6 - Schedule the passengers pipeline
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
Let’s create a schedule for this segment of your overall pipeline using the principles you learned in the previous tutorial on Scheduling Pipelines.
🔨 Task Instructions
-
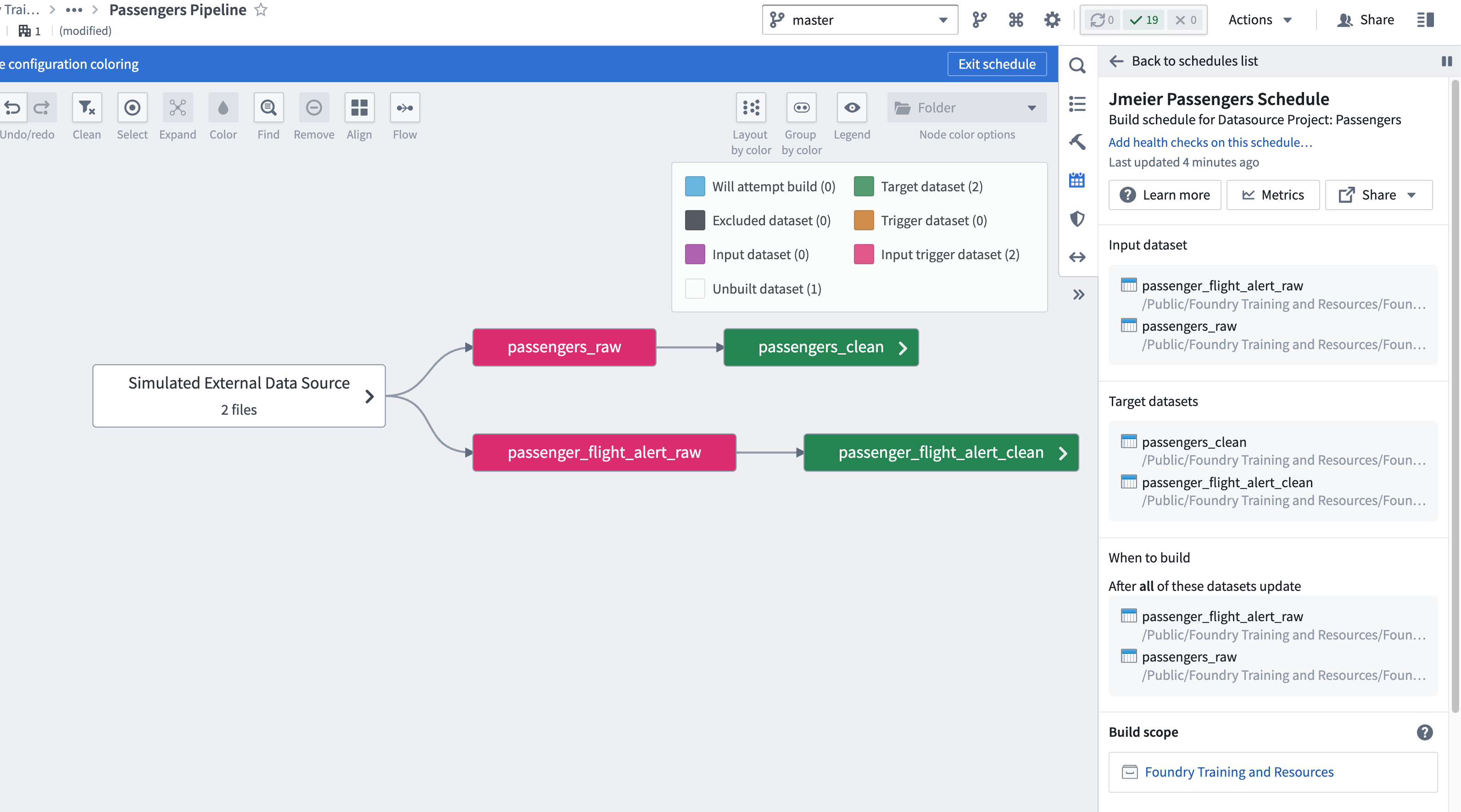
Open the Data Lineage graph you saved in the previous task.
-
Click the Manage schedules button on the right side of your screen.
-
Create a new schedule and name it
*yourName Passengers Schedule(e.g., Jmeier Passengers Schedule). Add a description:Build schedule for Datasource Project: Passengers. -
Switch to a connecting build and then define “what” will build “when”:
- Set your two clean datasets as the targets of your schedule.
- Set your two raw datasets as input triggers (i.e., set them as inputs then also as triggers*).
-
Change the Build scope to Project Scoped.
-
Open the Advanced options and set the schedule to abort on failure but retry three times with a minute in between retries.
-
Save your schedule.