- Capabilities
- Getting started
- Architecture center
- Platform updates
Evaluate a model in code
Metric sets were built for dataset-backed models using foundry_ml, a library which has been formally deprecated since October 31, 2025. For new implementations, we recommend using experiments instead. Metric sets will not appear on the model page for a model built with palantir_models, although they can be shown in a modeling objective.
In Foundry, the performance of an individual model can be evaluated in code by creating one or more metric sets for that model. This page assumes knowledge of the MetricSet class.
The metrics produced by a metric set are associated with a specific transaction of the evaluation dataset and are available for review in the Modeling Objectives application. Note that you'll need to enable these metrics by toggling Only show metrics produced by evaluation configuration in the Modeling Objectives settings page.
Metrics are associated with a specific transaction of an input dataset; you may need to rerun the code that produces a metric set each time you update the model or input dataset.
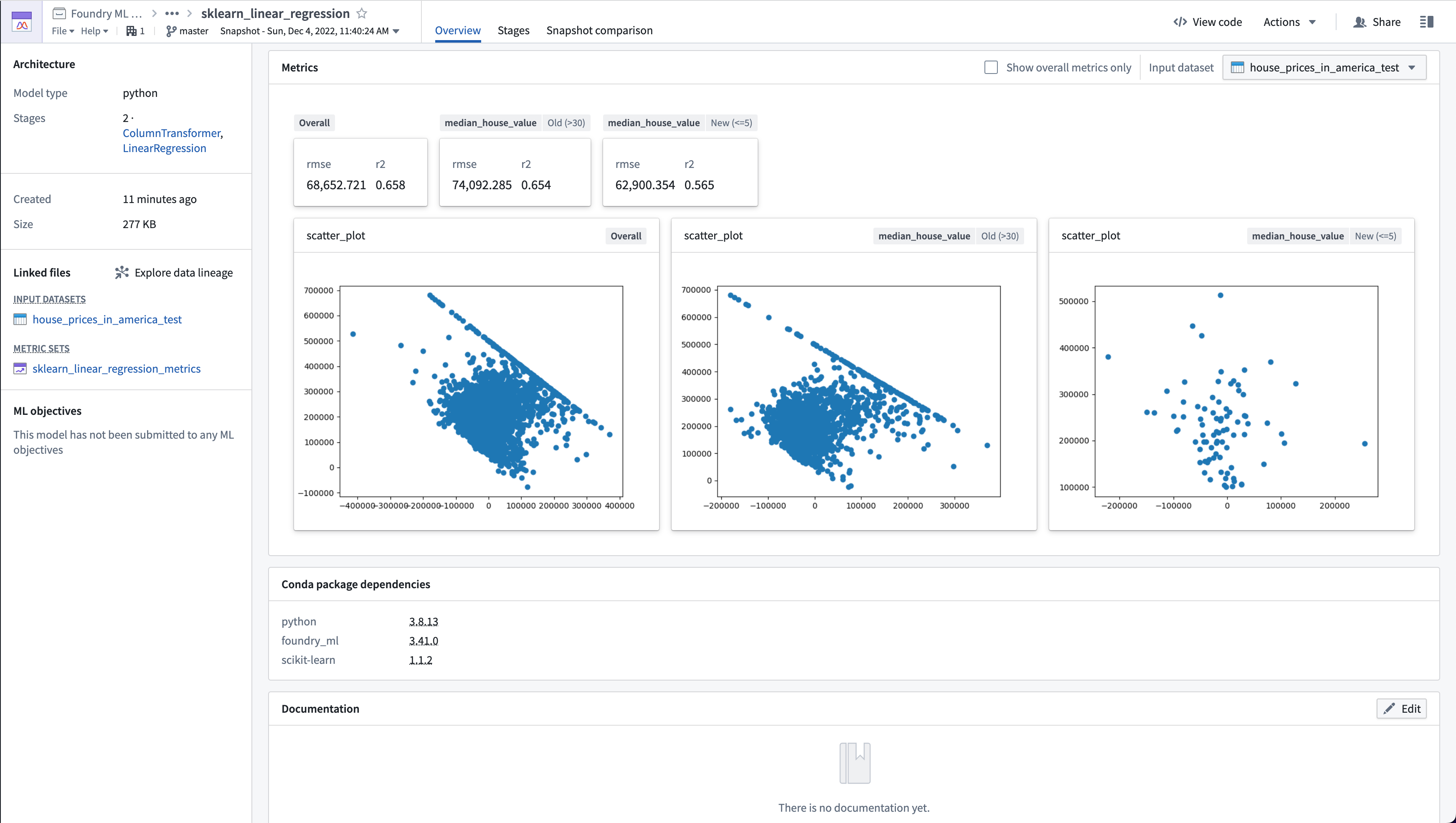
Evaluate a model in Code Workbook
To evaluate a model in the Code Workbook application:
- Create a code workbook or open an existing workbook.
