1 - About this Course
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
The Foundry Ontology is a “digital twin” of entities, events, and processes that are important to an organization. This semantic object layer provides a consistent API that you and your colleagues can use to build operational and interoperable applications. In the Data Lineage image below, we see the [Example Data] Flight object type in the Foundry Ontology is used in at least two operational applications (labeled as “modules” in Data Lineage) and links to a few other object types, such as aircraft and flight alerts.
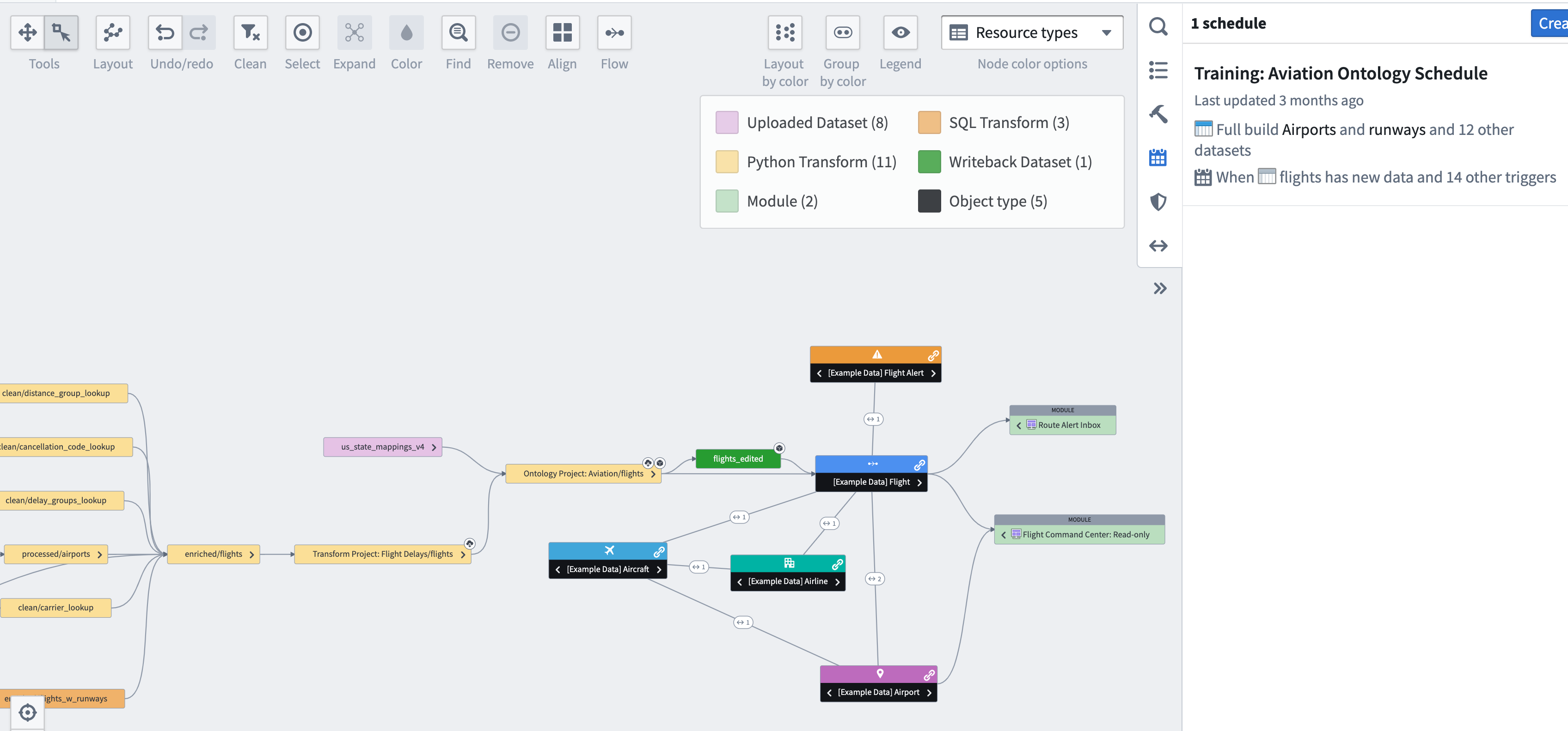
The graph also illustrates that the [Example Data] Flight object type is “backed” by a dataset, which is the output of a scheduled build. This flow illustrates the central theme in this tutorial: data engineers must work closely with their app builder colleagues to craft pipelines and datasets that form the basis for Foundry Ontology objects and links.
⚠️ Course prerequisites
- DATAENG 07: Configuring Data Expectations: If you have not completed the previous course in this track, do so now.
- Necessary permissions to edit your organization’s Ontology. Contact you program administrator or Palantir Support if you need authorization.
Outcomes
Data pipelines are not isolated artifacts; they’re always built for some purpose. In this training, the purpose of our pipeline is to prepare datasets to back a set of linked Ontology object types. You’ll have hands-on practice configuring the Ontology and updating a pipeline to optimize the backing datasets and make them resilient to upstream data changes that would alter the shape of your Ontology. Finally, a collection of exercises will walk you through common troubleshooting steps.
Learning Objectives
- Understand core Ontology concepts, basic use cases, and design decisions.
- Search and filter object types in the Object Explorer.
- Know how to create new object and link types in the Ontology Manager.
- Optimize backing datasets for use in the Ontology in accordance with best practices.
- Apply checks to your pipeline to ensure object types are resilient to upstream data changes.
- Understand the Ontology storage and retrieval architecture.
- Develop an experience-based understanding of "writeback" and its place in a data pipeline.
- Practice troubleshooting common Ontology synchronization issues.
💪 Foundry Skills
- Use the Object Explorer to search, filter, and generally understand the Ontology.
- Use the Ontology Manager to create and edit ontology object and link types.
- Update pipeline transforms to optimize a backing dataset for synchronization with the Ontology backend.
- Create "writeback" datasets and position them in your data pipeline.
- Accommodate additive and destructive schema changes via the object storage interface in the Ontology Management Application.