3 - Add your cleaning logic
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
A clean dataset is one that is ready for use in Foundry workflows. For our case, this means joining the text-based mapped_values in the status and priority mapping tables to the flight alerts dataset. That way, the flights dataset will contain values your colleagues can more readily use in operational settings. Join transforms in Pipeline Builder work similarly to how SQL joins work. If you are unfamiliar with joins, brush up on some basics again using a tutorial from W3 Schools ↗. A quick overview of how joins work in Pipeline Builder can be found in this part of the documentation.
🔨 Task Instructions
-
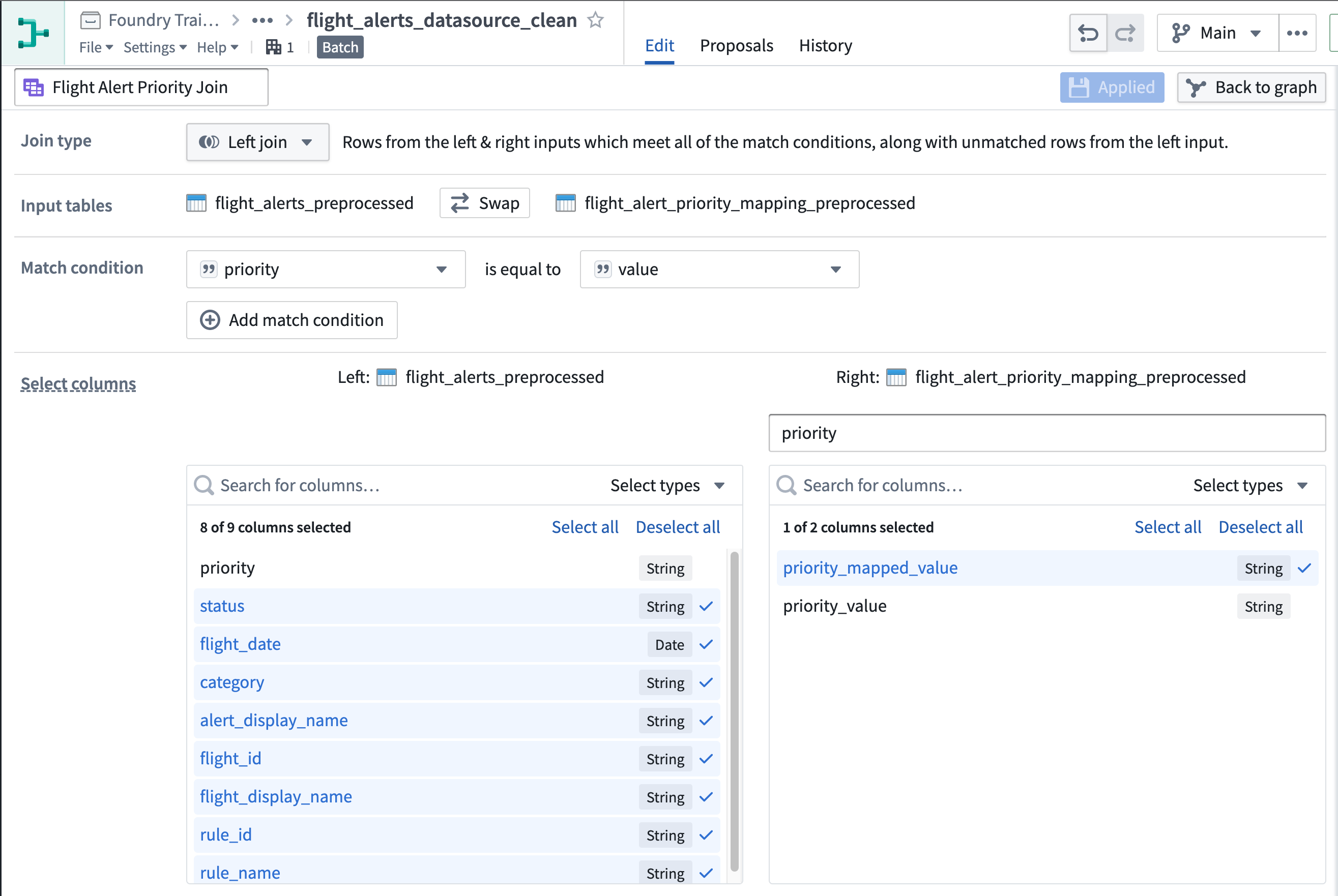
Select the
flight_alerts_preprocessednode and add a join transform.Note: Order matters. E.g. If you are executing a left join on the flight_alerts_preprocessed dataset, this must also appear on the left-hand side of the input tables field. If you started the wrong way around, don't worry, you can always click "swap" to configure which table is the left table and which one the right table.
-
Use the following tips to join with the
priority_mapping_preprocessednode.- The
prioritycolumn in the flight alerts dataset matches thevaluecolumn in the priority mapping dataset. - In the Select columns area of then join page, consider using priority as the prefix for the right columns.
- You can safely drop the
prioritycolumn from the left side of the join and thevalue(orpriority_valueif you added a prefix) from the right. - If the columns in the match condition for the join are of different types, you can explicitly cast either of the columns to a matching type using a 'Cast' expression before joining. For example, if priority is of integer type, and value of string type, you can cast priority to string type in a previous board.
- The
-
On the join page, click into the join name field in the upper left area of the screen and rename it from the default (
Join) toFlight Alert Priority Join. -
Select Apply and confirm the preview at the bottom looks accurate.
-
If you are stuck, scroll down to see an example solution.
-
Save your pipeline.