- Import the
foundry_mlpackage into the environment for your code workbook. Thefoundry_ml_metricspackage will be available as part offoundry_ml. - Import the model and evaluation dataset into the code workbook.
- Create a transform that produces a
MetricSetobject in Python and associate your model and evaluation dataset as inputs of thatMetricSet.- Be sure to save the results as a dataset.
- The input types of the model will need to be an
Objectand the evaluation dataset aTransformsInput.
- Add the metrics to the
MetricSetin your transform. - Return the
MetricSetas the result of the transform.
An example for a regression model named lr_model and testing dataset named testing_data is below. Note that this code snippet uses a model and testing dataset based on the housing dataset featured in the Getting Started tutorial.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77def lr_evaluation_testing(lr_model, testing_data_input): from foundry_ml_metrics import MetricSet # Make sure foundry_ml has been added to your environment model = lr_model # Rename model metric_set = MetricSet( # Create a MetricSet to add individual metrics to model = lr_model, # The Foundry ML Model you are evaluating input_data=testing_data_input # The TransformInput of the dataset you are evaluating performance against ) testing_data_df = testing_data_input.dataframe().toPandas() # Get a pandas dataframe from the TransformInput y_true_column = 'median_house_value' # This is the column in the evaluation dataset the model is predicting y_prediction_column = 'prediction' # This is the column the model produces when it transforms a dataset scored_df = get_model_scores(model, testing_data_df) # Add metrics on the entire input dataset add_numeric_metrics_to_metric_set(metric_set, scored_df, y_true_column, y_prediction_column) add_residuals_scatter_plot_to_metric_set(metric_set, scored_df, y_true_column, y_prediction_column) # Add metrics where the housing_median_age column is greater than 30 old_homes_subset = {'median_house_value': 'Old (>30)'} old_houses_scored_df = scored_df[scored_df['housing_median_age'] > 30] add_numeric_metrics_to_metric_set(metric_set, old_houses_scored_df, y_true_column, y_prediction_column, old_homes_subset) add_residuals_scatter_plot_to_metric_set(metric_set, old_houses_scored_df, y_true_column, y_prediction_column, old_homes_subset) # Add metrics where the housing_median_age column is less than or equal to 5 new_homes_subset = {'median_house_value': 'New (<=5)'} new_houses_scored_df = scored_df[scored_df['housing_median_age'] <= 5] add_numeric_metrics_to_metric_set(metric_set, new_houses_scored_df, y_true_column, y_prediction_column, new_homes_subset) add_residuals_scatter_plot_to_metric_set(metric_set, new_houses_scored_df, y_true_column, y_prediction_column, new_homes_subset) return metric_set # Code Workbooks will save this as a MetricSet in Foundry def get_model_scores(model, df): return model.transform(df) # Create predictions based on the model def add_numeric_metrics_to_metric_set( metric_set, scored_df, y_true_column, y_prediction_column, subset=None ): import numpy as np from sklearn.metrics import mean_squared_error, r2_score y_true = scored_df[y_true_column] y_pred = scored_df[y_prediction_column] # Compute metrics mse = mean_squared_error(y_true, y_pred) rmse = np.sqrt(mse) r2 = r2_score(y_true, y_pred) metric_set.add(name='rmse', value=rmse, subset=subset) # rmse is a float metric_set.add(name='r2', value=r2, subset=subset) # r2 is a float def add_residuals_scatter_plot_to_metric_set( metric_set, scored_df, y_true_column, y_prediction_column, subset=None ): import matplotlib.pyplot as plt y_true = scored_df[y_true_column] y_pred = scored_df[y_prediction_column] scatter_plot = plt.scatter((y_true - y_pred), y_pred) # Create a scatter plot figure = plt.gcf() # Gets the current pyplot figure metric_set.add(name='scatter_plot', value=figure, subset=subset) # figure is a pyplot image plt.close() # Close the pyplot figure
Evaluate a model in Code Repositories
To evaluate a model in the Code Repositories application:
- Create a code repository or open an existing repository.
