8 - Exercise Summary
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
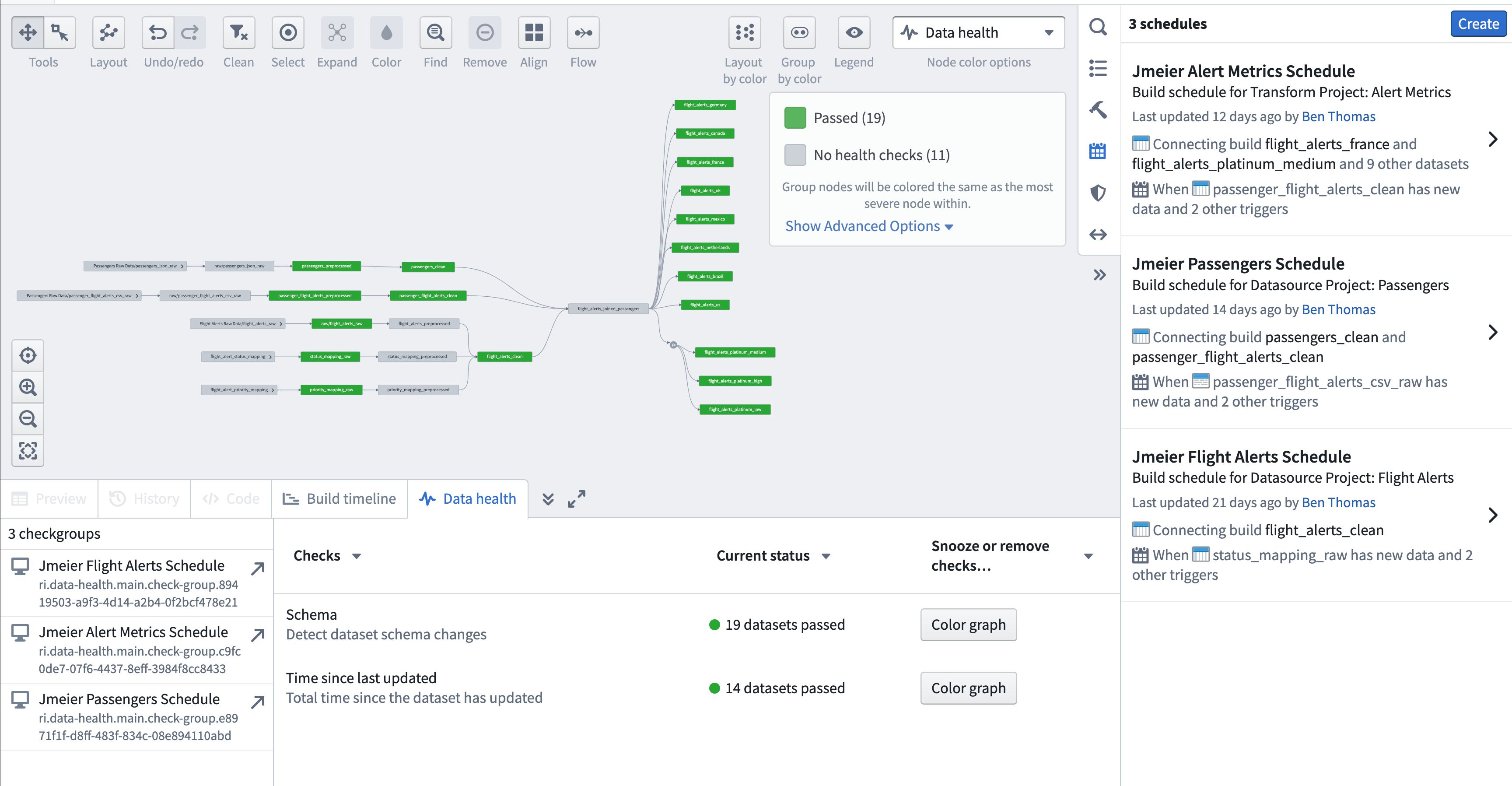
The image above shows the nodes across all three of our connected schedules colored by the Data health node coloring option and with the Data health helper tab open. This will display the check status for all nodes on the graph.
✅ What you built
- Time since last updated (TSLU) and schema checks on the inputs and outputs of your schedule.
✅ What you learned
- A Job is a data computation defined by the logic in a single transform. The subject of a schedule is a Build, which is a collection of one or more jobs that execute reliably together into a single unit of “sense.”
- Palantir recommends putting at least a schema and TSLU check on the targets of your scheduled build and a schema check on the inputs.
- The job tracker application lets you monitor and debug Foundry builds.
- You can apply some checks to multiple datasets simultaneously by selecting more than one Data Lineage node, right clicking, and selecting Add health check...
📚 Recommended Reading (~3 min read)
You’ve had a chance to practice applying recommended checks to your schedule inputs and outputs. Now round out your understanding of health check best practices by reviewing this documentation page, which reviews other optional checks you might want to install.