- Capabilities
- Getting started
- Architecture center
- Platform updates
Custom evaluation library
An evaluation library is a published Python package in Foundry that produces a model evaluator. Evaluation libraries are used to measure model performance, model fairness, model robustness, and other metrics in a reusable way across different modeling objectives.
In addition to Foundry's default model evaluators for binary classification and regression models, Foundry also allows you to create a custom model evaluator that can be used natively in a modeling objective.
Custom evaluator inside a modeling objective
A custom evaluator, its configuration options, and produced metrics will be displayed in the Modeling Objectives application with the names and descriptions that are specified in the docstring at the top of the evaluator implementation.
Once the custom evaluator has been published, it will be available in the Modeling Objective application to any users with view access to the published library. This enables you to write reusable logic for calculating standardized metrics across your organization.
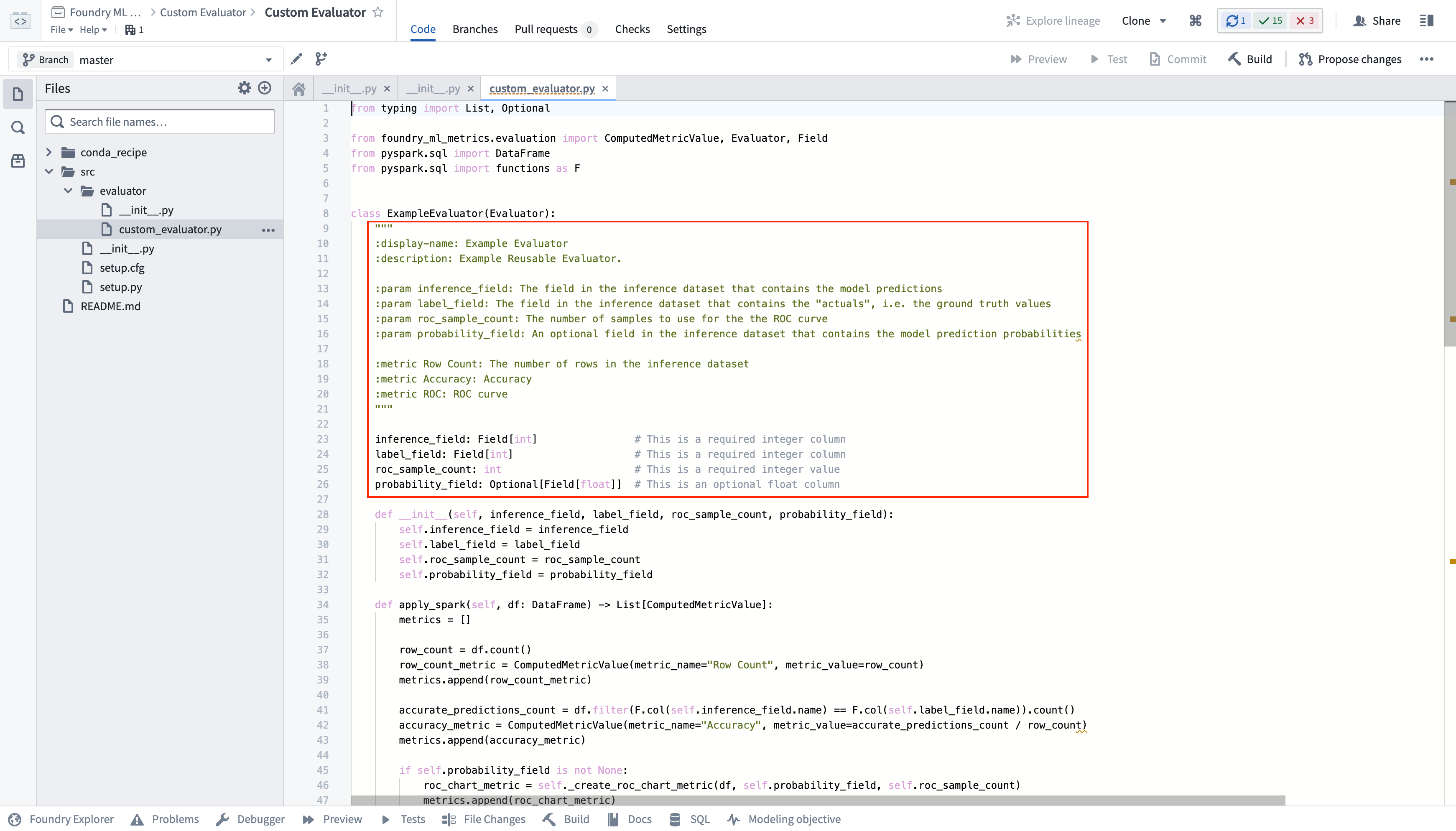
The custom evaluator is selectable inside the evaluation library configuration of a modeling objective; that library is configurable based on the parameter defined by the evaluator.
