9 - Configure a Connecting Build Schedule
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
A dataset should only belong to a single schedule.
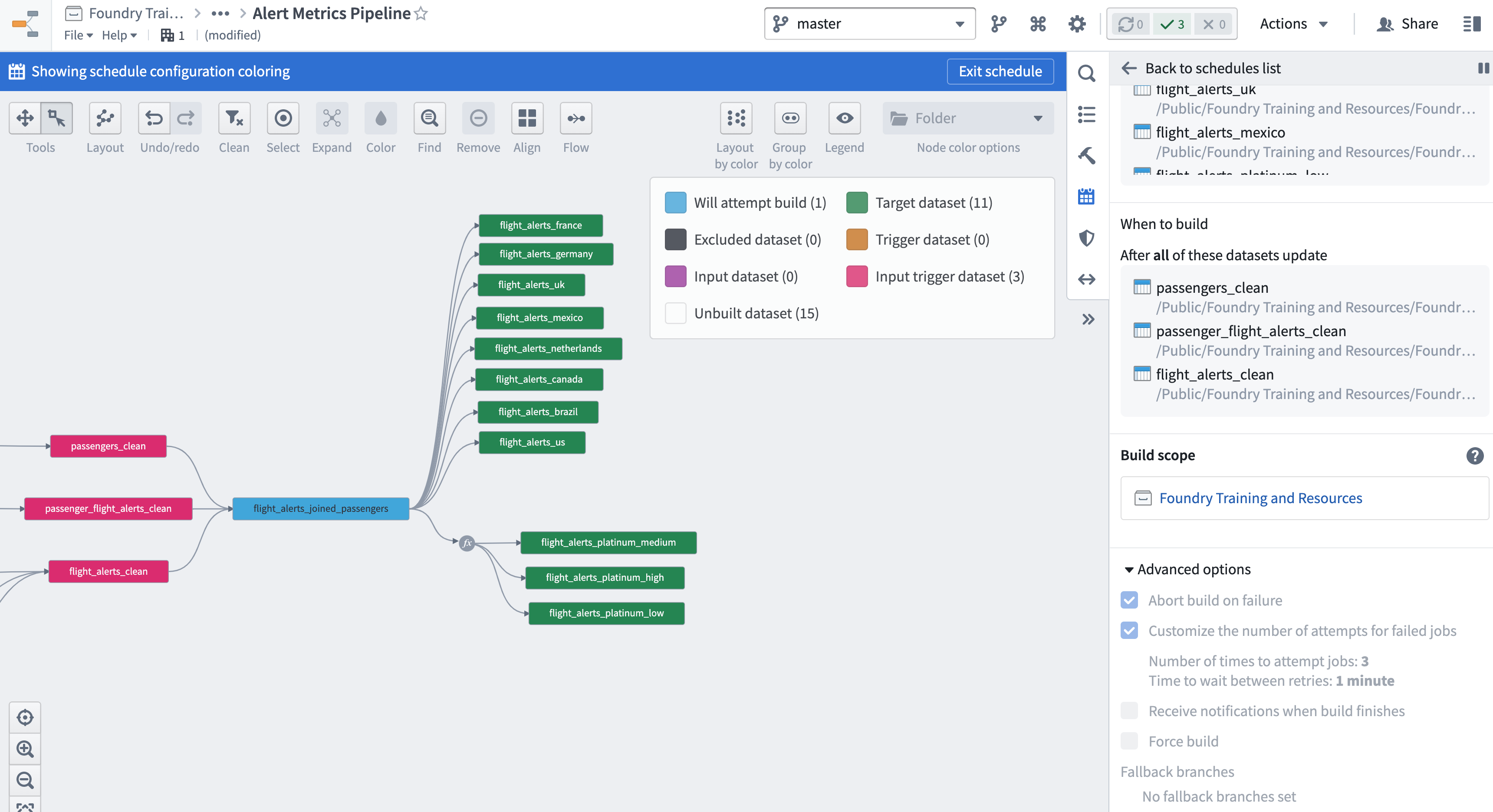
As you connect the datasource and transform stages of your pipeline, we’ll want to make sure we avoid building datasets unnecessarily. The three clean outputs from your two datasource projects will serve as inputs to your transform stage pipeline, but as targets of the schedule you previously configured, they don’t need to be built again in the new schedule. Instead, they’ll serve as inputs in a connecting build schedule. Recall the logic of a connecting build attempts to build everything between the inputs and the targets, excluding the inputs but including the targets.
🔨 Task Instructions
-
Open the Data Lineage graph you saved in the previous task. Turn off the Flow animation if desired.
-
Click the Manage schedules button on the right side of your screen.
-
Your other two schedules appear in the Scheduler UI. Mouse over them alternately to see that the “clean” datasets on your graph are already the targets of a schedule.
-
Create a new schedule and name it yourName Alert Metrics Schedule (e.g., Jmeier Alert Metrics Schedule). Add a description: Build schedule for Transform Project: Alert Metrics.
-
Switch to a connecting build and then define “what” will build “when”:
- Set all of your generated and multi-output datasets as the targets of your schedule.
- Set the three “clean” datasets as input triggers (i.e., set them as inputs then also as triggers, the latter defining “when” your pipeline will build.)
-
Change the Build scope to Project Scoped.
-
Open the Advanced options and set the schedule to abort on failure but retry three times with a minute in between retries.
-
Save your schedule.