Explore model stages, features, and hyperparameters
The foundry_ml library, which is used to produce dataset-backed models, is in the planned deprecation phase of development and will be unavailable for use starting October 31, 2025. Full support remains available until the deprecation date. At this time, you should use the palantir_models library to produce model assets. You can also learn how to migrate a model from the foundry_ml to the palantir_models framework through an example.
Contact Palantir Support if you require additional help migrating your workflows.
Opening a dataset-backed model allows you to explore stages, features, and hyperparameters.
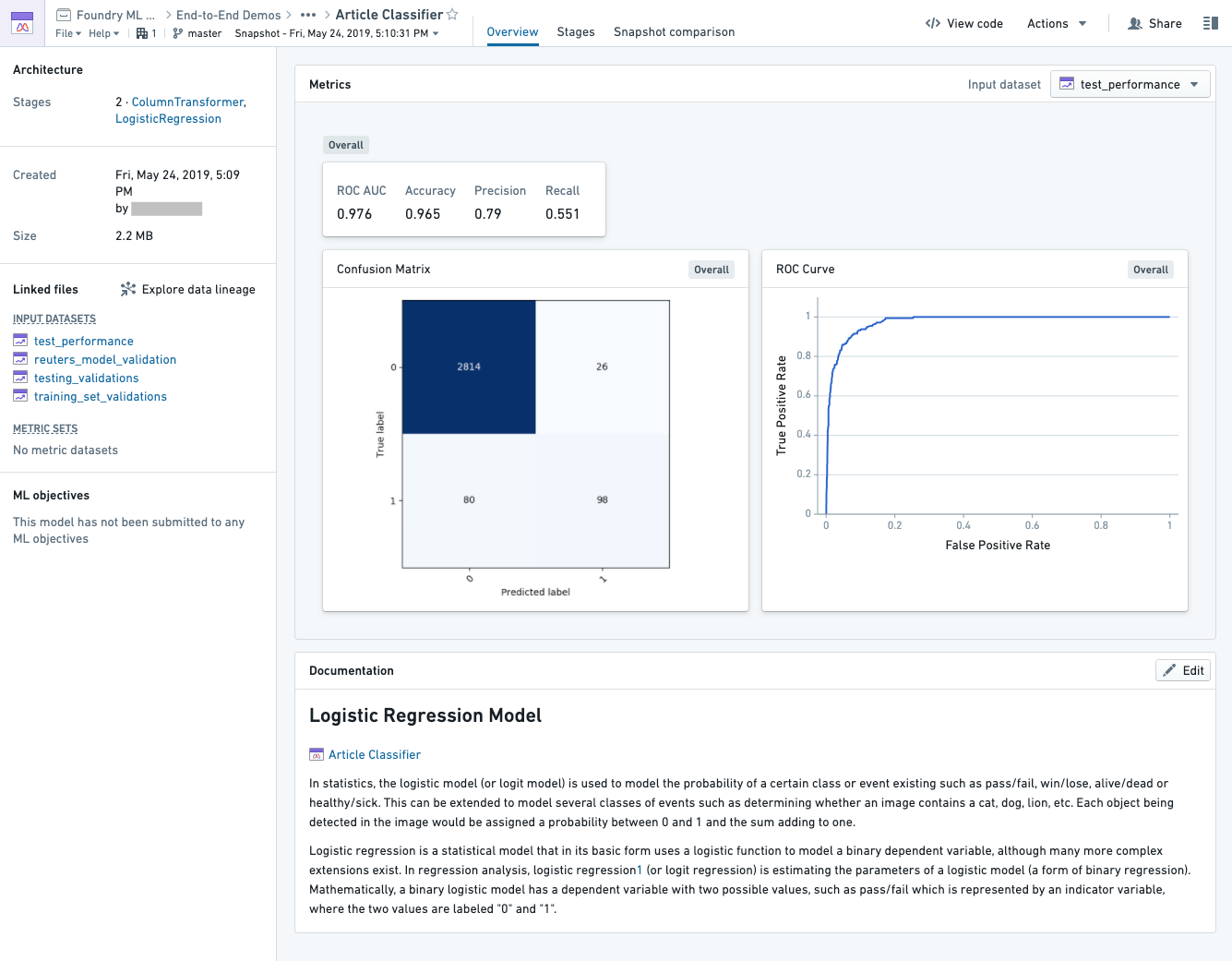
Metrics attached to the model show up on both the model overview tab and on the individual stage. Metrics or graphs on this tab can be compared across different versions and branches of a model.
