16 - Add a Schedule to Your Pipeline
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
In this task, you’ll define a new connecting build schedule — the “what,” “when,” and “how” the passengers datasets in your pipeline will build together. The instructions here are abridged, reflecting the fact you’ve already completed one schedule with your flight alerts project pipeline.
🔨 Task Instructions
-
Open your Passengers Pipeline Data Lineage graph and click the Manage schedules button on the right side of your screen.
-
Create a new schedule and name it yourName Passengers Schedule (e.g., Jmeier Passenger Schedule). Add a description: Build schedule for Datasource Project: Passengers.
-
Switch to a connecting build and then define “what” will build:
- Set your
passengers_cleanandpassenger_flight_alerts_cleanas the targets of your schedule. - Set the
raw/passengers_json_rawandraw/passenger_flight_alerts_csv_rawdatasets as input triggers
- Set your
-
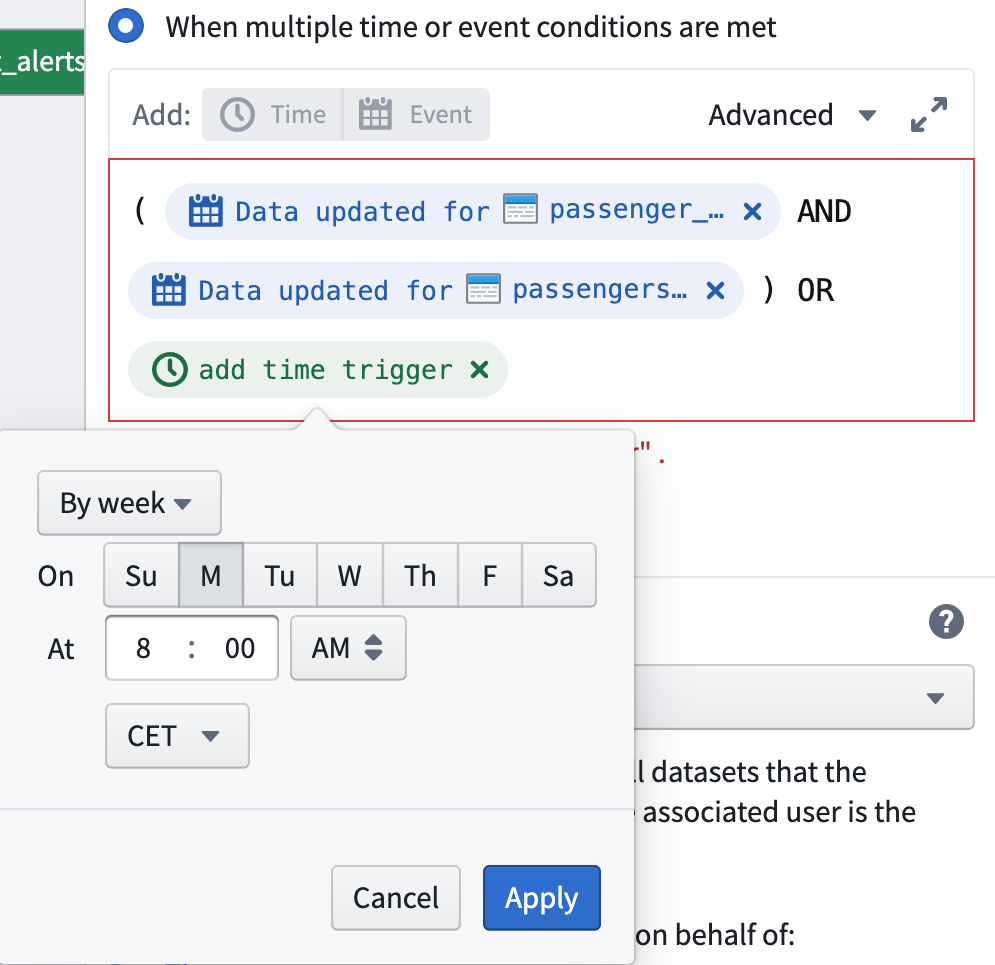
Now define “when” to build. Configure your schedule to execute when both your trigger inputs have new data OR every Monday at 8:00 AM Central European Time (GMT +2). Use the clickable image below as a guide for implementing this logic (use the Add: Time button to add a temporal component).
-
Change the Build scope to Project Scoped.
-
Open the Advanced options and set the schedule to abort on failure but retry three times with a minute in between retries.
-
Save your schedule.