- Capabilities
- Getting started
- Architecture center
- Platform updates
MetricSets reference [Planned deprecation]
Metric sets were built for dataset-backed models using foundry_ml, a library which has been formally deprecated since October 31, 2025. For new implementations, we recommend using experiments instead. While metric sets will not appear on the model page for a model built with palantir_models, it is still possible to write metric sets against a model and view the metrics in Modeling Objectives.
A metric set serves as a container for named metrics which we define as any summarization of a model's output. Supported metrics include numerical, charts, and images.
In Python, metric sets are implemented via the MetricSet class within the foundry_ml_metrics package (requires foundry_ml within the environment configuration).
All metrics are addable via the MetricSet.add method with the following parameters:
nameThe string name of the metricvalueThe value of the metric you want to addsubsetAdict<str, str>describing the subset of data this metric is forstageA Foundry ML model stage or stage uuid to tie this to a specific stage, defaults to the last model stage
Below is an example of creating an empty metric set to illustrate the concept.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25import foundry_ml_metrics def Metrics(Model, validation_hold_out): # Initialize the MetricSet with the model and input data metric_set = foundry_ml_metrics.MetricSet( model = Model, input_data=validation_hold_out ) val_df = validation_hold_out.dataframe() # Run the model on the dataset to get the inference results inference_results = Model.transform(val_df) # Compute metrics y_true, y_pred = ... acc = ... f1 = ... # Add metrics to MetricSet metric_set.add(name='Accuracy', value=acc) metric_set.add(name='F1 Score', value=f1) return metric_set
On creation, you must pass the model and input_data parameters to MetricSet.
To save a metric set, return it as you would a model. The example above represents the approach for saving from a Code Workbook.
MetricSets in Code Repositories
We recommend replacing metric sets with experiments where possible. This feature is only made available for backcompability purposes for models that were initially built as dataset-backed models and should not be used for new implementations.
While metric sets will not appear on the model page for a model built with palantir_models, it is still possible to write metric sets against a model and view the metrics in Modeling Objectives.
To do so, author your model in Code Repositories and add the foundry_ml_metrics library to your environment. Here is an example of how to use a metric set in conjunction with palantir_models:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26import uuid from transforms.api import transform, Input, Output from palantir_models.transforms import ModelInput from foundry_ml_metrics import MetricSet # add foundry_ml_metrics to your environment @transform( evaluation_data_input=Input("path_to_input"), model_input=ModelInput("path_to_model"), metric_set_output=Output("path_to_output"), ) def compute(training_data_input, model_input, metric_set_output): metric_set = MetricSet( # Pass the "hash" part of the model version identifier, for example, given # ri.models.main.model-version.6c0f17a8-ad73-46a4-b86e-8d0a13327ef2, # only pass 6c0f17a8-ad73-46a4-b86e-8d0a13327ef2. model=uuid.UUID( # The model_version_rid property is only available on the ModelInput class # for versions of palantir_models greater or equal to 0.1602.0. model_input.model_version_rid.replace("ri.models.main.model-version.", "") ), input_data=evaluation_data_input ) metric_set.add(name='Accuracy', value=0.8) metric_set.add(name='F1', value=0.95) metric_set.save(metric_set_output)
Next, configure the evaluation_data_input dataset as an evaluation dataset in Modeling Objectives' evaluation configuration. The metrics will then appear under that dataset in Modeling Objectives' evaluation view.
Input dataset
The input dataset is an explicit reference to the specific version of data that the model was applied to, which metrics were then computed on. By tracking these manually, you create a record and full provenance of a model's performance. This feature is necessary when evaluating many models against each other in a Modeling objective, to ensure that those models are being evaluated against the same data.
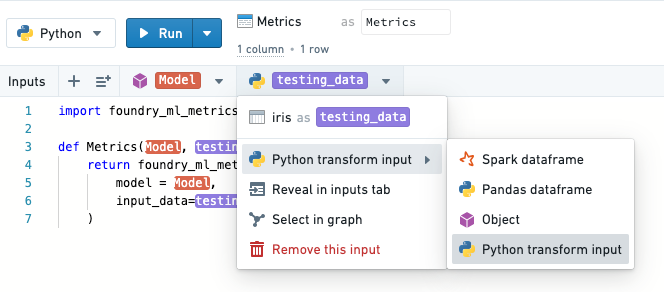
Input datasets must be passed as type Python transform input into MetricSets in order to get the appropriate metadata. Note: Code Workbook only supports this for imported datasets. Aligned with best practices, we must do the validation in a separate workbook from the test/train split.
Metric Types
Numerical metrics
Numerical metrics are the most basic metric type and are typically an analyst's first insight into model performance.
Numerical metrics are simply python int or float types and are simply added to the metric set.
Copied!1metric_set.add(name='My numeric metric', value=1.5)
Chart metrics
Charts provide visualizations of model performance beyond simple numerical metrics.
foundry_ml provides the ability to directly save data to back charts in a variety of formats.
Since the data is saved this allows superior model comparison ability, particularly in Modeling objectives.
All supported charts are created by functions in the foundry_ml_metrics.charts package.
Consider an example:
Copied!1 2 3 4 5 6 7import foundry_ml_metrics.charts line_chart = foundry_ml_metrics.charts.line(xs=[0.0, 1.0], ys=[1.0, 0.0]) bar_chart = foundry_ml_metrics.charts.bar(xs=["category 1", "category 2"], ys=[0.56, 0.41]) metric_set.add(name='My line chart', value=line_chart) metric_set.add(name='My bar chart', value=bar_chart)
Image metrics
Python has a plethora of open source plotting libraries capable of saving images.
To take advantage of this, foundry_ml allows you to provide matplotlib and seaborn compatible image objects as metric values.
Copied!1 2 3 4from matplotlib import pyplot pyplot.plot([0, 1], [1, 0]) matplotlib_plot = pyplot.gcf() metric_set.add(name='My image chart', value=matplotlib_plot)
Validation data subsets
Often model performance varies across distinct subsets of a dataset.
To aide in analyzing this the MetricSet.add method accepts a subset parameter,
a python dictionary of strings -> strings describing any filters you applied. The semantic names for filters helps users understand their model performance on different slices of data that represent real world problems.
Metrics and subsets will appear in Modeling objectives.
For example, perhaps on classic open source iris data you are computing accuracy of your model on below average and above average petal lengths.
This can be done by:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20def compute_accuracy(testing_df): # An implementation of accuracy compute_accuracy = ... metric_set = foundry_ml_metrics.MetricSet( model = Model, input_data=testing_df ) # Compute scores on all data predictions = Model.transform(testing_df) # subset = {} indicates overall, the default metric_set.add(name='accuracy', subset={}, value=compute_accuracy(predictions)) # Filter data predictions_long = predictions.filter('sepal_length > 3') metric_set.add(name='accuracy', subset={'sepal_length': 'long'}, value=compute_accuracy(predictions_long)) predictions_short = predictions.filter('sepal_length < 3') metric_set.add(name='accuracy', subset={'sepal_length': 'short'}, value=compute_accuracy(predictions_short))
An arbitrary number of fields can be provided to the subset dictionary.
Updating metrics
Metric sets are represented as datasets, and are computed via Foundry Builds. When a model is updated in-place, or a new input data version becomes available, you must re-build the metric set, since it is associated with specific versions of the model and the input dataset.
Importantly, if you update and re-run a model, you'll also need to re-build linked metric sets to prevent stale information since they are associated with specific model (and input dataset) versions. Otherwise, you will not see metrics within the Model Preview.