Model-level aggregate metadata and any user-authored documentation is visible on this view.
Stages
This tab allows you to explore each stage and any associated metadata contained within the model with greater insight. Depending on the type of stage, there will be a subset of 4 different tabs available.
Feature Analysis
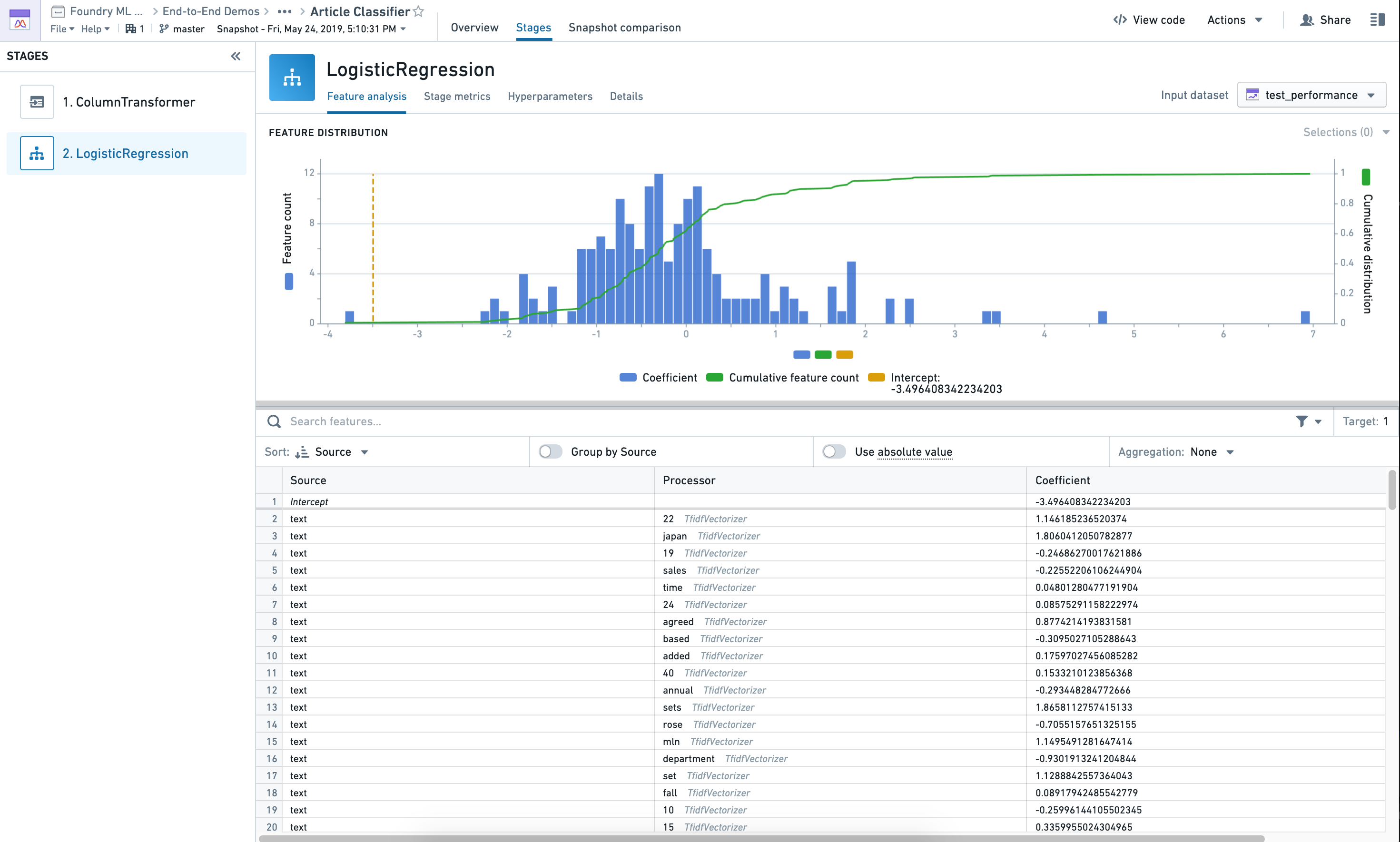
