- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: Sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Share your thoughts about these announcements in our Developer Community Forum ↗.
Introducing interfaces, a new Ontology type [Beta]
Date published: 2024-08-27
We are excited to announce the new interface Ontology type, a primitive that allows users to describe the shape of an object type and its capabilities. Interfaces provide object type polymorphism, allowing for consistent modeling of and interaction with object types that share a common shape.
Interfaces are composed of shared properties, interface link types, and metadata about the interface. An interface can be implemented by multiple object types and can be extended to allow for composability of interfaces.
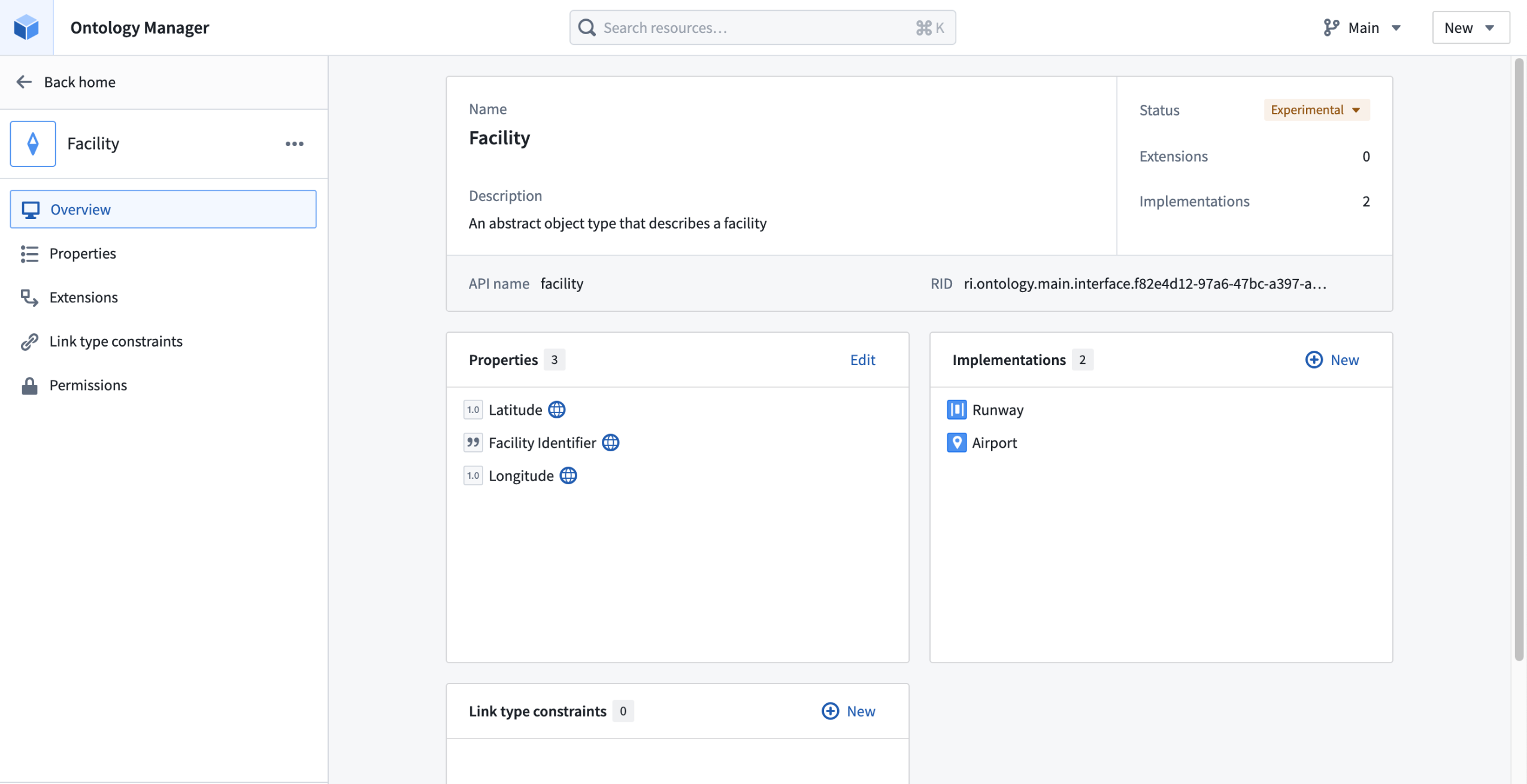
An example Facility interface in Ontology Manager.
