive changes to your backing dataset.
The title key for your passenger object type is simply the last name of the passenger. Let's create a new column in the backing dataset called full_name that we can swap in for the title key. In so doing, we'll witness what happens in the Ontology sync process when the backing dataset receives a new column.
🔨 Task Instructions
-
Open your
ontology_flight_alerts_logicrepository to yourpassengers.pytransform file.- ⚠️ *You'll typically want to branch from
masterwhen making changes like this, but for convenience, you'll be making your changes directly tomaster.
- ⚠️ *You'll typically want to branch from
-
Uncomment line 1 so that you can import pyspark.sql functions.
-
Update the return statement to the following:
return source_df.withColumn('full_name', F.concat(source_df.first_name, F.lit(' '), source_df.last_name)) -
Preview, commit, and build your code using best practices.
-
Once your dataset build completes, open the output
passengersdataset and proceed to the Syncs section of the Details tab as shown in the image below. Here, we can see that the sync between the dataset and the object storage service (aka "Phonograph") was successful despite the schema change.
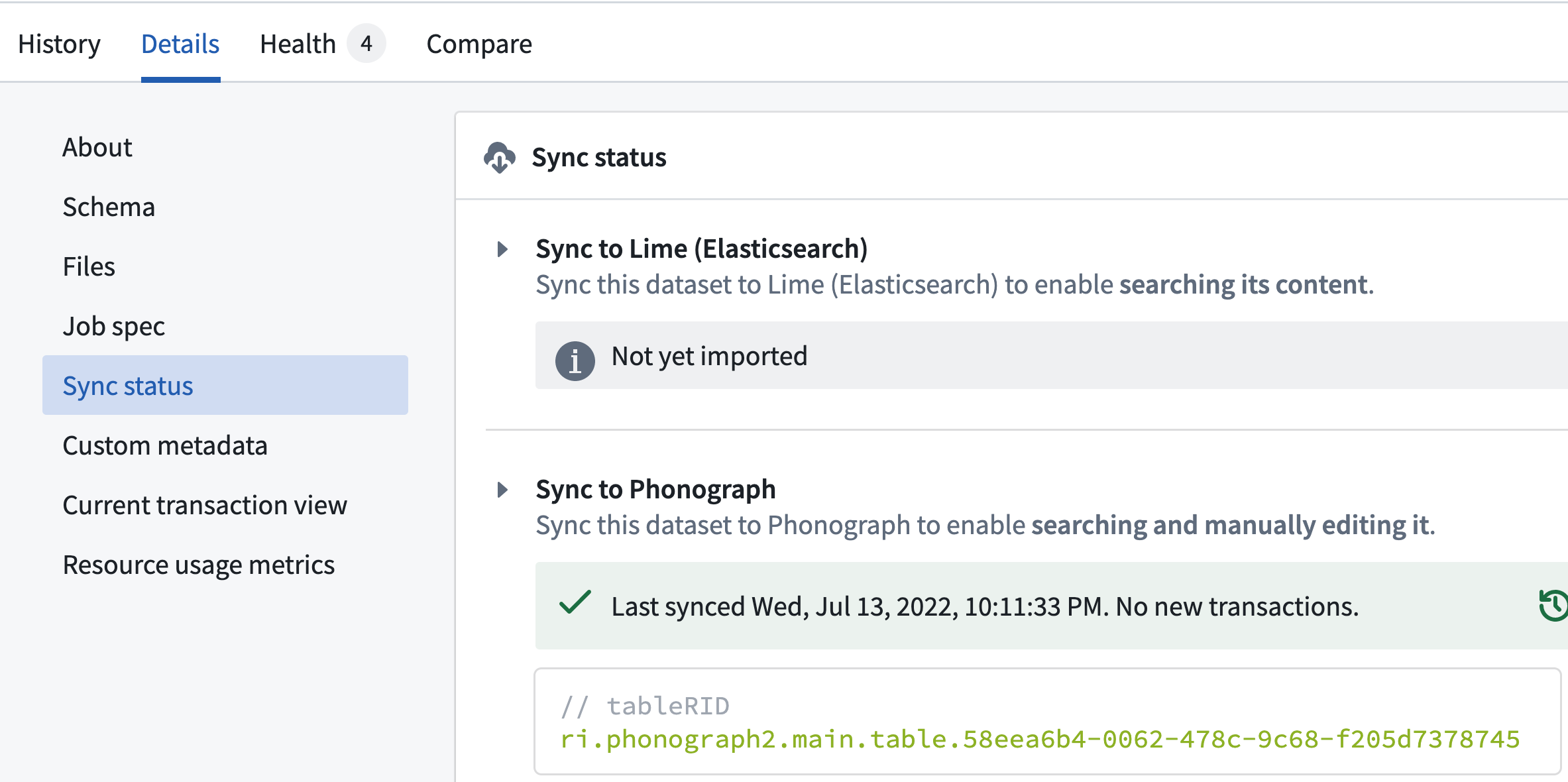
- While you're here, you could also access the Health tab and see that the Schema Check you put in place earlier passed. Because we set the check to
COLUMN_ADDITIONS_ALLOWED_STRICT, the check added the new column.