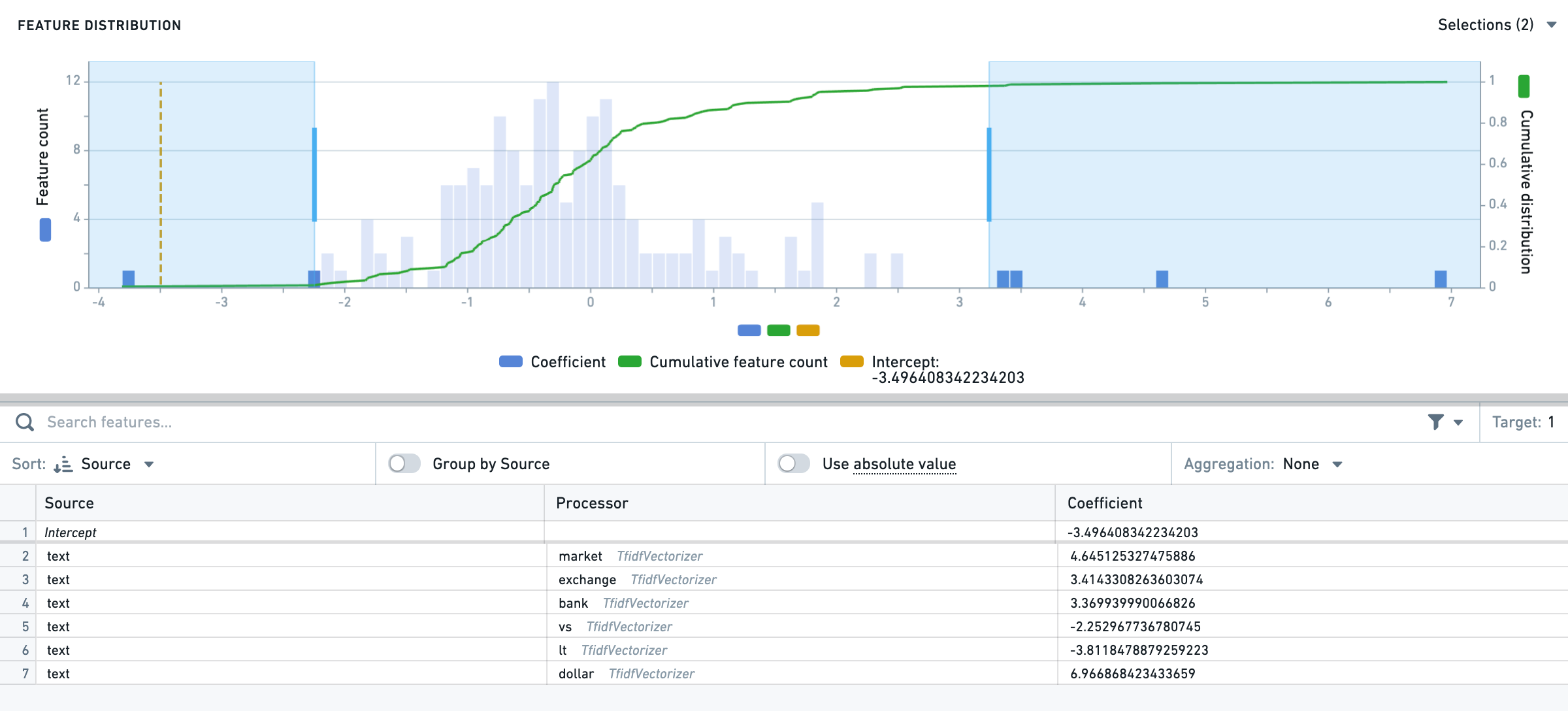
For most algorithms that have feature importances or weights, this tab will show a distribution plot as well as a table. The selections can be made on the chart, which will reflect in the table underneath it. There are many aggregation and sorting functions also available for the table.