The power of interfaces
For data integrators, an interface can represent a pipeline target for integrating similar but distinct object types. For application developers, an interface can serve as an API surface for accessing all implementing object types.
- Object Set Service searches against the interface will return matching objects of the implementing object type.
- Users can interact with objects of the implementing object type using both their local API names when typed as the concrete object type and the interface API names for properties and links when typed as the interface type.
In short, implementing an interface allows downstream applications to interact with any and all implementing objects through the interface definition. This allows users to write application code using the interface as an API layer, instead of requiring the application to support every implementing object type individually. Additionally, by using the interface as an application API layer, new object types can be added to the application by having them implement the application interface without requiring code changes to explicitly support the new object type.
Example interface: Scheduling
A common use case for interfaces is to indicate that an object type has a certain capability, for example to indicate that an object represents a schedulable event. By implementing the Schedulable Event interface, an object can be used by Ontology-aware apps for dynamic scheduling workflows, calendar management, and more.
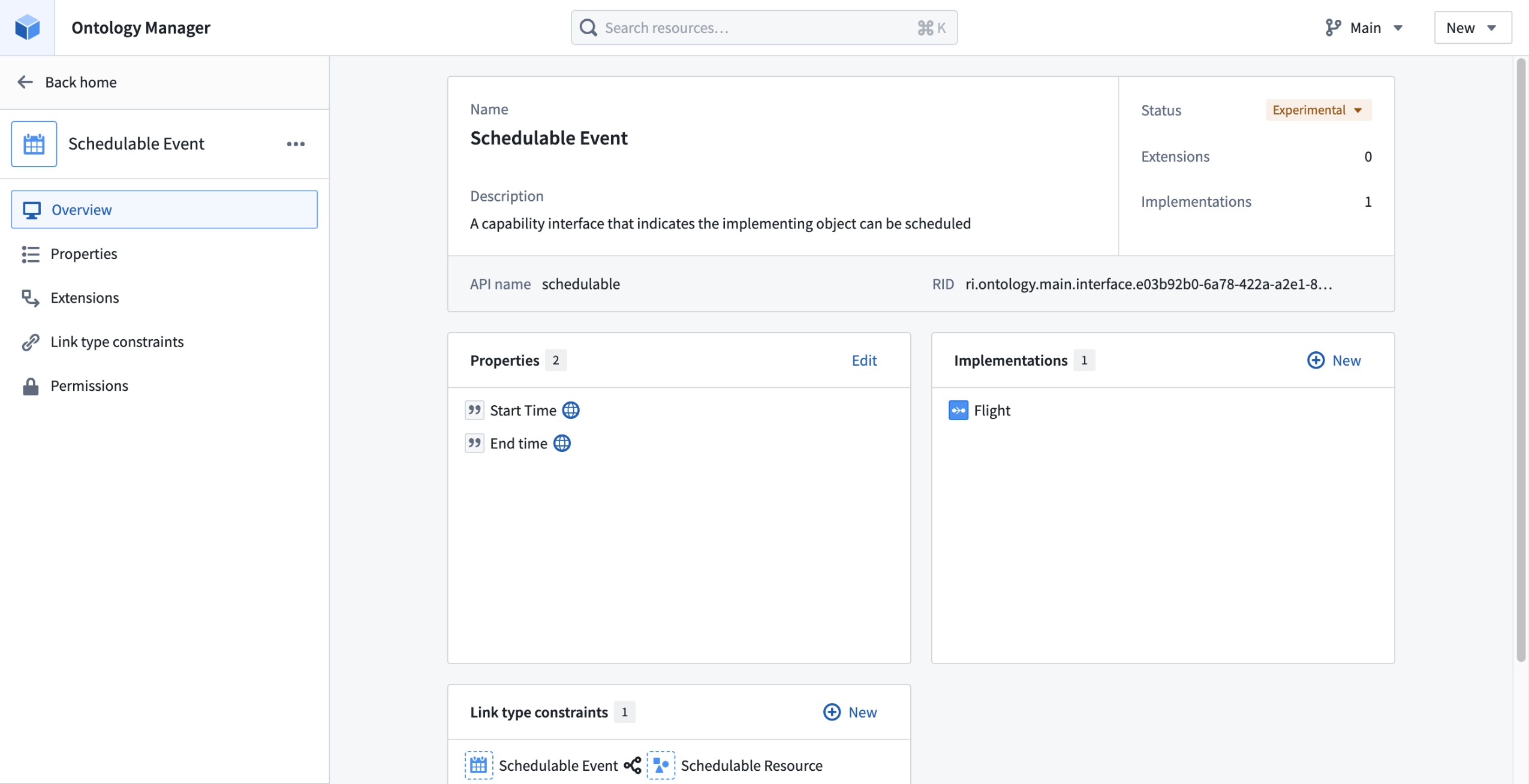
An example Schedulable Event interface, implemented on the Flight object type with shared Start Time and End Time properties.
