6 - Practice: Implement Data Expectations in your Pipeline
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
More health checks—expectations or otherwise—doesn’t necessarily mean more health. Consider setting these at key points in your pipeline rather than everywhere. For example, start by setting checks on the inputs and outputs of your (scheduled) build.
Using what you’ve learned in the Monitoring Data Pipeline Health tutorial and this tutorial, configure data expectations on key input and output nodes of your scheduled build. There is no strict “correct” answer to this prompt. Here are some ideas to get you started:
-
Primary key checks on the “raw” datasets in your pipeline.
-
Value validation checks on the
flyer_statuscolumn of yourpassengers_cleandataset. -
A row count check (≤ 3) on your
flight_alert_priority_mapping_rawdataset. -
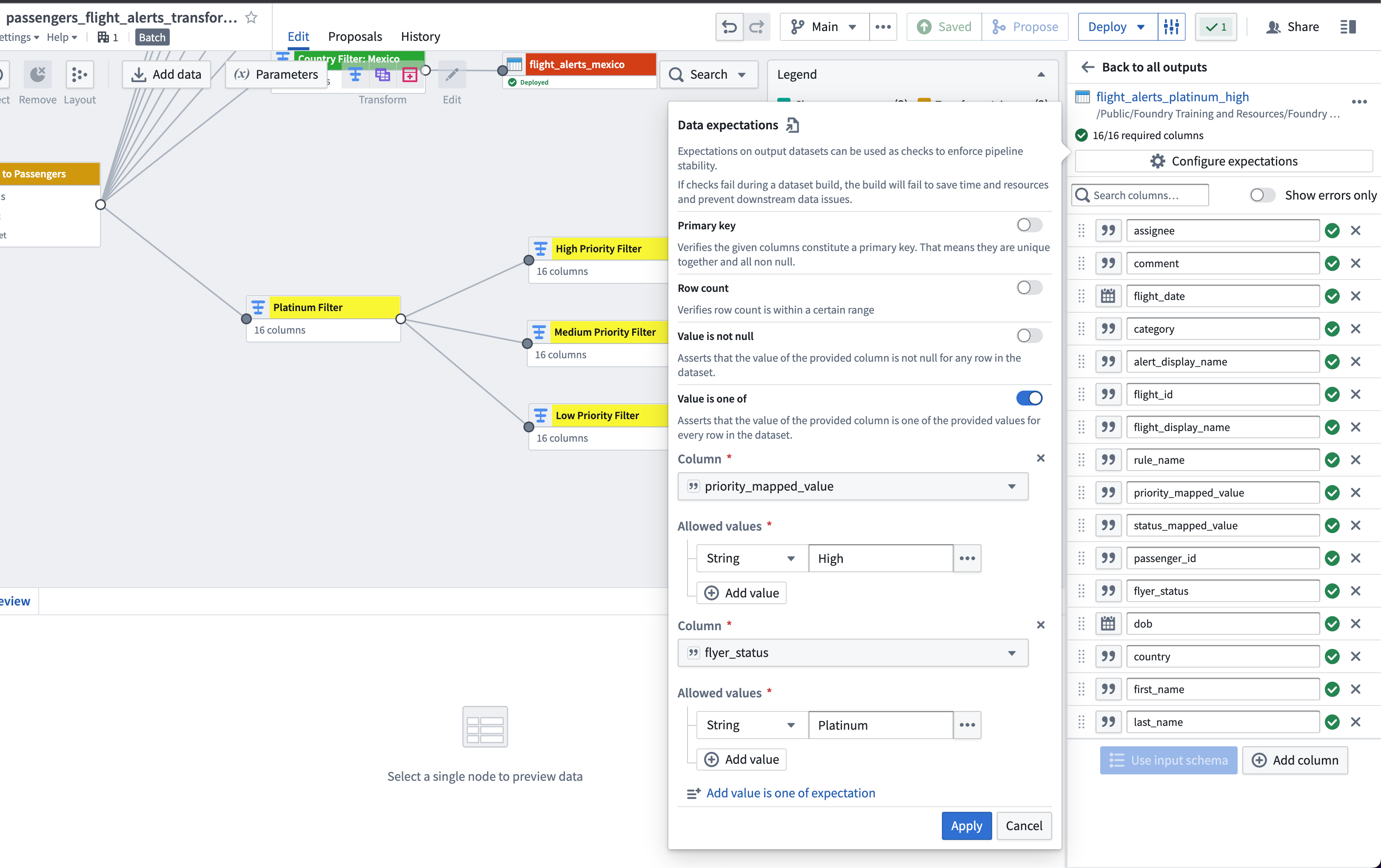
A validation check ensuring that your
flight_alerts_platinum_${priority}datasets contain onlyplatinumstatus passengers and${priority}status alerts (see image below).