7 - Preprocessing Logic: Mapping Datasets
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
📖 Task Introduction
Let’s now apply similar transforms to your two mapping datasets. Both need column names normalized and values cast as strings and standardized.
🔨 Task Instructions
-
Add transform nodes for
priority_mapping_rawandstatus_mapping_raw(i.e., one for each). -
For each dataset transform:
- Name your transforms (in the upper left corner of the application) Preprocess priority mapping and Preprocess status mapping respectively
- Cast the value column as string
- Convert mapped_value columns to title case
-
In addition, for
status_mapping_raw, see if you can find and configure transforms that remove whitespace and convert values to title case without any underscores. If you get stuck, see the hint for a suggested implementation.Hint:
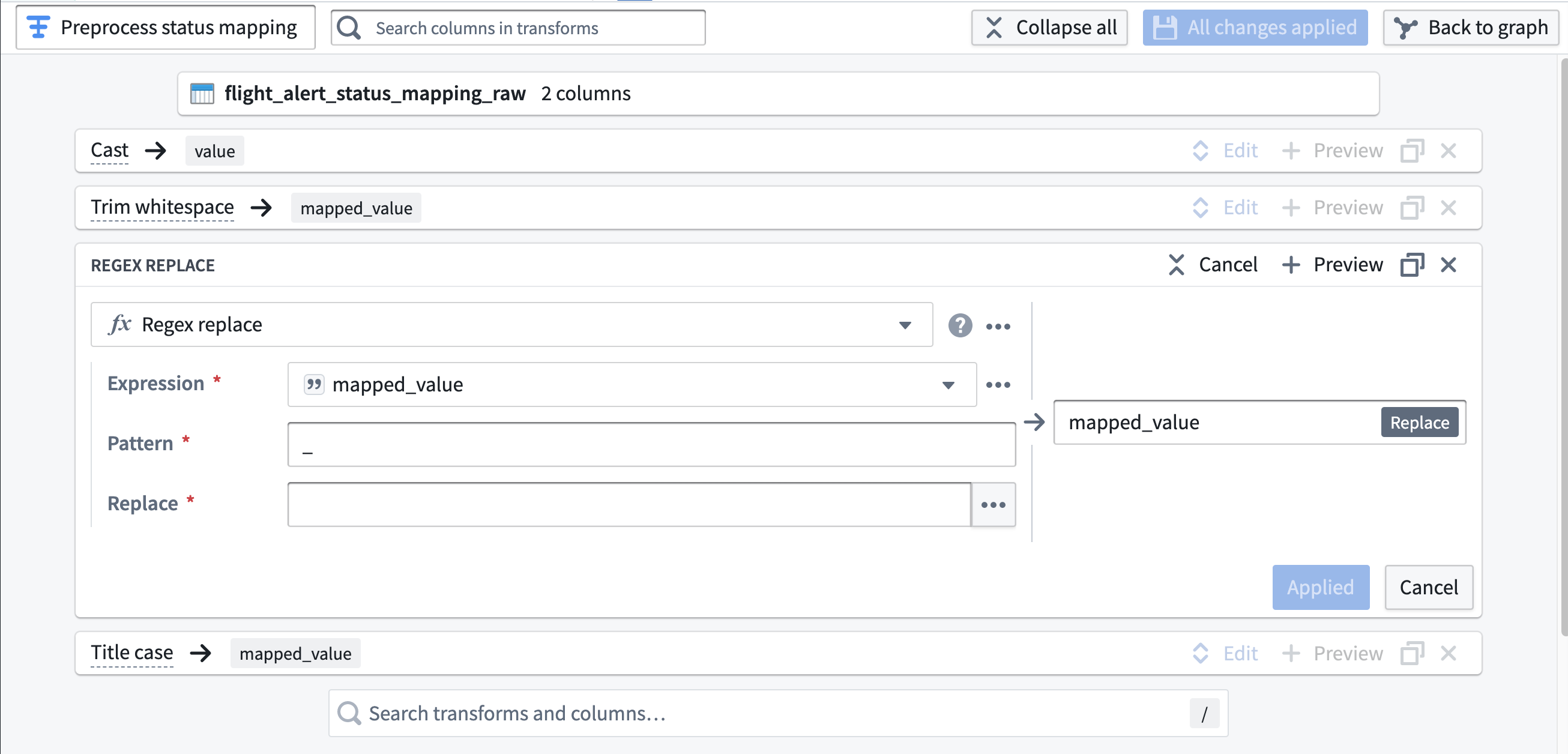
-
Add pipeline outputs for each, called
priority_mapping_preprocessedandstatus_mapping_preprocessedrespectively. -
Save and Deploy your pipeline to build the outputs in your
/preprocessedfolder.