Example of selecting bounds on the chart and the reflected changes:
Stage Metrics
Any metrics that are linked to the particular stage will show up here. Any metrics that exist only on this tab will not be able to be compared via the Snapshot Comparison tab.
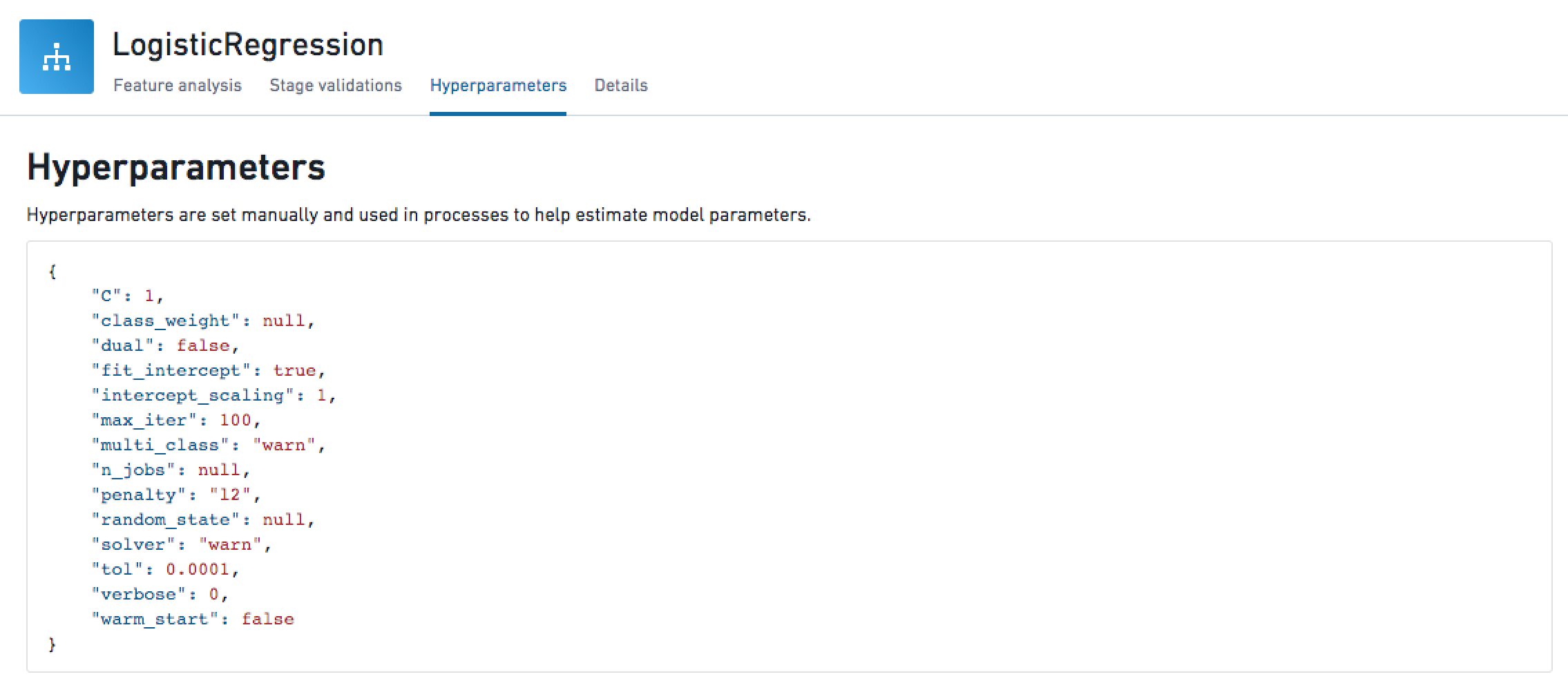
Hyperparameters
If the stage is an algorithm, the hyperparameters are shown in a pythonic format.
