- Capabilities
- Getting started
- Architecture center
- Platform updates
Automatically evaluate models
As modeling projects mature, scale, and become operational, it is critical to evaluate and compare current and new model submissions systematically. Model submissions should be evaluated consistently, using well-maintained representative data against well-defined metrics.
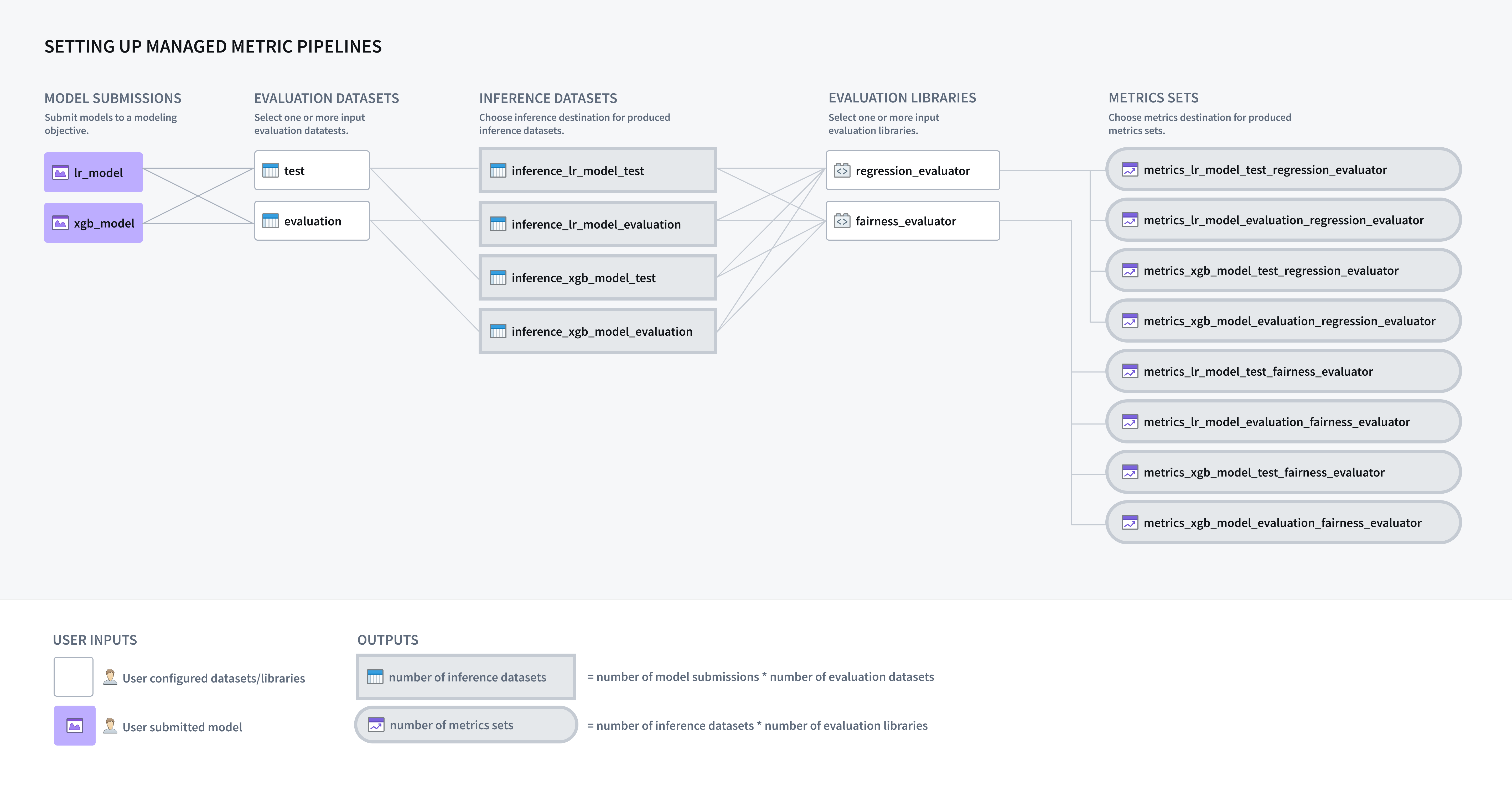
A modeling objective can be configured to automatically generate inference and metrics pipelines for all models submitted to that objective, enabling you to implement a systematic testing and evaluation (T&E) plan in software.
Configure model evaluation
To enable automatic model evaluation you must first configure your modeling objective on how to evaluate models that are submitted to your modeling objective.
Enable pipeline management
The first step of configuring automatic model evaluation in a modeling objective is to enable inference and metrics generation. From the Modeling Objectives home page, select Configure evaluation dashboard or, if you have already configured model evaluation, select Edit evaluation configuration from the Evaluation dashboard.
