8 - Ontology Datasource Preparation Guidance
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
In the next several tasks, you'll create basic object and link types in Foundry's Ontology Management Application (OMA). An object type is backed by a Foundry dataset that is usually the target (i.e., output) of a scheduled, well-maintained build like the ones you've generated in this training track.
First, we'll review the best practices for constructing datasets to back Ontology object types and highlight some ways your pipeline already implements these.
Let's start by reviewing guidance on optimal schemas for backing datasets. Take 3-4 minutes to review this documentation and consider bookmarking it if your job will frequently include preparing and synchronizing data to the Foundry Ontology. Adhering to the suggested data types and naming patterns will help improve performance and consistency across your Ontology.
Next, let's double back to code development best practices that affect the way our pipelines run and, consequently, the maintainability of an Ontology. On this documentation page (an ~8 minute read), you'll review general recommendations for code and pipeline hygiene.
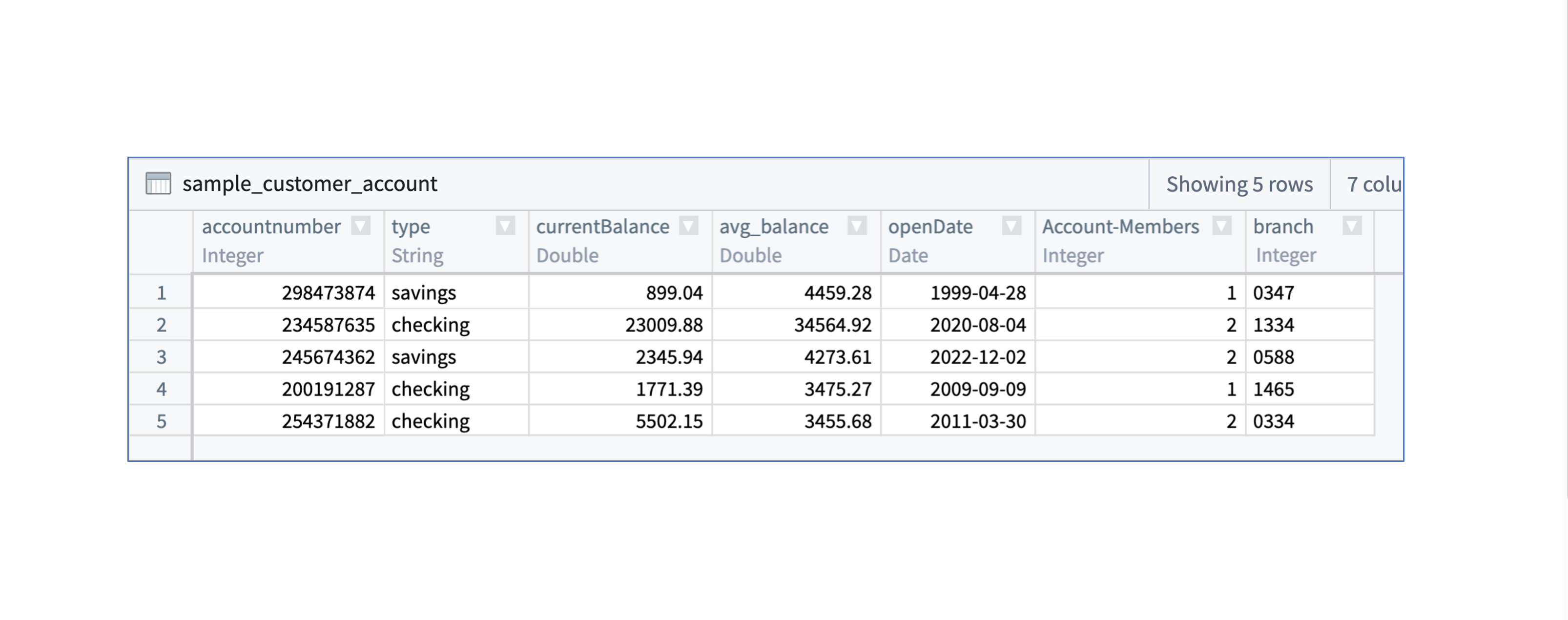
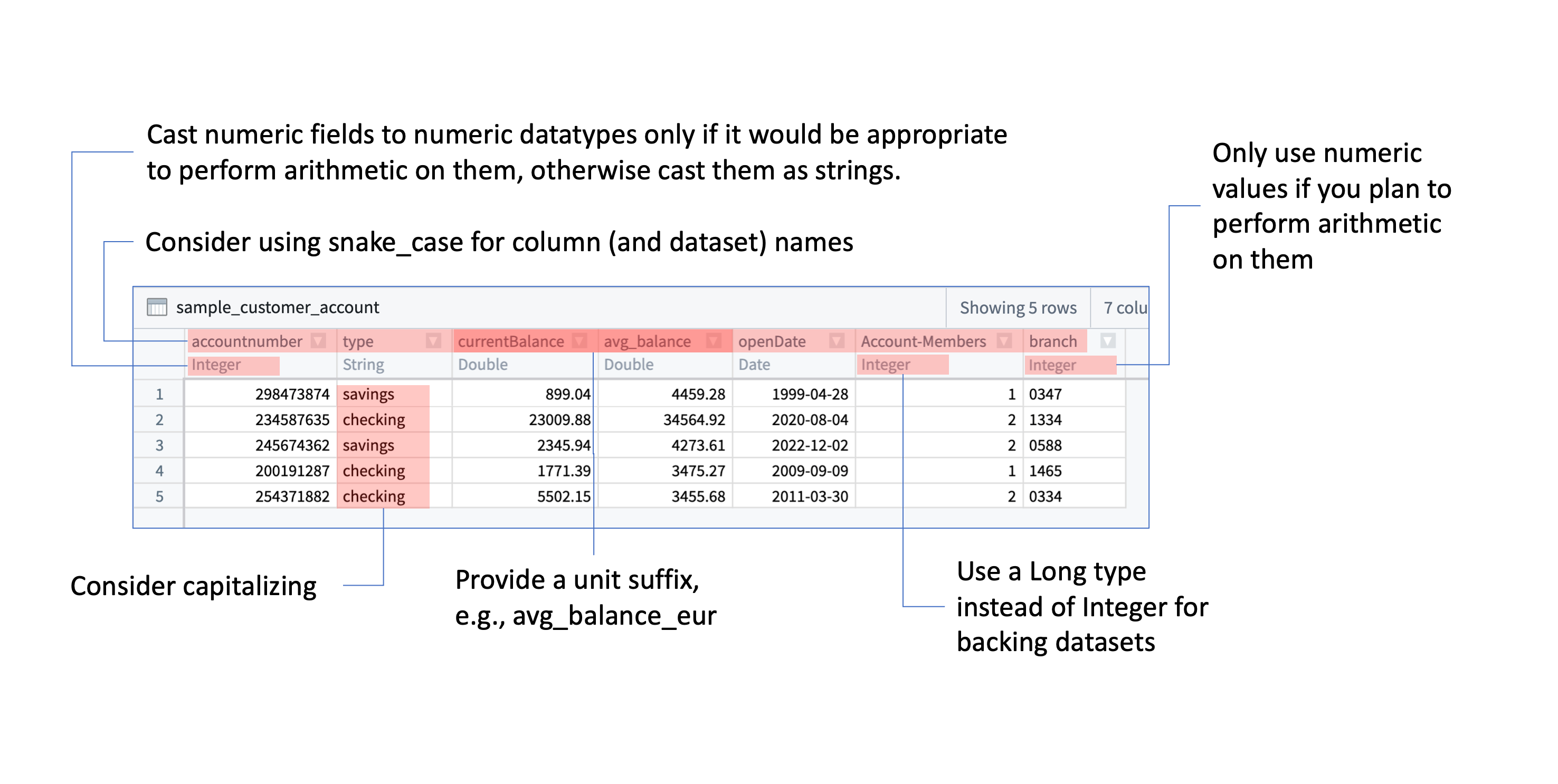
Having reviewed these recommendations, can you think of at least three suggestions for better preparing the following dataset to back an Ontology object type?
Finally, before embarking on an Ontology development project, you should also know:
- The workflow you aim to achieve with your object types and links and the data architecture required.
- In Object Storage V1 (OSv1), object types are backed by a single dataset, and a dataset can back only one object type. In Object Storage V2 (OSv2), you can have multiple object types backed by a single dataset.
- Cleaning and formatting should be done upstream in data transformations where possible rather than in OMA or Ontology aware applications.
- Primary keys should always be unique, but it's especially crucial for Ontology backing datasets.
- If a backing dataset schema changes, you may need to take action to ensure your object and link types are not negatively affected (more on this later).