10 - Exercise Summary
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
The image below is a visual summary of the work you’ve done so far on this training track. The highlighted portion represents the steps taken in this tutorial specifically.
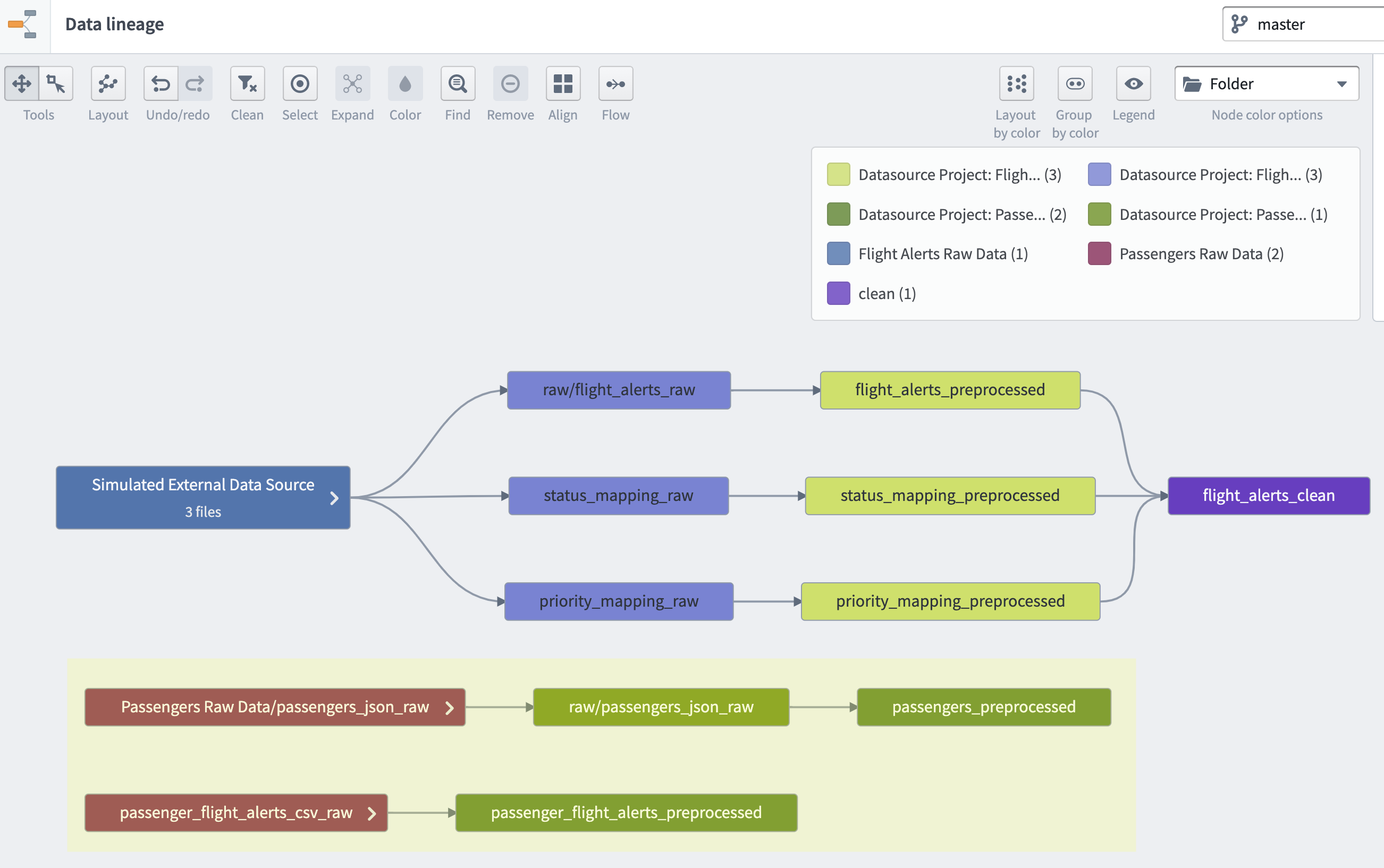
✅ What you built
- Preprocessing Python transform files that parse the raw JSON and CSV into Spark DataFrames and write them out to datasets.
- Preprocessed outputs built on the
Masterbranch.
✅ What you learned
- Datasets can contain raw CSV and JSON files without a schema. Using Foundry APIs and packages, these can be parsed into to Spark DataFrames and written to Parquet.
- If Code Assist is running, you can ctrl+click module names and variables are Foundry\Clickable modules and variables.