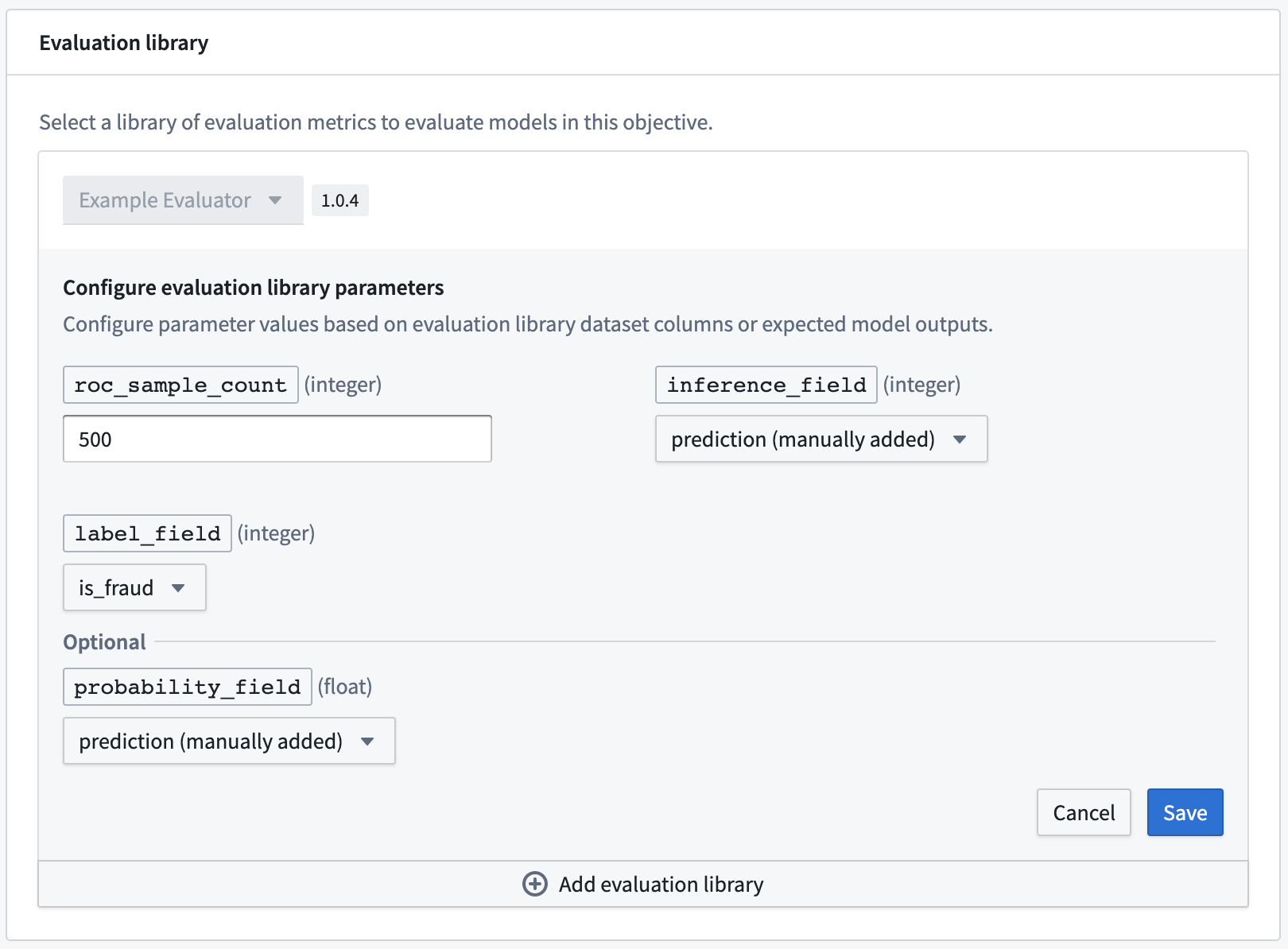
Create a custom evaluator
To create a custom evaluator:
- Create a code repository from the
Model Evaluator Template Library. - Implement your custom evaluator.
- Add parameters to your custom evaluator.
- Commit and publish a new tag with your changes.
Create a code repository
The Code Repositories application has many template implementations; here, we'll be using the Model Evaluator Template Library. Navigate to a Foundry Project, select + New > Repository type > Model Integration > Language template, select Model Evaluator Template Library, and finally select Initialize repository.