Get started with interfaces
To add interfaces to your Ontology, you can create new interfaces or extend existing ones in Ontology Manager. Once you have an interface, you can then implement that interface with an object type of the appropriate shape or edit it to better fit your Organization as your Ontology evolves.
Once your interface is declared, you can package and install them with Marketplace, implement them in Pipeline Builder, and use them as your API in Ontology SDK applications.
To learn more about interfaces and how to use them, review our interface documentation.
What's next on the development roadmap?
As we work to make interface types generally available, we will extend support for interfaces as inputs to Actions, Functions, and Workshop widgets.
Introducing folders for node organization in Pipeline Builder
Date published: 2024-08-22
To improve your navigation and editing experience, you can now create folders and subfolders in Pipeline Builder. Creating folders is intuitive; you can group nodes by selecting them on the graph or highlighting them in the Pipeline file tree sidebar. A hierarchical file structure, also known as a file tree, will be created for your pipeline with additional visibility and node targeting options based on selected folders.
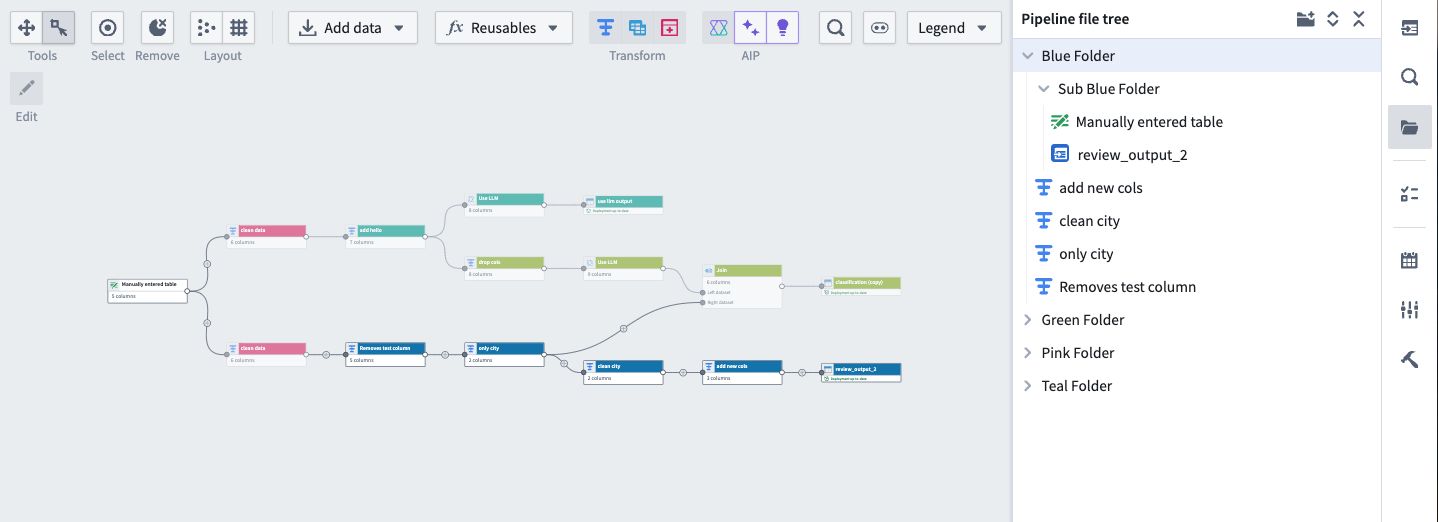
A pipeline with nodes organized into various folders and subfolders.