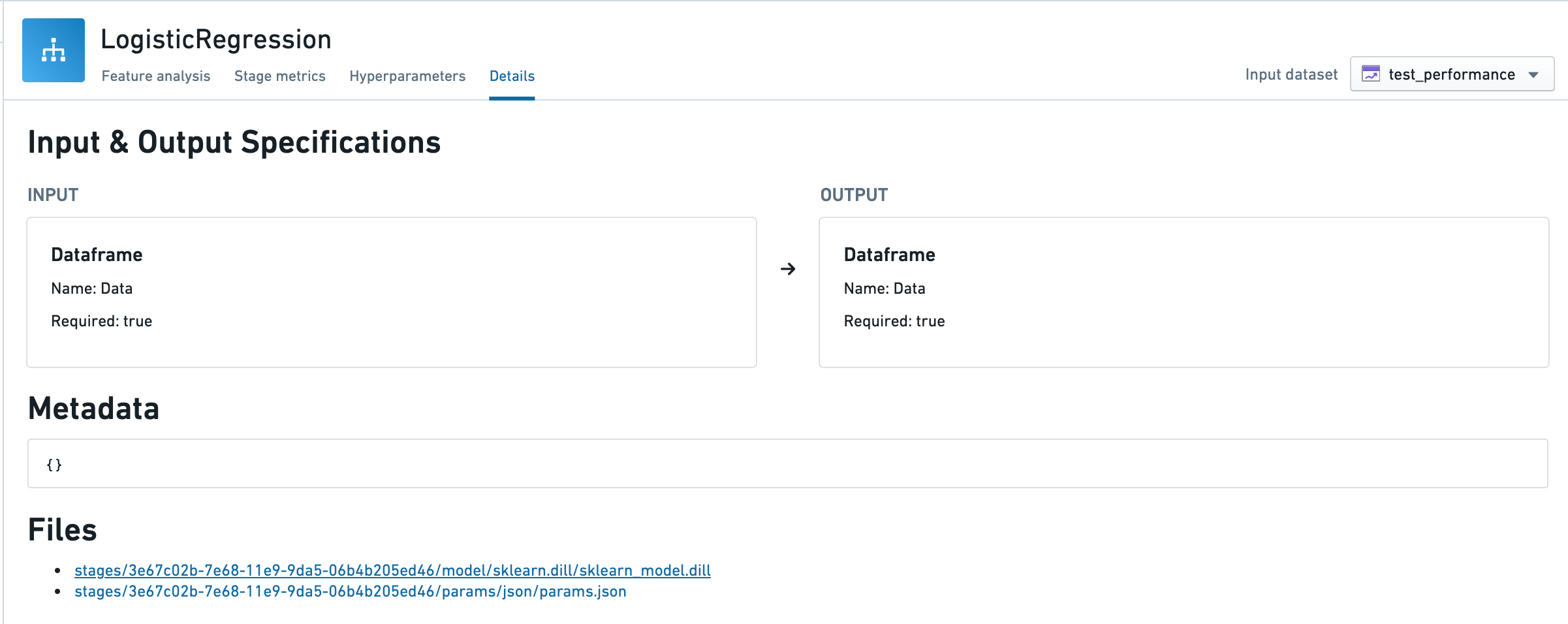
Details
This tab shows the structure of the input into the stage and result of the stage's transformation, the output. The serialized files of the stage are available here for download. They will download without any Palantir-specific dependencies for local deserialization.
Snapshot Comparison
This tab allows you to compare up to 10 different branches and transactions of the same model against a baseline snapshot. This functionality encourages and lowers the bar for collaborative data science projects. The Snapshot Comparison functionality has proven useful in particular for production models, where if there is a model in an operational pipeline, retraining and development can occur without affecting the production model until ready.
The view highlights differences in validations as well as if the structure, number/order of stages, changed.