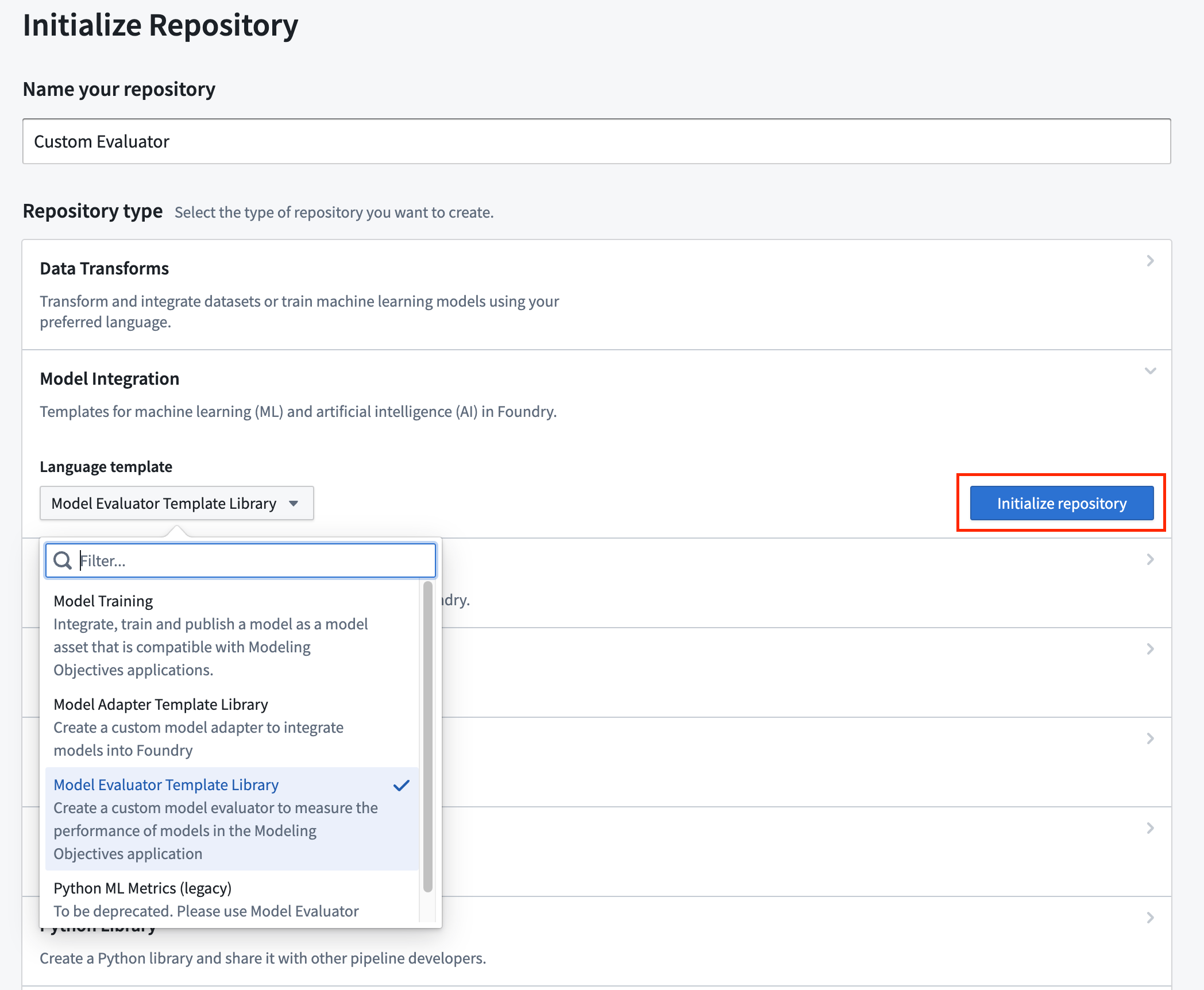
Evaluator template structure
The Model Evaluator Template Library has an example implementation in the file src/evaluator/custom_evaluator.py. Any implementation of the Evaluator Python interface will automatically be registered and made available when you publish a new version of its repository with a new repository version tag.
A repository that contains custom evaluator logic can publish multiple evaluators. Any additional evaluator implementation files will need to be added as a reference to the list of model evaluator modules in the build.gradle of the evaluator template.
Implement a custom evaluator
To implement a custom evaluator, you need to create an implementation of the Evaluator interface and optionally provide configuration fields for interpretation by the Modeling Objectives application.
In the evaluator template library, add your evaluator to the file src/evaluator/custom_evaluator.py.
Evaluator interface
The interface of an evaluator is defined:
Copied!1 2 3 4 5 6 7 8 9 10 11class Evaluator(): def apply_spark(self, df: DataFrame) -> List[ComputedMetricValue]: """ Applies the evaluator to compute metrics on a PySpark Dataframe. :param df: The PySpark DataFrame to compute metrics on :return: A list of computed metric values """ pass
To use your newly configured custom evaluator in the Modeling Objectives application, you will first need to publish a new version of its repository, providing it with a new repository version tag.
