13 - Exercise Summary
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
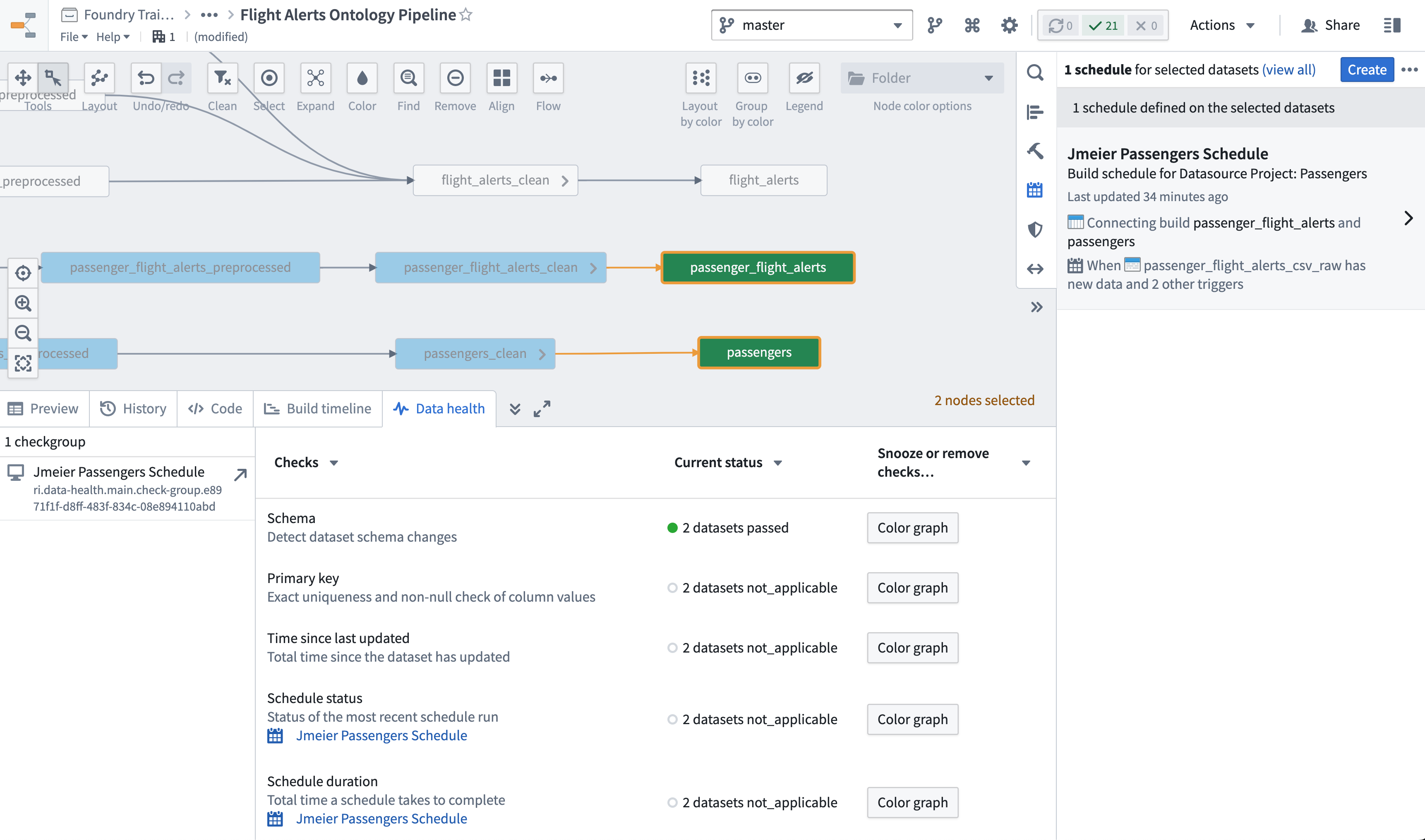
✅ What you built
- An
Ontology Project: Flight Alertsproject (a "folder" in this case) composed of recommended folders and artifacts. - An
ontology_flight_alerts_logicrepository that applies final transform steps to prepare your three datasets for synchronization to the Ontology. - Updated flight alert and passengers schedules that now treat your Ontology datasets as the build targets.
- Updated health checks on the new schedule targets.
✅ What you learned
- You can consult the documentation to ramp up on functional Solution Design in Foundry.
- Schema recommendations for Ontology datasets are available in the Foundry documentation.
- You should consider these code development best practices (not just Ontology ones).
- Object types are backed by a single dataset, and a dataset can back only one object type.
- Many-to-Many link types in the Ontology must be backed by a join table.
- Datasets that will be used to back Ontology object and link types should be output by a code repository into an Ontology Project.
- You should always have an intermediate transform step from
cleantoontologydatasets, even if it seems like an unnecessary formality.