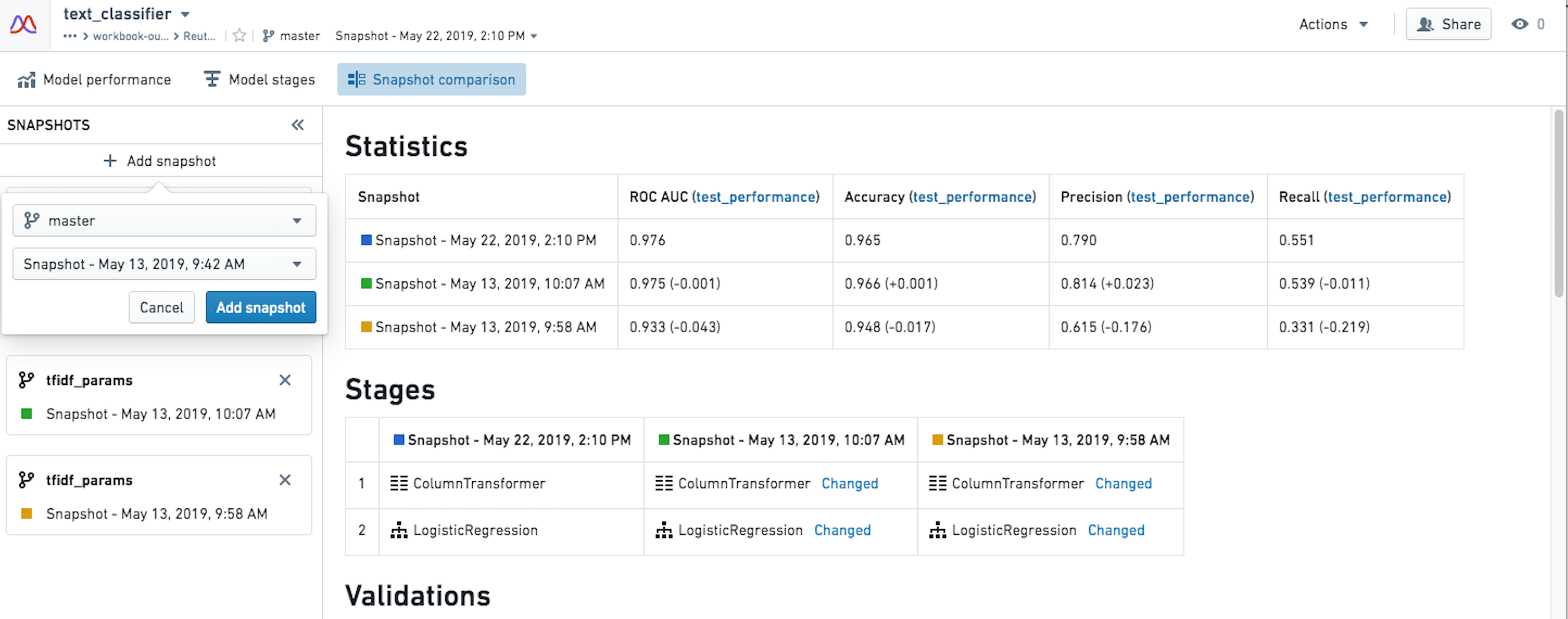
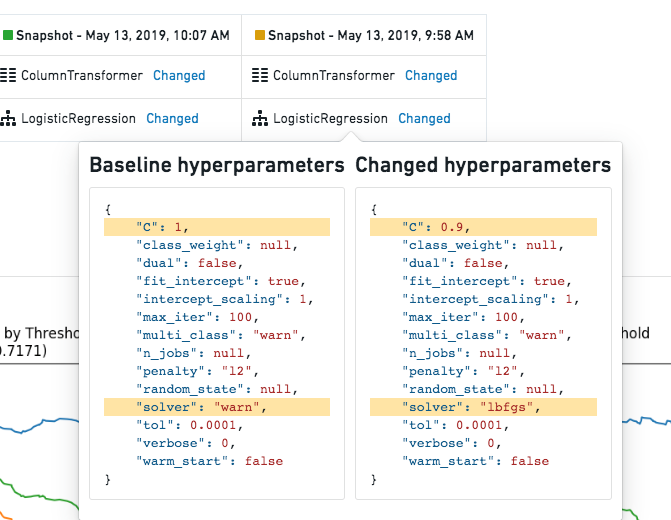
If the structure of a model stayed the same, and the hyperparameters of a stage changed, you are able to see the difference.