3 - Create and hydrate your passenger datasource project, part 2
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
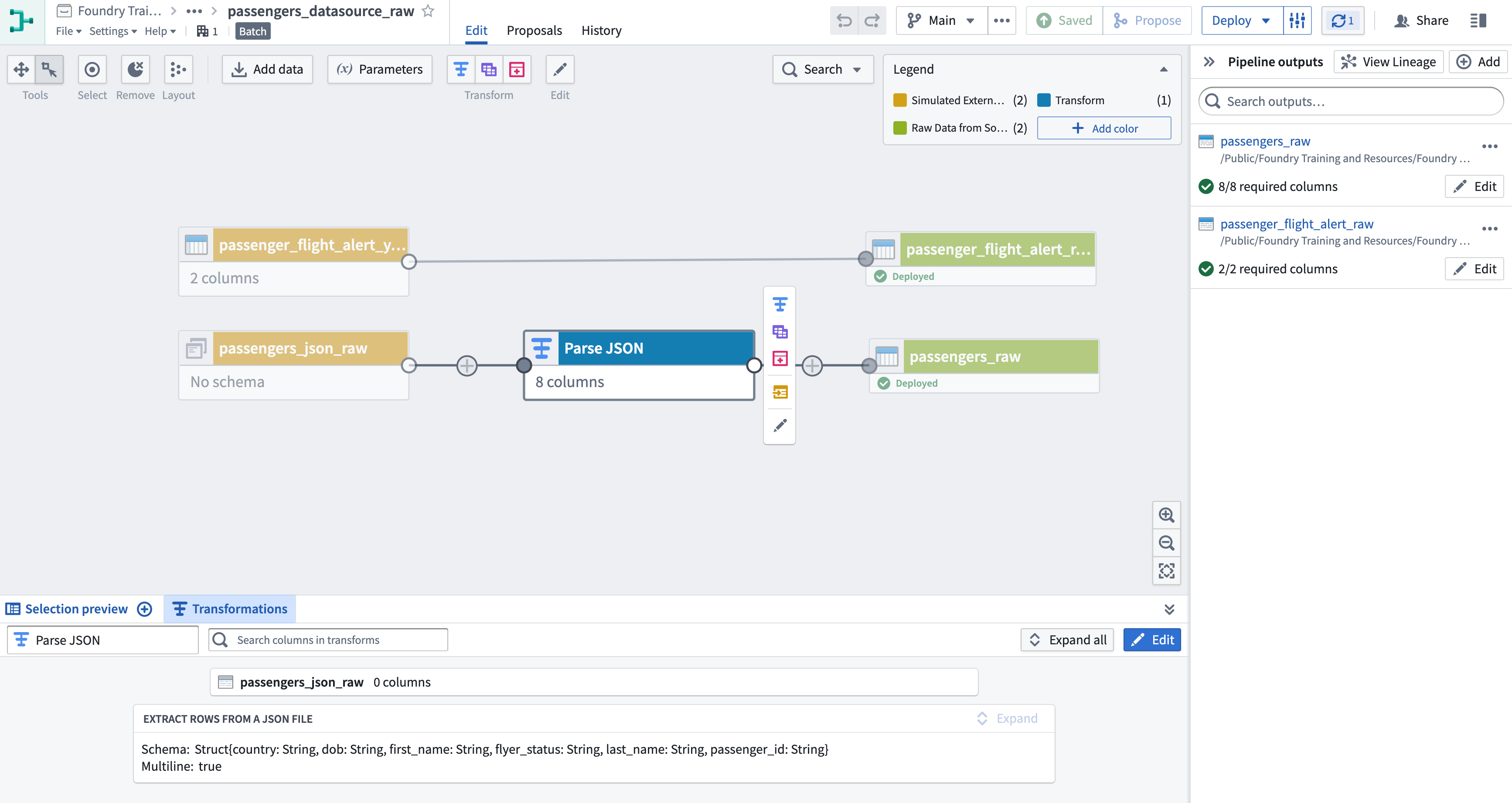
As you can see on your Pipeline Builder graph, passengers_raw_json does not have a schema. This is because the file is written in JSON and must first be converted into a format Spark can work with. This task demonstrates how Pipeline Builder can parse JSON and XML into Foundry datasets.
🔨 Task Instructions
-
Add a transform to the
passengers_json_rawdataset that uses the Extract Rows from a JSON File board. -
Name your transform (in the top left corner of the transform screen) “Parse JSON.”
-
In the Example data text area, enter the following JSON object, which we’ve taken from the raw data. Pipeline Builder can then infer the schema from this single object.
{ "passenger_id": "0f7a3494b080426ca95bb6d155c33e42", "first_name": "Benjamin", "last_name": "Payne", "dob": "7/16/73", "country": "Mexico", "flyer_status": "None" } -
Click the Generate Schema button and then on Apply.
-
Return to the graph and create a new output from your new transform called
passengers_raw. -
Consider adding node colors to your imports and outputs as shown below.
-
Save and Deploy your pipeline.