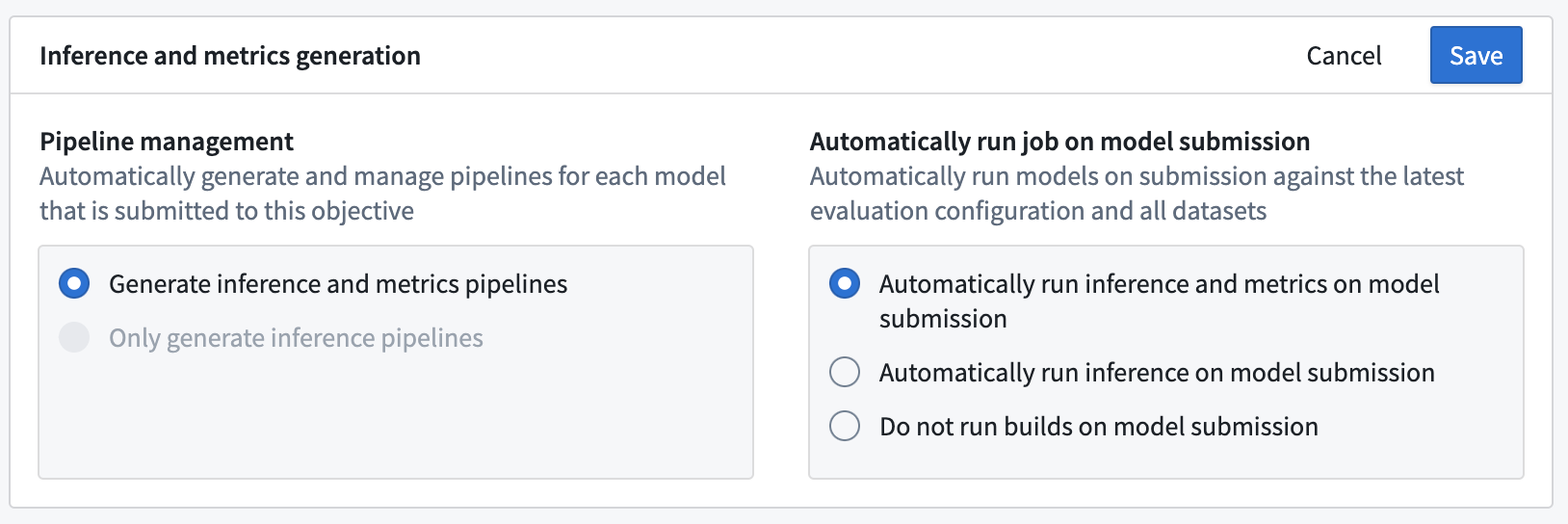
In the evaluation dashboard configuration view, you can decide whether to automatically generate inference and metrics pipelines or to only generate inference pipelines. Depending on your selection, inference and metrics datasets will be generated for all existing model submissions as well as for any new model submissions to the modeling objective.
Configure automatic model inference or evaluation
Next, you can decide whether to automatically build inference or inference and metrics datasets when a new model is submitted. Automatically building inference and metrics datasets ensures that all models that are considered for use in a modeling project are evaluated consistently.
Inference and metrics pipelines are only built on model submission. For existing model submissions, you will need to manually initiate builds via the Build evaluation button on the evaluation dashboard.
Click Save to save inference and metrics generation settings.