- Import
foundry_mlpackage into the environment for your code repository. Thefoundry_ml_metricspackage will be available as part offoundry_ml. - Create a transform that produces a
MetricSetobject in Python and associate your model and evaluation dataset as inputs of thatMetricSet.- Rather than return your MetricSet, save the metric_set with
metric_set.save(metrics_output). - The transform input types of both your model and evaluation dataset will be
TransformInput.
- Rather than return your MetricSet, save the metric_set with
- Add the metrics to the
MetricSetin your transform. - Return the
MetricSetas the result of the transform.
An example for a regression model named lr_model and testing dataset named testing_data is below. Note that this code snippet uses a model and testing dataset based on the housing dataset featured in the Getting Started tutorial.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89from transforms.api import transform, Input, Output # Make sure foundry_ml has been added to your run requirements in transforms-python/conda_recipe/meta.yaml from foundry_ml import Model from foundry_ml_metrics import MetricSet @transform( # As this uses @transform, the inputs will be TransformInput's # You will need to update the Output Path to the output location you want your metrics saved to metrics_output=Output("/Path/to/metrics_dataset/sklearn_linear_regression_metrics"), # You will need to update the Input Path to the path of your model and evaluation dataset model_input=Input("/Path/to/model/sklearn_linear_regression"), testing_data_input=Input("/Path/to/evaluation_dataset/house_prices_in_america_test") ) def compute(metrics_output, model_input, testing_data_input): model = Model.load(model_input) # Load the Foundry ML Model from the TransformInput metric_set = MetricSet( # Create a MetricSet to add individual metrics to model=model, # The Foundry ML Model you are evaluating input_data=testing_data_input # The TransformInput of the dataset you are evaluating performance against ) testing_data_df = testing_data_input.dataframe().toPandas() # Get a pandas dataframe from the TransformInput y_true_column = 'median_house_value' # This is the column in the evaluation dataset the model is predicting y_prediction_column = 'prediction' # This is the column the model produces when it transforms a dataset scored_df = get_model_scores(model, testing_data_df) # Add metrics on the entire input dataset add_numeric_metrics_to_metric_set(metric_set, scored_df, y_true_column, y_prediction_column) add_residuals_scatter_plot_to_metric_set(metric_set, scored_df, y_true_column, y_prediction_column) # Add metrics where the housing_median_age column is greater than 30 old_homes_subset = {'median_house_value': 'Old (>30)'} old_houses_scored_df = scored_df[scored_df['housing_median_age'] > 30] add_numeric_metrics_to_metric_set(metric_set, old_houses_scored_df, y_true_column, y_prediction_column, old_homes_subset) add_residuals_scatter_plot_to_metric_set(metric_set, old_houses_scored_df, y_true_column, y_prediction_column, old_homes_subset) # Add metrics where the housing_median_age column is less than or equal to 5 new_homes_subset = {'median_house_value': 'New (<=5)'} new_houses_scored_df = scored_df[scored_df['housing_median_age'] <= 5] add_numeric_metrics_to_metric_set(metric_set, new_houses_scored_df, y_true_column, y_prediction_column, new_homes_subset) add_residuals_scatter_plot_to_metric_set(metric_set, new_houses_scored_df, y_true_column, y_prediction_column, new_homes_subset) metric_set.save(metrics_output) # Save this MetricSet in to the TransformsOutput def get_model_scores(model, df): return model.transform(df) # Create predictions based on the model def add_numeric_metrics_to_metric_set( metric_set, scored_df, y_true_column, y_prediction_column, subset=None ): import numpy as np from sklearn.metrics import mean_squared_error, r2_score y_true = scored_df[y_true_column] y_pred = scored_df[y_prediction_column] # Compute metrics mse = mean_squared_error(y_true, y_pred) rmse = np.sqrt(mse) r2 = r2_score(y_true, y_pred) metric_set.add(name='rmse', value=rmse, subset=subset) # rmse is a float metric_set.add(name='r2', value=r2, subset=subset) # r2 is a float def add_residuals_scatter_plot_to_metric_set( metric_set, scored_df, y_true_column, y_prediction_column, subset=None ): import matplotlib.pyplot as plt y_true = scored_df[y_true_column] y_pred = scored_df[y_prediction_column] scatter_plot = plt.scatter((y_true - y_pred), y_pred) # Create a scatter plot figure = plt.gcf() # Gets the current pyplot figure metric_set.add(name='scatter_plot', value=figure, subset=subset) # figure is a pyplot image plt.close() # Close the pyplot figure
Updating metrics
As the above code snippets create transforms, the metric sets are created and computed via Foundry Builds. When a model is updated, or a new input data version becomes available, it is important to rebuild the metric set to update the metrics that are associated with that model.