9 - Join flight alerts and passengers
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
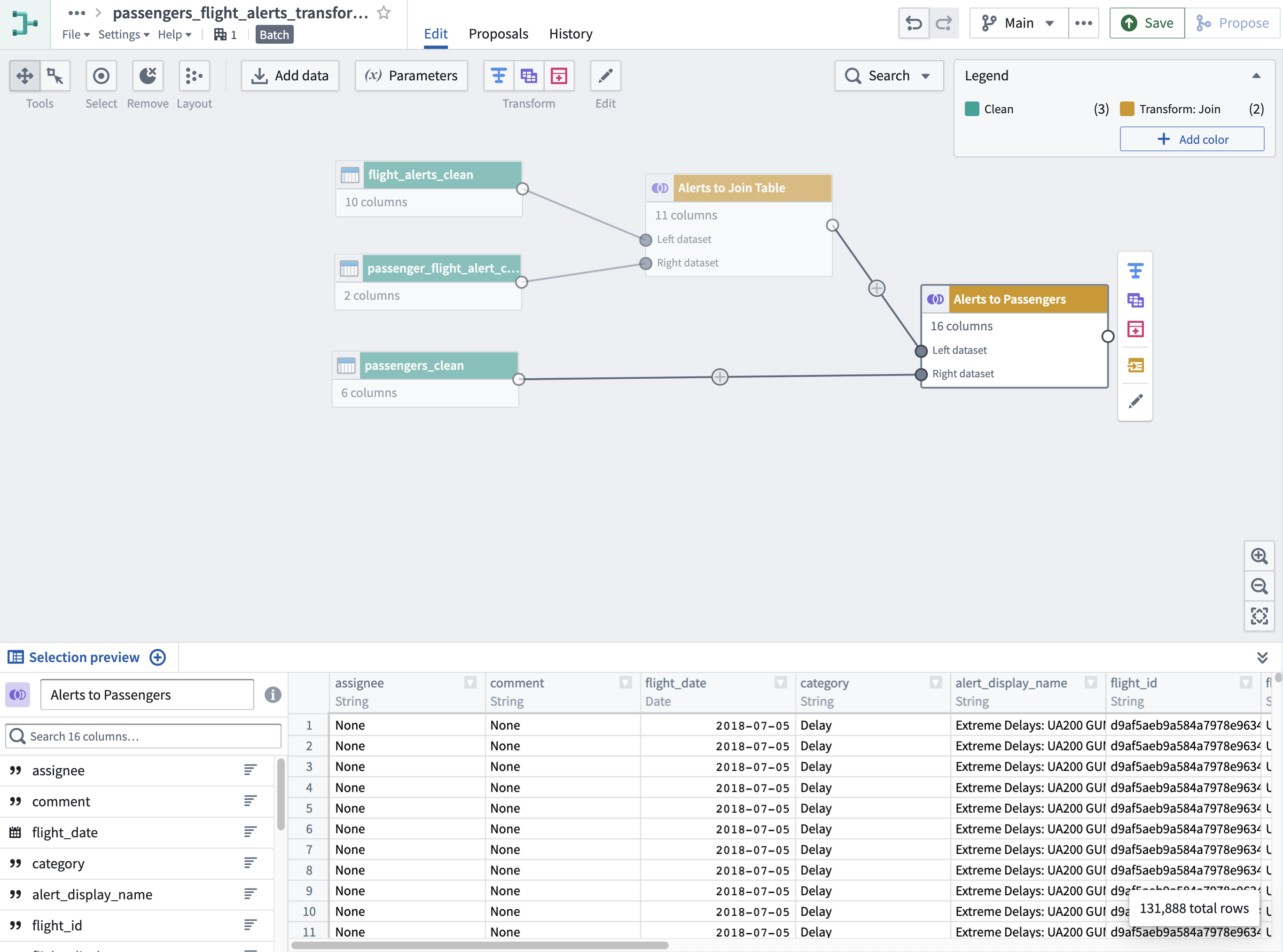
A Transform Project typically combines sources and applies additional business logic to produce enriched datasets. In general, these datasets are not meant for general exposure (like the ones in the Ontology Project stage are). In this task we’ll perform a simple join of the three clean output datasets from your flight alerts and passengers datasource projects. This is the type of “pre-work” you’d conduct in a /transformed code folder.
You’ll start with the flight alerts dataset, which has ~2.5k rows. To enable an eventual join with the passengers data (~10k rows), you’ll need to first use the passenger_flight_alert_clean join table (~132k rows), which contains the primary keys of the flight alerts and passengers tables.
🔨 Task Instructions
-
Open the
/transformedfolder you created in the previous exercise. -
Create a new batch pipeline in Pipeline Builder called
passengers_flight_alerts_transformed. -
Add the following clean datasets you’ve created in this learning path:
flight_alerts_cleanpassengers_cleanpassenger_flight_alert_clean
-
Add a transform to
flight_alerts_cleanthat left joinspassenger_flight_alert_cleanon thealert_display_name. -
Name your transform
Alerts to Join Table. -
Create a new transform called
Alerts to Passengersthat joins yourAlerts to Join Tabletransform topassengers_clean, usingpassenger_idas the shared key. -
Save your pipeline.