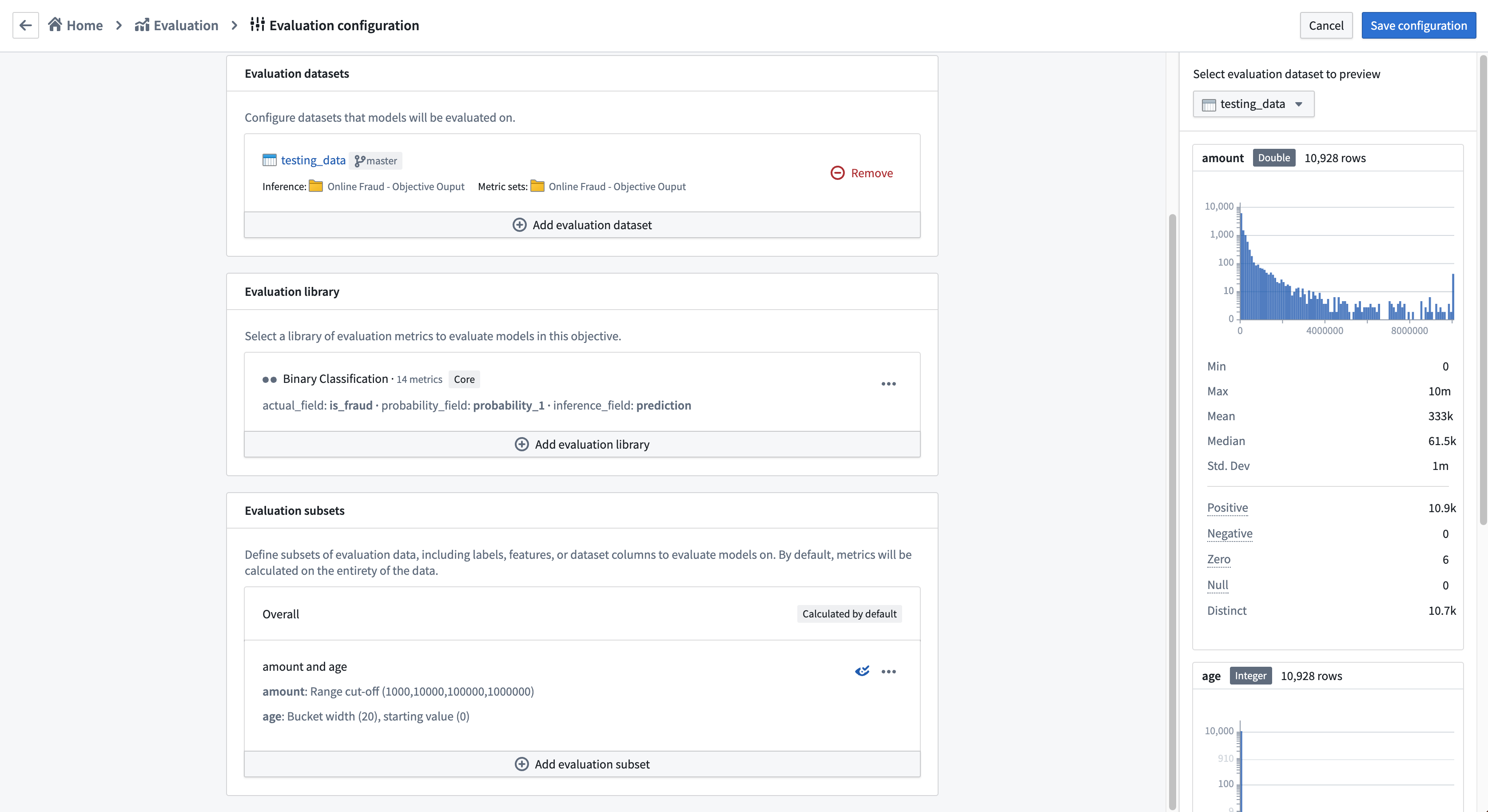
Add evaluation datasets
An evaluation dataset is a Foundry dataset that a model will be evaluated against inside a modeling objective. If the modeling objective is configured to automatically generate inference pipelines, one inference dataset will be generated for every combination of model submission and evaluation dataset. Each evaluation dataset should be relevant and carefully maintained; it might include curated validation or test sets, production observations, user feedback instances, key test cases, or representations of hypothetical scenarios. Evaluation datasets should have the dataset fields or files required for the model to run inference from.
Evaluation datasets can have different sizes, update cadences, and permissions; keeping these datasets separate enables greater control on the cadence and permissioning of computed metrics.
Permissions are fully respected inside a modeling objective. Users cannot see models, evaluation datasets, evaluation libraries, or metrics without having the proper access.
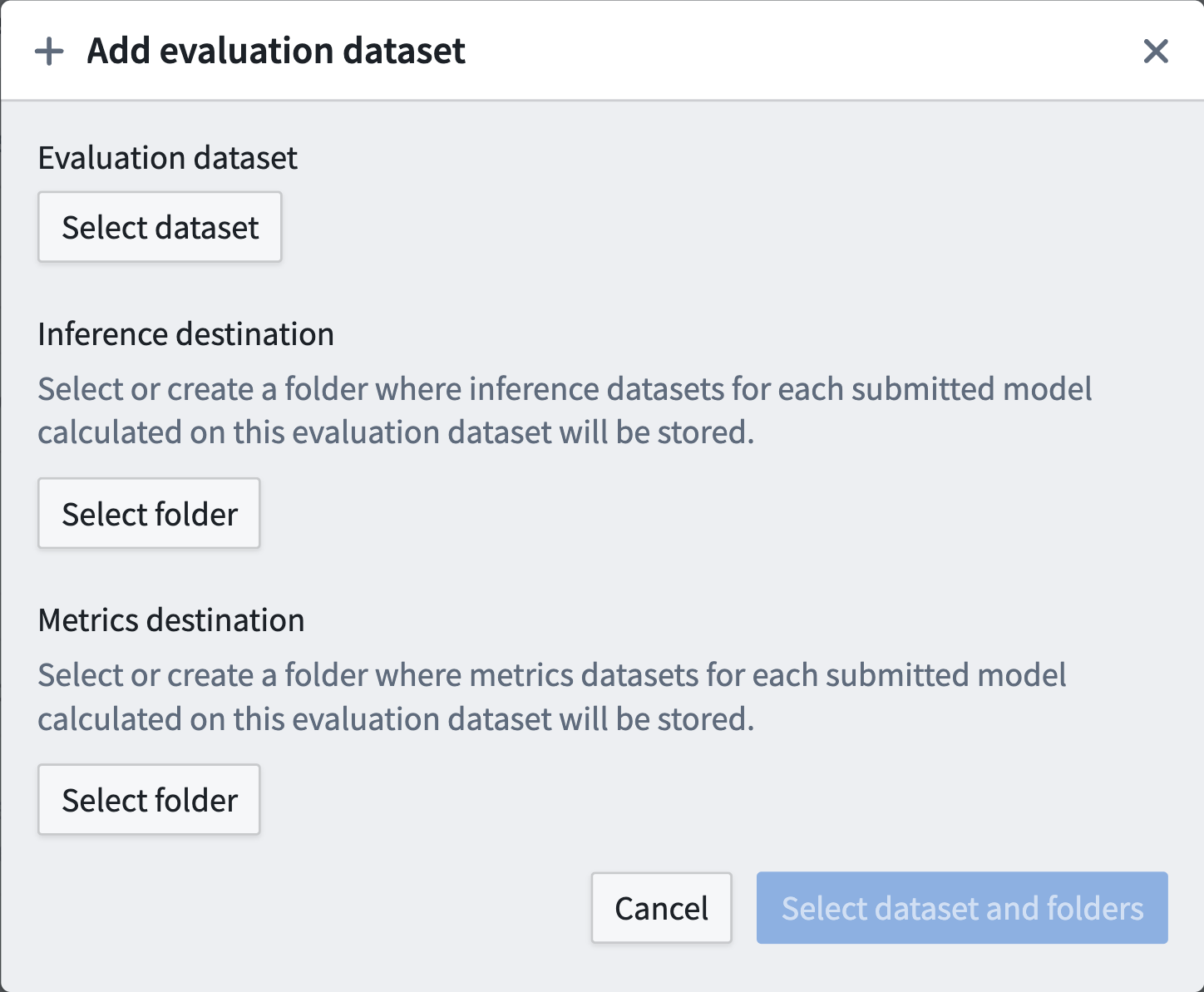
To configure an evaluation dataset, select Add evaluation dataset. A pop-up will allow you to configure:
- The evaluation dataset.
- The Foundry folder where inference datasets should be generated for this evaluation dataset.
- The Foundry folder where metrics datasets should be generated for this evaluation dataset.
The Foundry folders can be new or existing folders and are not required to be unique for evaluation datasets. Typically, we recommend one output folder per modeling objective, but this can be configured for your particular use case.
The evaluation dataset and the objective itself are required to be in the same Foundry Project as the inference and metrics destinations, or they should be added to the Foundry Project as a reference.
Automatic model evaluation in Modeling Objectives is only compatible with models that have a single tabular dataset input.
Configure evaluation libraries
If you have configured your modeling objective to generate metrics and inference pipelines, the next step is to configure an evaluation library. An evaluation library is a published Python package in Foundry that produces a model evaluator. Foundry comes with default model evaluators for binary classification and regression, and also allows you to build a custom model evaluator. Evaluation libraries are used to measure model performance, model fairness, model robustness, and other metrics.
When configured, an evaluation library will generate one dataset containing a metric set for every configured inference dataset.
