9 - Checking your Backing Datasets
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
We want to create and link two object types—flight alerts and passengers—with the eventual goal of creating an alert inbox application that enables an analyst to take action, potentially including reaching out to affected passengers. With that end in mind, let's review your data pipelines, checking them against best practices and determining whether there's anything we can do to further prepare our flight alerts and passengers datasets to back Ontology object types.
🔨 Task Instructions
- Proceed to your personal
/Temporary Training Artifacts/${yourName}folder. - Right click on the
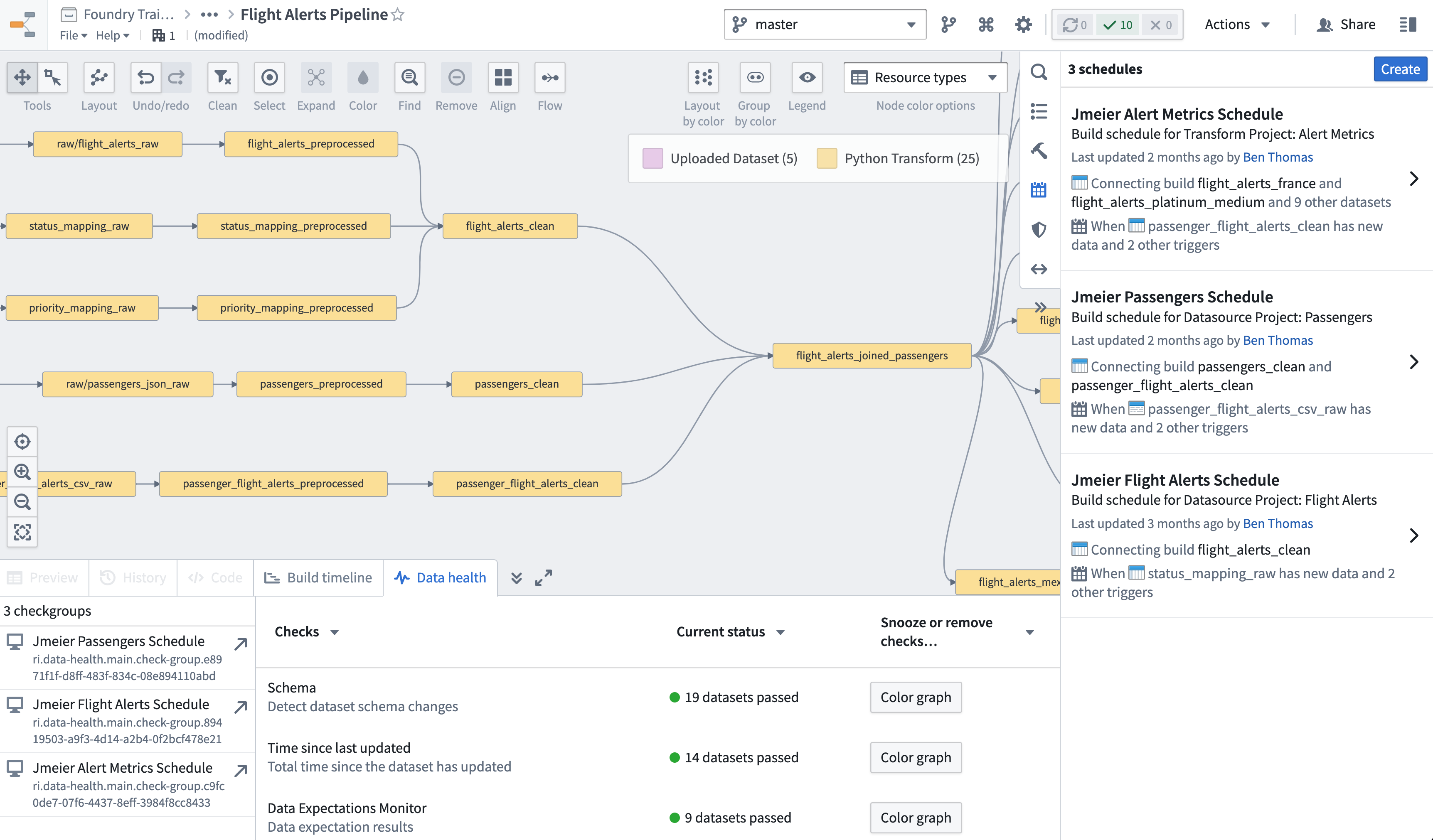
/Data Engineering Tutorialsfolder and choose Explore data lineage from the fly-out menu. - Consider opening the Data Health helper tab across the bottom and the Schedules panel on the right of the screen as shown in the clickable image below.
In this pipeline you have three candidate datasets for creating Ontology objects in light of our desired outcomes:
passengers_cleanflight_alerts_cleanflight_alerts_joined_passengers
Recall in our earlier discussion of Ontology design we explored criteria for modeling data as properties or as object types. Should flight alerts include aggregated passenger data (which would be the case if we use flight_alerts_joined_passengers), or should we access passenger data from flight alerts via a configured Ontology link type?
We might consider combining alert and passenger information if the data is a single piece of information rather than an aggregate. In this case, because there is a one-to-many relationship between alerts and passengers, the passenger data would be aggregated per alert. Passenger data is also not primarily supporting information about a flight alert. Conceptually, passengers and flight alerts are very distinct entities and have very different search semantics and use cases.
For these reasons, let's model them as separate object types connected via a link made possible by a shared key between the backing datasets.