5 - When to think, "Pipeline"!
This content is also available at learn.palantir.com ↗ and is presented here for accessibility purposes.
When should you build a pipeline, and how should you get started?
The first step in developing a pipeline is agreeing on a data-driven outcome. This might be a series of Contour dashboards, a Slate application, or an integrated Workshop module built on new Ontology object and link types. With clarity around your objective, you can begin planning the data you need to support it.
In general, a combination of the “triggers” below may suggest you should build a production data pipeline—one that supports operationally critical or user-facing workflows:
- You have clearly defined the desired output and identified source data.
- There is a gap between your source data and the data needed to immediately back your final output(s).
- You need to keep your data assets up-to-date with refreshing source data.
- Your end product(s) must adhere to service-level agreements (SLAs).
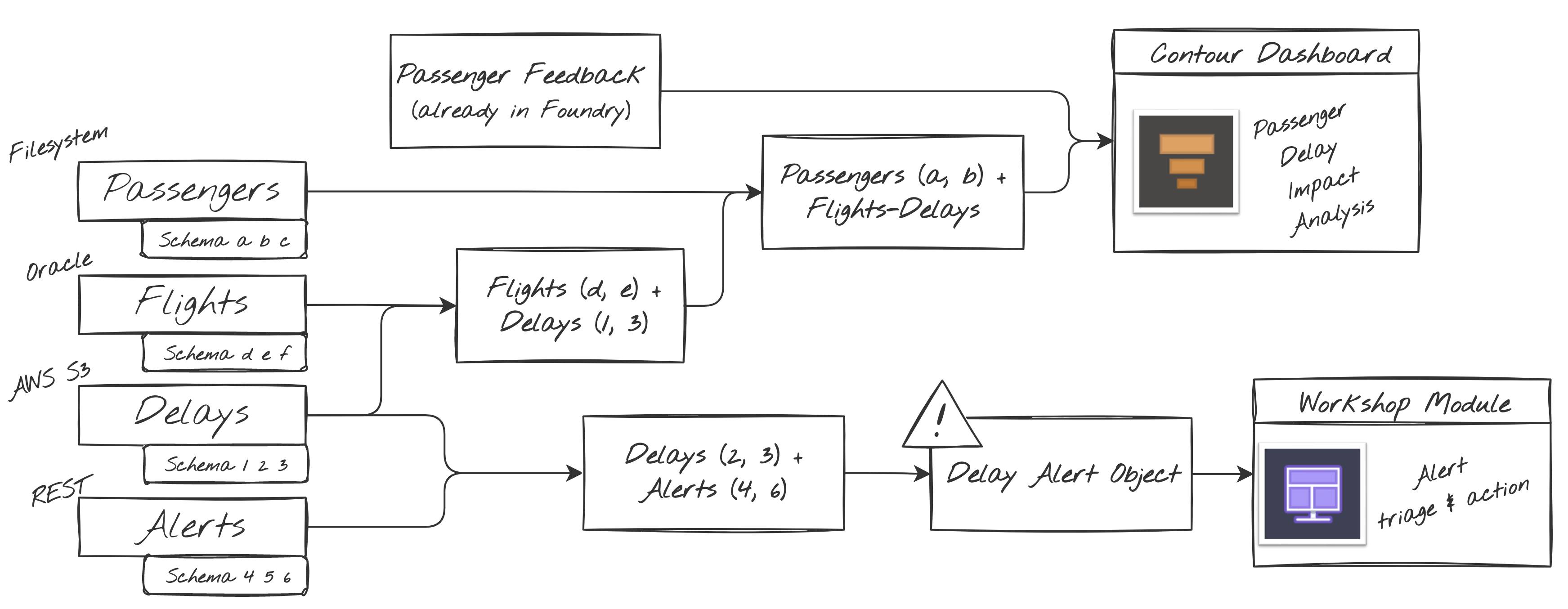
In the sketch below, a team has determined they need to create a Contour analysis and dashboard for internal reporting purposes and a user-facing Workshop module that enables write-back actions from an operations desk. Working right to left, they determined the data they needed to populate the supporting/backing datasets, and discussed the transform steps needed to move from their raw sources (which they also identified) to their enriched states. They may also have determined, for example, that end users can tolerate nothing more than a 30-minute delay between a source event (e.g., a flight is actually delayed) and appearance in the end products.