4 - Defining when your Schedule will Build
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
Scheduled builds run when the condition defined by the trigger(s) is satisfied. Triggers can be event-based (e.g., run when datasets a, b, and c successfully update), time-based (e.g., every other day at 03:00), or a combination of the two. In this task, you’ll define a multidimensional event trigger to initiate your pipeline schedule.
📚 Recommended Reading (~5 min read)
Navigate to the Scheduler documentation to read more about triggers before moving on. This tutorial will implement a simple trigger configuration, but data engineers should be aware of the available complexity.
🔨 Task Instructions
-
Hold shift and drag a selection box around the
raw/flight_alert_raw,priority_mapping_raw, andstatus_mapping_rawnodes on your graph and define them as Triggers. The datasets now appear in the When to build section in the Scheduler panel.Let’s say, however, that you’d like to enable a more complex trigger: update the pipeline when the code for the
raw/flight_alert_rawdataset transform is updated OR whenstatus_mapping_rawANDpriority_mapping_rawhave successfully run. -
In the Scheduler panel’s When to build section, click the radio button next to When multiple time or event conditions are met. This opens a text area where your selected triggers appear as light blue “pills”.
-
Click on the
Data updated for flight_alerts_rawitem in the text area to open the trigger definition window. By default, setting a dataset as a trigger will kick off your schedule when there has been a new transaction on the trigger dataset (e.g., it has "updated data"). Let's change it so that the trigger fires when the logic to compute a dataset is updated. Change the trigger logic fromData updated ▾toNew logic ▾as shown in the image below. Then click Apply.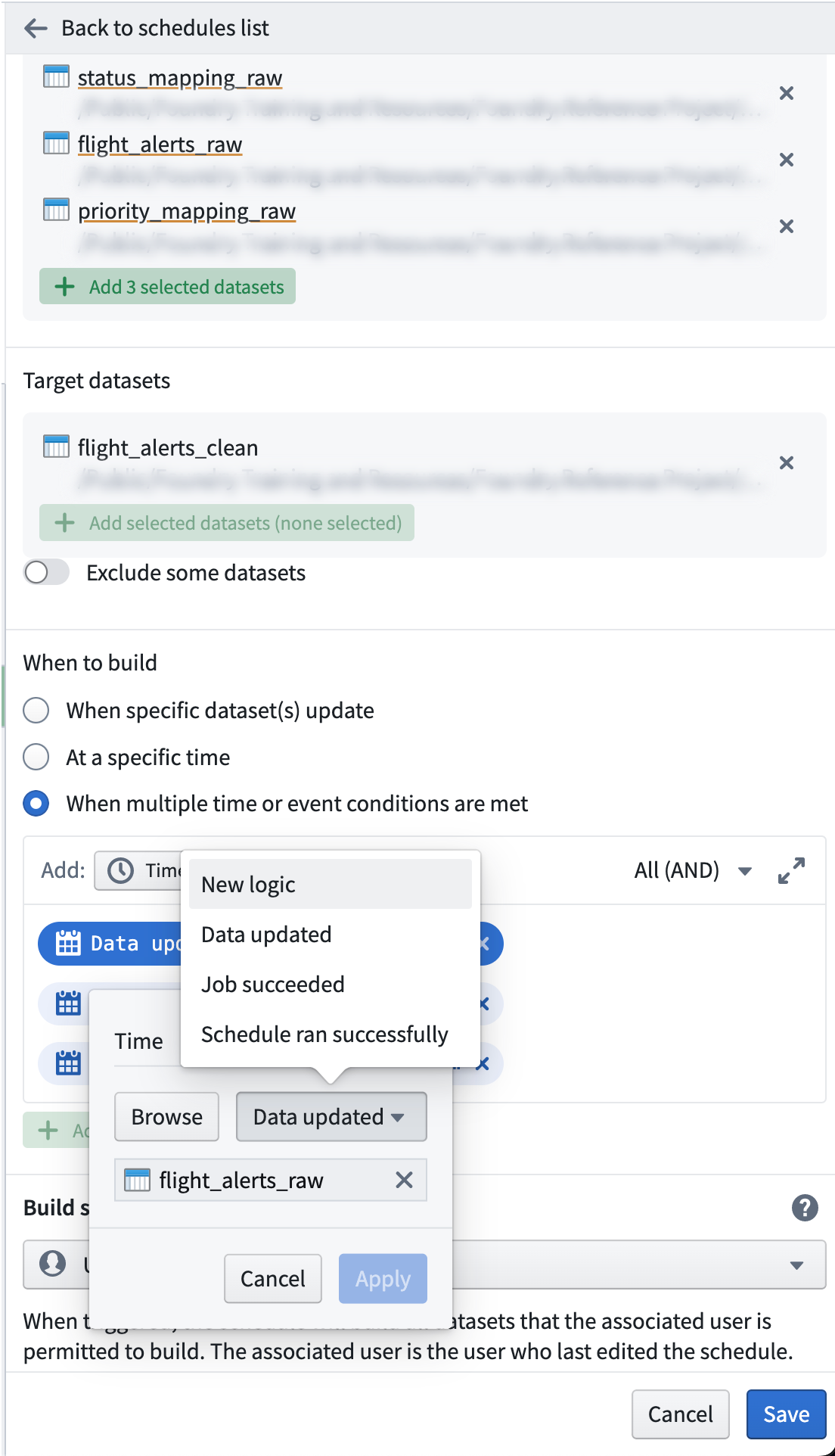
-
In the trigger conditions text area, click the All(AND) ▾ dropdown menu on the right and choose Advanced configuration.
-
Manually add in the boolean conditions and parentheses needed to achieve this configuration:
( New logic for flight_alerts_raw ) OR ( Data updated for status_mapping_raw AND Data updated for priority_mapping_raw )
ℹ️ For data pipelines, it’s best to use event-based triggers. Use time-triggered schedules for Data Connection syncs, writeback datasets, and niche use cases.