Evaluator documentation
A custom evaluator and its configuration options and produced metrics will be displayed in the Modeling Objectives application with the names and descriptions that are specified in the docstring at the top of the implementation.
The required values are:
display-name: The display name of the evaluatordescription: The description of the evaluator
You can optionally add zero or more of the following:
param: A configuration parameter of your custom evaluatormetric: A metric produced by your evaluator
Example evaluator implementation
This is an example evaluator that calculates the row count of the input dataset.
This example evaluator will be displayed in the Modeling Objectives application with:
- The title
Row Count Evaluator. - The description
This evaluator calculates the row count of the input DataFrame. - The produced metric
Row Countthat has the descriptionThe row count. - Zero configuration parameters.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21from pyspark.sql import DataFrame from pyspark.sql import functions as F from foundry_ml_metrics.evaluation import ComputedMetricValue, Evaluator class CustomEvaluator(Evaluator): """ :display-name: Row Count Evaluator :description: This evaluator calculates the row count of the input DataFrame. :metric Row Count: The row count """ def apply_spark(self, df: DataFrame) -> List[ComputedMetricValue]: row_count = df.count() return [ ComputedMetricValue( metric_name='Row Count', metric_value=row_count ) ]
Parameterize an evaluator
An evaluator can be made configurable in the Modeling Objectives application by providing configuration parameters. The configuration parameters will be populated by the Modeling Objectives application with the user-entered value at run time. A user of this evaluator will have the opportunity to configure the values of the parameters when they configure automated evaluation in a modeling objective.
The allowed configuration fields are:
int: An integer numberfloat: A floating point numberbool: A Boolean value (True or False)str: A string valueField[float]: A floating point column in the input DataFrameField[int]: A integer column in the input DataFrameField[str]: A string column in the input DataFrame
Parameters can be made optional by wrapping them in Optional (from the built-in typing package).
For example:
- An optional
strwould beOptional[str] - An optional
Field[str]would beOptional[Field[str]]
Example evaluator with configuration fields
This is an example evaluator that calculates the row count of the input dataset and the row count when the input dataframe has been filtered such that the input column column has the value value.
This example evaluator will be displayed in the Modeling Objectives application with:
- The title
Configurable Row Count Evaluator. - The description
This evaluator calculates the row count of the input DataFrame, filtered to the specified value. - A produced metric
Row Countthat has the descriptionThe unfiltered row count. - A produced metric
Filtered Row Countthat has the descriptionThe filtered row count - Two configuration parameters:
- A column in an evaluation dataset that must be an integer with the name
columnand the descriptionFiltered column. - An integer value with the name
valueand the descriptionFiltered value.
- A column in an evaluation dataset that must be an integer with the name
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43from pyspark.sql import DataFrame from pyspark.sql import functions as F from foundry_ml_metrics.evaluation import ComputedMetricValue, Evaluator, Field class CustomEvaluator(Evaluator): """ :display-name: Configurable Row Count Evaluator :description: This evaluator calculates the row count of the input DataFrame, filtered to the specified value. :param column: Filtered column :param value: Filtered value :metric Row Count: The unfiltered row count :metric Filtered Row Count: The filtered row count """ column: Field[int] value: int def __init__(self, column: Field[int], value: int): self.column = column self.value = value def apply_spark(self, df: DataFrame) -> List[ComputedMetricValue]: column_name = self.column.name column_value = self.value row_count = df.count() filtered_row_count = df.filter( F.col(column_name) == column_value ).count() return [ ComputedMetricValue( metric_name='Row Count', metric_value=row_count ), ComputedMetricValue( metric_name='Filtered Row Count', metric_value=filtered_row_count ) ]
Reference classes
The below classes are provided as a reference.
Field
Fields are used as configuration parameters for your evaluator library to tell the Modeling Objective application which properties need to be implemented.
A Field has the following interface.
Copied!1 2class Field(): name: str
ComputedMetricValue
A ComputedMetricValue stores the information about a metric to attach to a Foundry model.
Copied!1 2 3 4 5 6 7 8 9 10class ComputedMetricValue(): """ Metric computed by one of the evaluators comprising metric name, value, and subset information. """ metric_name: str metric_value: MetricValue def __init__(self, metric_name, metric_value): self.metric_name = metric_name self.metric_value = metric_value
MetricValue
A MetricValue can be any of the following:
- A numeric value that is one of the types:
- int
- np.int8
- np.int16
- np.int32
- np.int64
- np.uint8
- np.uint16
- np.uint32
- np.uint64
- float
- np.float32
- np.float64
- A figure that is one of the types:
- matplotlib.Figure
- matplotlib.pyplot.Figure
- Any class that implements exactly one of the methods:
get_figure(self) -> Figure: Note that many seaborn plots implement this function.save(self, path: str): Note that many seaborn plots implement this function.savefig(self, path: str)
- A BarChart
- A LineChart