12 - Documenting and Updating Your Pipeline
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
Why didn't we just use the clean versions of the untouched datasets as inputs to the Ontology?
Clean datasets tend to be starting points for many activities in Foundry, including analysis, modeling, and other data pipelines. They typically resemble raw data closely and as such may contain many more columns than we need for our Ontology object and link types but that are nonetheless valuable for these other workflows. We may also eventually decide to add new derived columns to our Ontology-backing dataset, and we may want to make those changes without affecting the clean version. This intermediate transform step ( clean → ontology) is always recommended, even in cases where it initially feels like a formality.
You've now added transformation steps in your pipeline that should be documented, scheduled, and monitored per the practices you've learned in this training track. Test your knowledge by following these summary recommendations.
🔨 Task Instructions
-
Once your pipeline deploys, click the View Lineage button at the top of the Pipeline outputs panel in Pipeline Builder.
-
Expand the datasets to show all ancestor nodes and arrange them logically (hint: try selecting all nodes and clicking ctrl+l).
-
Save this Data Lineage graph in
/Ontology Project: Flight Alerts/documentation/as "Flight Alerts Pipeline (Full)."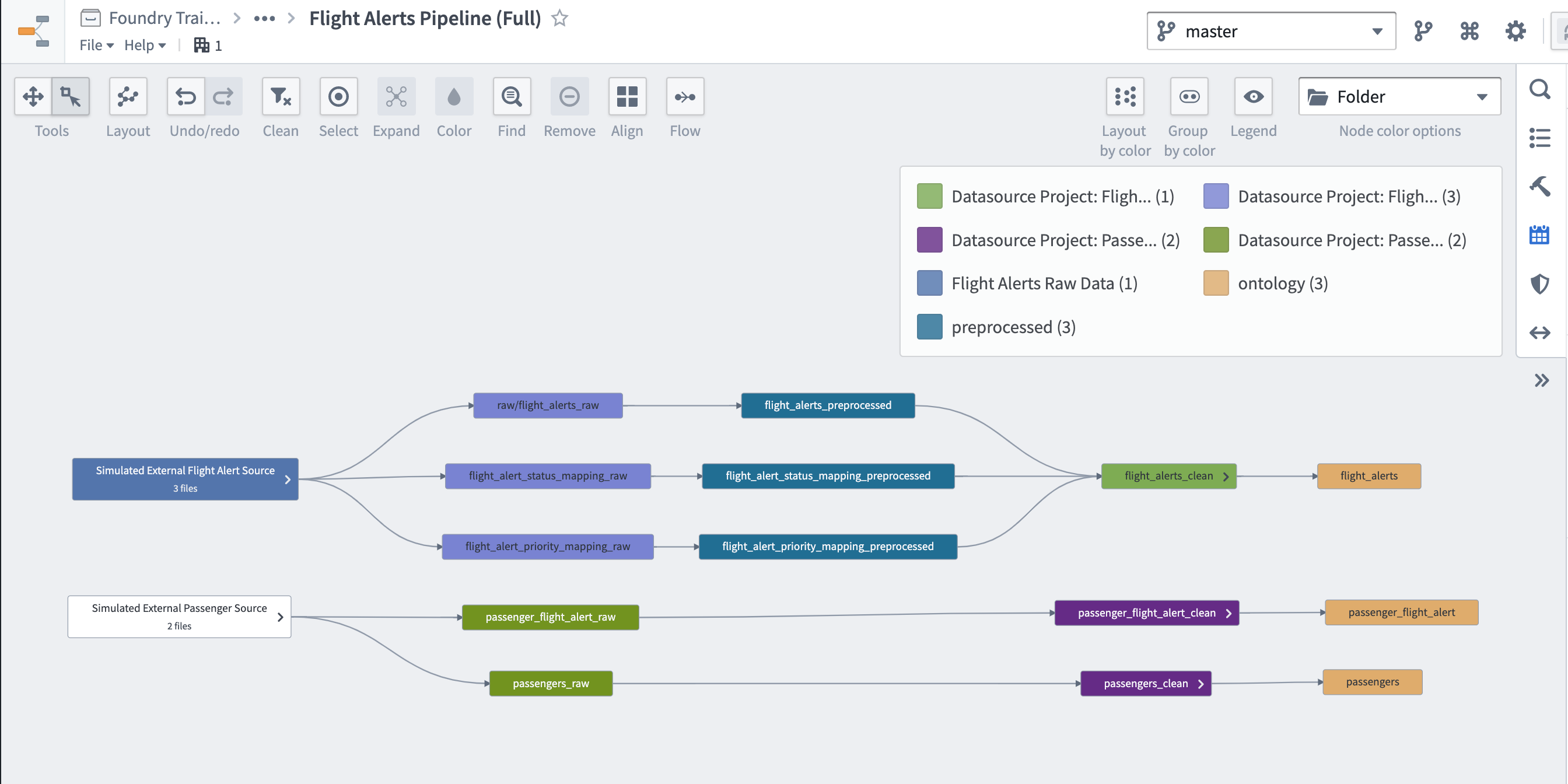
-
Add a Notepad document in your
/documentationfolder that mirrors the structure of those created for your other repositories. Consider adding ownership information and a description, possibly pulled from the Task Introduction of the previous tutorial "Creating a Project Output" section "Add Written Pipeline Documentation". -
In the Data Lineage graph, open the Schedules helper and edit your Flight Alerts and Passengers schedules so that the targets are your new ontology datasets rather than the previously configured clean ones.