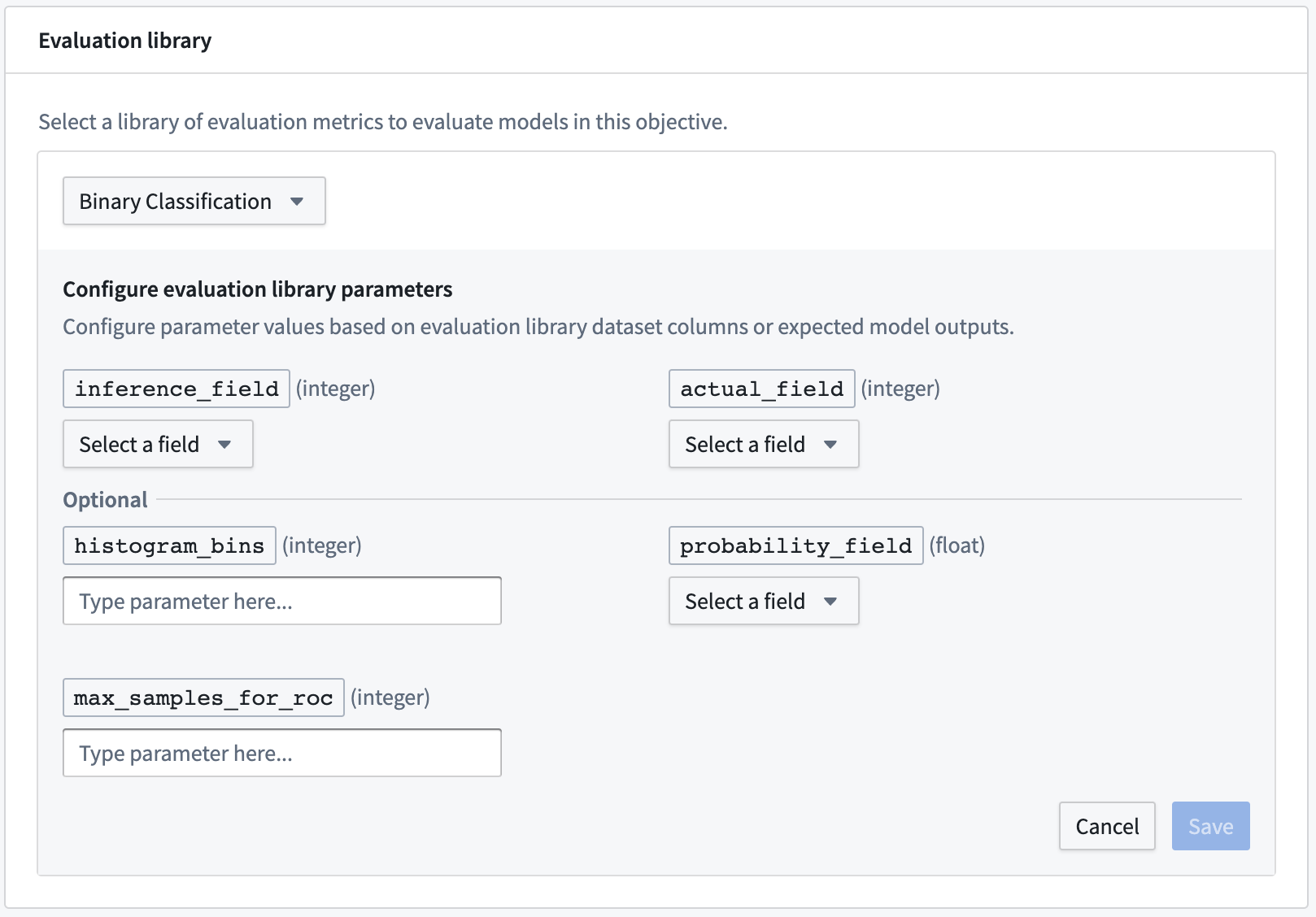
To configure an evaluation library, click Select evaluation library, select an evaluation library, and then configure the fields that are expected for that model evaluator. For column input types, the modeling objective will suggest columns that are available in any evaluation dataset. Additionally, you can also Add an expected model output to represent a column that a model submission is expected to produce if you do not see it suggested in the dropdown or know that it will be generated by the model transform.
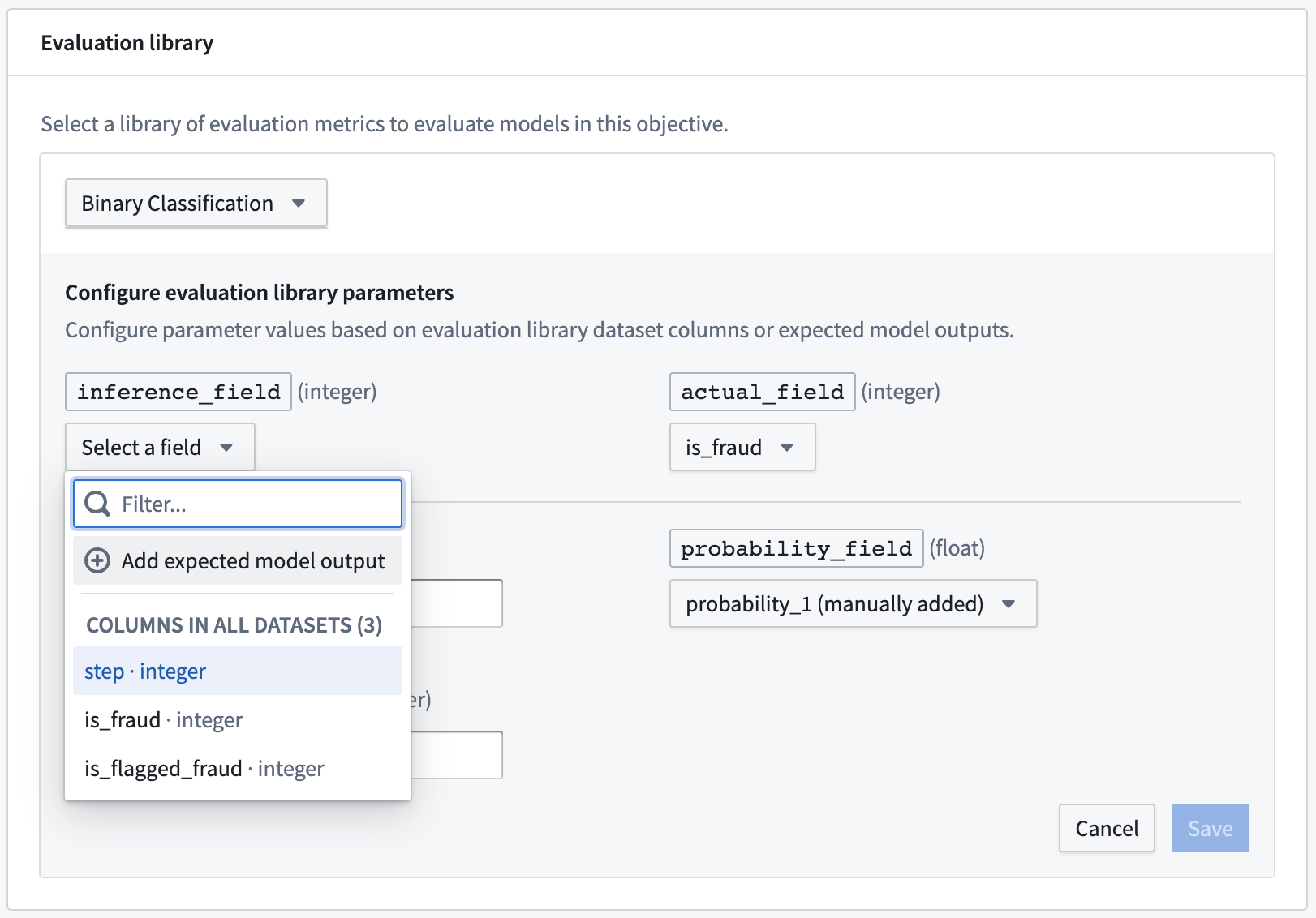
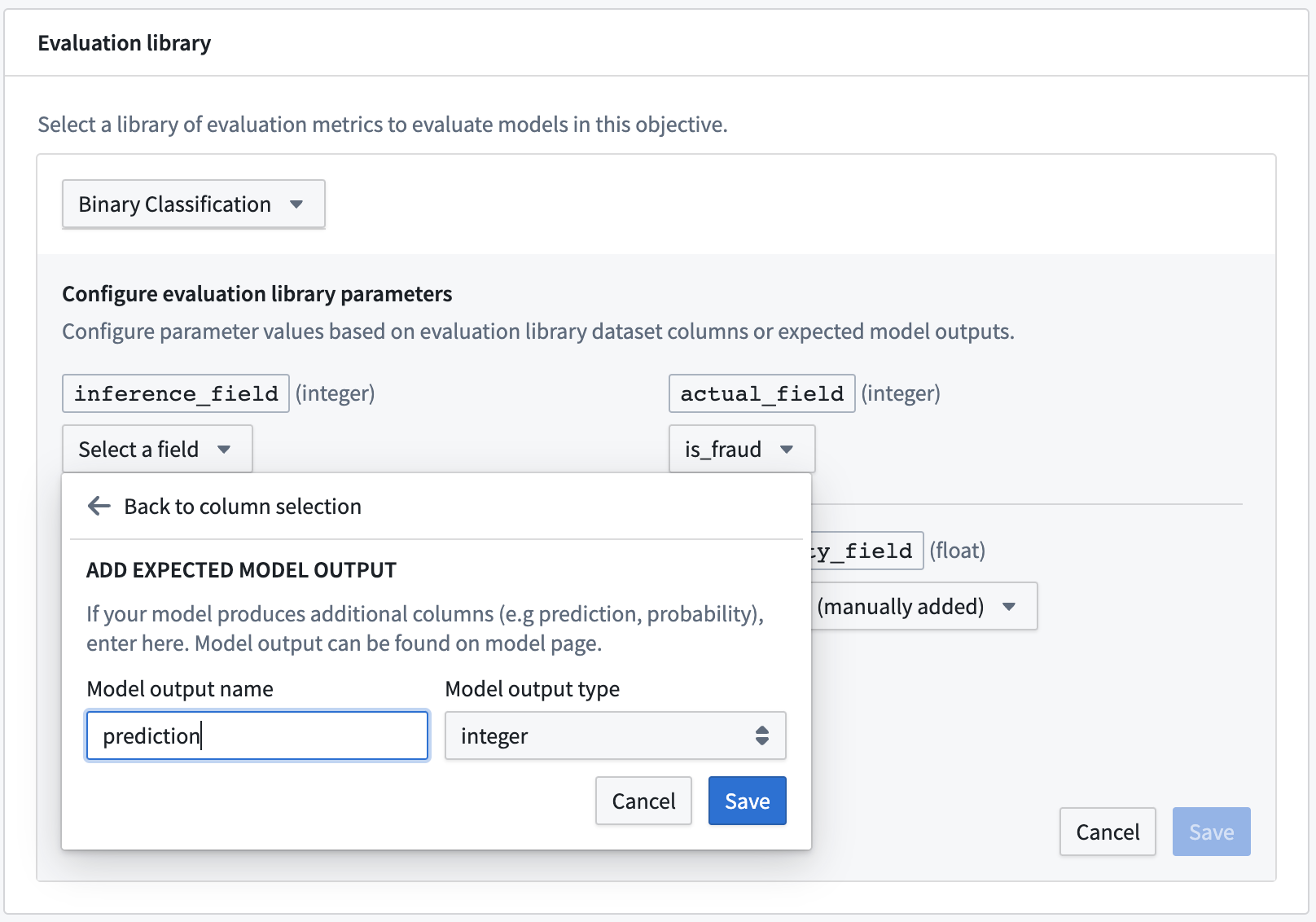
