7 - Preprocess Your Data, Part 1
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
Just as you did for the datasets in your Datasource Project: Flight Alerts project, you’ll need a preprocessing step for your passengers and passenger_flight_alerts (which maps passengers to flight alerts) datasets. As you might suspect, the first order of business is to read the dataset files and parse them into Spark DataFrames so they can be written to an optimized Parquet format.
Parquet does not allow special characters or spaces in column names, so your preprocessing step will also involve sanitizing column names. Among the APIs and packages Foundry provides to streamline code-based transformation is sanitize_schema_for_parquet from the transforms.verbs.dataframes package, which removes any characters from DataFrame column names that would prevent them being saved as Parquet files and thus prevent the dataset from successfully building.
🔨 Task Instructions
-
First, create a new branch from
MastercalledyourName/feature/tutorial_preprocessed_files. -
Right click on the
/datasetsfolder in the Files section of your code repository and create a new folder called/preprocessed. -
Create a new Python file in your
/preprocessedfolder calledpassenger_flight_alerts_preprocessed.py. -
Open the
passenger_flight_alerts_preprocessed.pyfile and replace the default contents with the code block below.from transforms.api import transform, Input, Output from transforms.verbs.dataframes import sanitize_schema_for_parquet @transform( parsed_output=Output("/${space}/Temporary Training Artifacts/${yourName}/Data Engineering Tutorials/Datasource Project: Passengers/datasets/preprocessed/passenger_flight_alerts_preprocessed"), raw_file_input=Input("${passenger_flight_alerts_csv_raw_RID}"), ) def read_csv(ctx, parsed_output, raw_file_input): # Create a variable for the filesystem of the input datasets filesystem = raw_file_input.filesystem() # Create a variable for the hadoop path of the files in the input dataset hadoop_path = filesystem.hadoop_path # Create an array of the absolute path of each file in the input dataset paths = [f"{hadoop_path}/{f.path}" for f in filesystem.ls()] # Create a Spark dataframe from all of the CSV files in the input dataset df = ( ctx .spark_session .read .option("encoding", "UTF-8") # UTF-8 is the default .option("header", True) .option("inferSchema", True) .csv(paths) ) """ Write the dataframe to the output dataset using the sanitize_schema_for_parquet function to make sure that the column names don't contain any special characters that would break the output parquet file """ parsed_output.write_dataframe(sanitize_schema_for_parquet(df)) -
Replace the following:
- Replace the
${space}on line 6 with your space. - Replace the
${yourName}on line 6 with your Tutorial Practice Artifacts folder name. - Replace
${passenger_flight_alerts_raw_RID}on line 7 with the RID of thepassenger_flight_alerts_csv_rawdataset, which is the output defined inpassenger_flight_alerts_raw.py. If you replaced the paths with RIDs in the previous task, you should be able to copy the RID from that file and paste it into this one. - Otherwise, RIDs can be obtained from the Foundry Explorer helper using the workflow illustrated below.
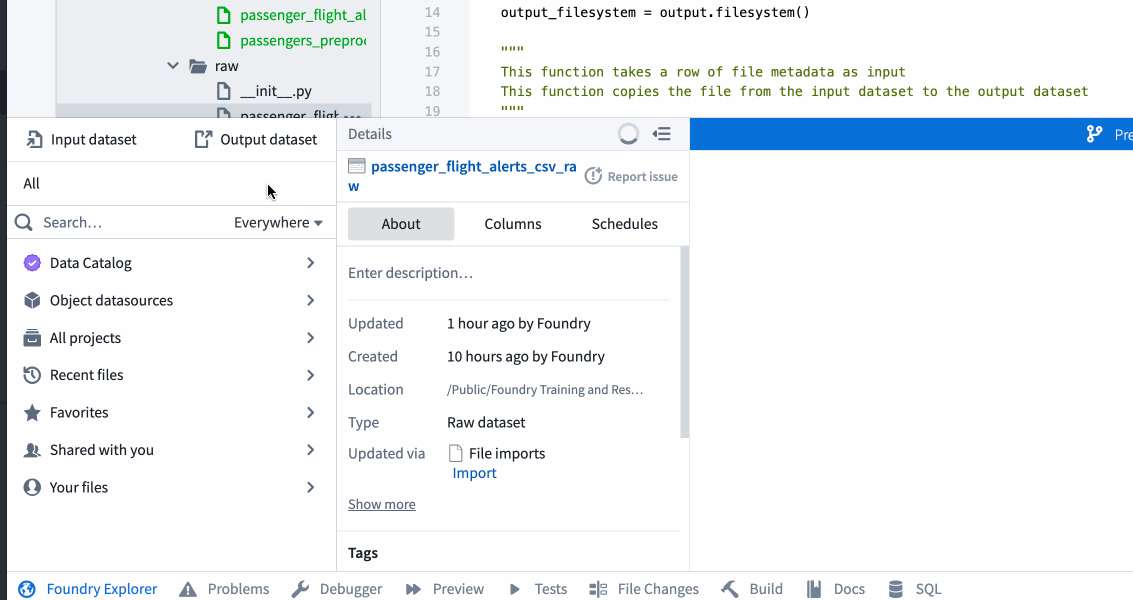
- Replace the
-
Using the Preview button in the top right, test your code to ensure the output appears as a dataset rather than a raw file. If prompted in the preview window to Configure input files, click
Configure...and tick the box next topassenger_flight_alerts.csvin the next screen. -
If your testing works as expected, commit your code with a meaningful message, e.g., “feature: add passenger_flight_alerts_preprocessed”.
-
Build your
passenger_flight_alerts_preprocessed.pycode on your feature branch and confirm the output dataset contains a two-column mapping of passengers to flight alerts.