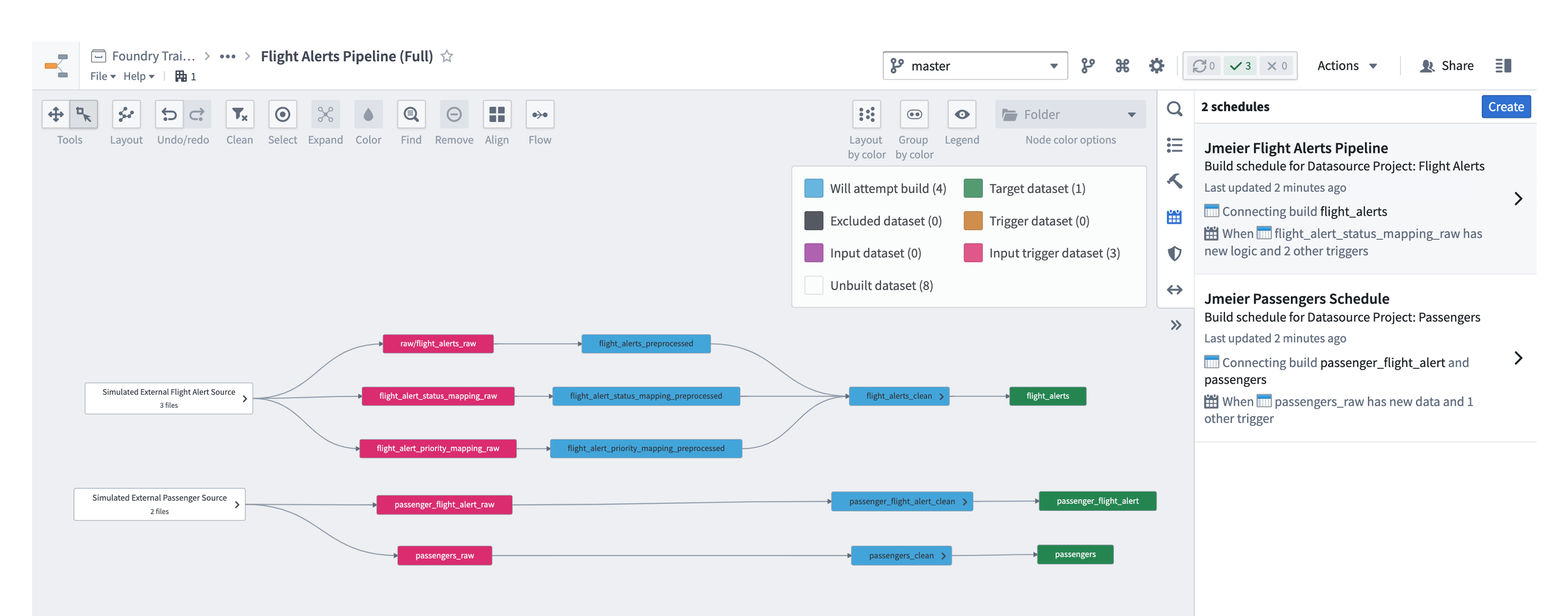
-
Apply the following health checks to each of your three new ontology datasets and add them to the associated check groups:
- Schema Check (
COLUMN_ADDITIONS_ALLOWED_ STRICT). - Primary Key (severity = critical). For the
flight_alerts_passenger, configure the check to verify the combination ofalert_display_nameandpassenger_id. - Time Since Last Updated (1 deviation > the median)
- Schema Check (
We'll return to add a final check after configuring the object and link types in the Ontology. Note that all of these new datasets are automatically added to the existing Schedule Status and Schedule Duration checks.