The most common types of expected model outputs are prediction outputs (often named prediction), probability outputs (often named probability_1), and confidence scores.
Configure evaluation subsets
An optional step in configuring automatic model evaluation is to define the evaluation subsets for your evaluation libraries to generate metrics against. An evaluation subset is a subset of the data in an evaluation dataset for which metrics will be separately generated. The metrics for an evaluation subset can be analyzed individually through the evaluation dashboard.
Evaluation subsets are useful to understand how a model performs on a specific group of input data and can therefore be used to improve model interpretability, explainability, and fairness across potentially protected classes. Evaluation subsets can be generated on any column of an evaluation dataset and, therefore, are not required to be generated on an input to or output of a model transformation, such as a model feature or a model prediction.
Metrics will always be generated against the entirety, every row, of each evaluation dataset in the "Overall" subset. It is optional to configure evaluation subsets for automatic metrics generation on further subsets.
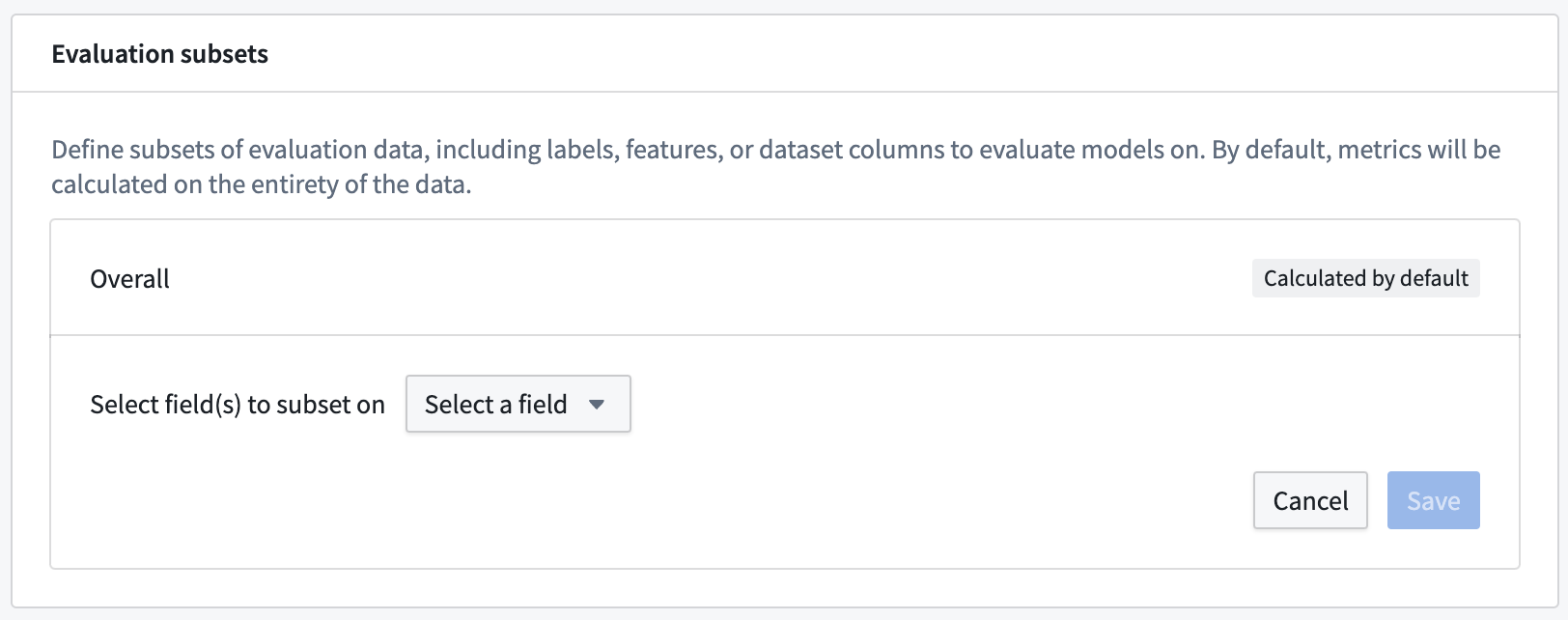
To configure an evaluation subset, click Add evaluation subset and select the evaluation dataset column or expected model output for which to create a subset.
Classification buckets
If you select a field from the evaluation subset that is of type string, a unique subset will be generated for each unique string value in the evaluation library at the time the evaluation pipeline is built.
Quantitative buckets
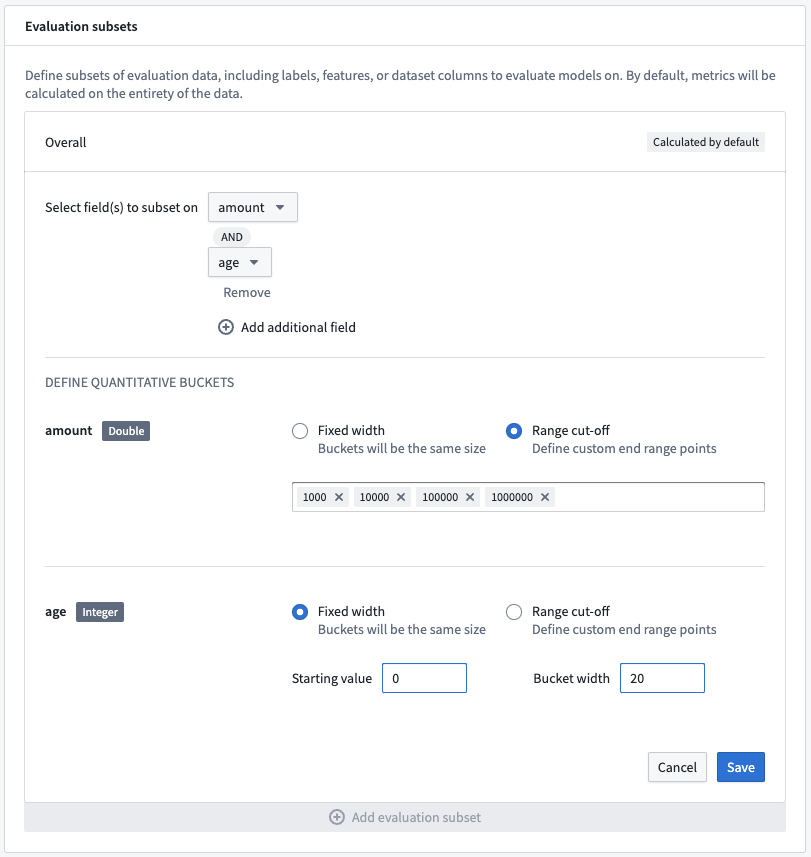
If you select a field from the evaluation subset that is a numeric type, you can select the quantitative bucketing strategy used to generate subsets. The buckets can either be of Fixed width or defined with specific Range cut-offs. Both bucketing strategies create buckets that are defined:
- From and including the lower-bound, as well as
- Up to but excluding the upper-bound.
For a fixed-width bucket you must provide both a Starting value and a Bucket width. A unique subset will be generated for every bucket width, both positively and negatively, for the entity of the range of the selected field.
A range cutoff will generate subsets that range between all values you specify. If you do not cover the entire range of the selected field, two additional buckets may be generated from the column minimum to the lowest cutoff and from the largest cutoff to the column maximum value.
Every unique subset is evaluated with every evaluation dataset and library. As a result, generating a large number of subsets may significantly increase build times for model evaluation.
Multi-field subsets
It is possible to generate subsets that represent the combination of multiple fields. Click Add additional field on multiple fields to select multiple columns or expected model outputs to combine into a single subset. This will create a subset for every combination of bucket between fields.
The quantitative bucketing strategy can be uniquely defined for each subset field.
Review evaluation subset preview
When you configure an evaluation subset, you will see a preview of the evaluation dataset on the right hand side of the page. This preview is available for every evaluation dataset that you have configured and can be used to determine how many evaluation subsets will be generated by your evaluation configuration.
Save evaluation configuration
Click Save configuration in the upper right corner of the page to save the evaluation configuration and return to the evaluation dashboard.