Narrow pipeline scope and display relevant nodes
You can toggle the visibility of nodes in a subset of folders to narrow the scope of your pipeline by choosing one of the visibility options shown below:
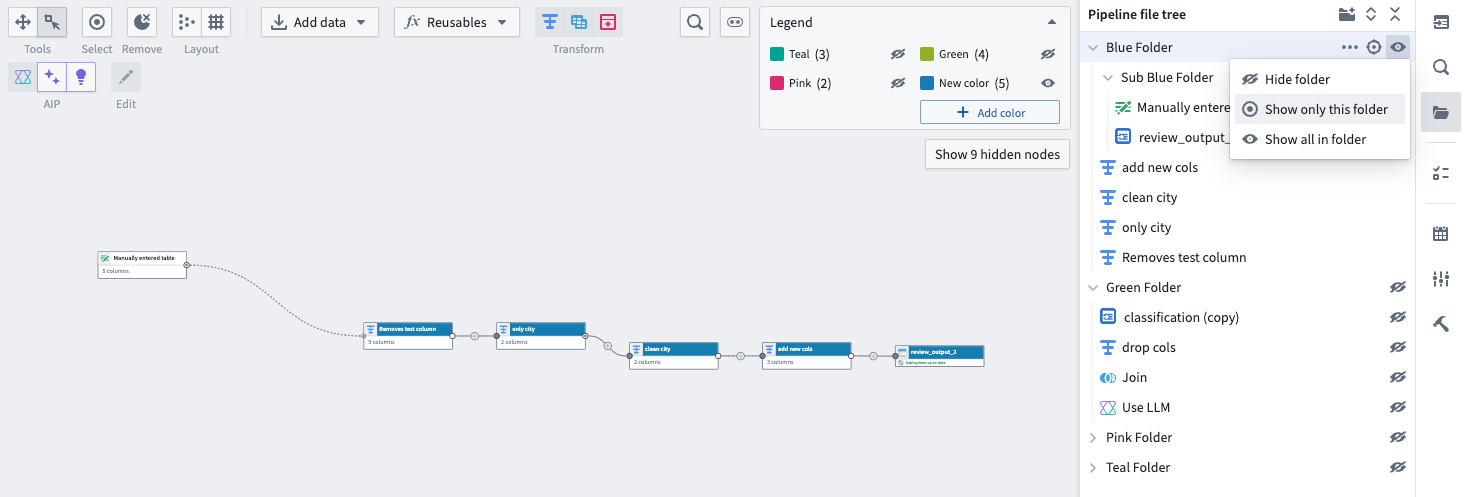
Only the nodes in the Blue Folder are displayed on the graph, with folder visibility options in the top right.
Additionally, you can quickly target relevant nodes on the graph by selecting the target icon to the right of the folder name. Leverage these new organization and visibility features to make the management of large and complex pipelines more efficient and streamlined.
Learn more about folders in Pipeline Builder.
Increase pipeline reliability with unit tests in Pipeline Builder
Date published: 2024-08-20
We are happy to announce that you can now implement unit tests for pipelines in Pipeline Builder. Unit tests serve as a valuable tool for debugging, detecting breaking changes, and ultimately ensuring higher quality pipelines. Create and run unit tests directly from Pipeline Builder to detect issues early and deploy your pipelines with added confidence.
What is a unit test?
Similar to unit tests in code, unit tests in Pipeline Builder allow you to confirm that pipeline logic produces the expected outputs when tested with predefined inputs. Unit tests consist of:
- Test inputs
- Transform nodes
- Expected outputs
Test inputs and expected outputs can be created with manually entered or existing datasets and schemas, allowing for fast and streamlined unit test creation. The transform nodes to be tested can be selected in the Pipeline Builder workspace.
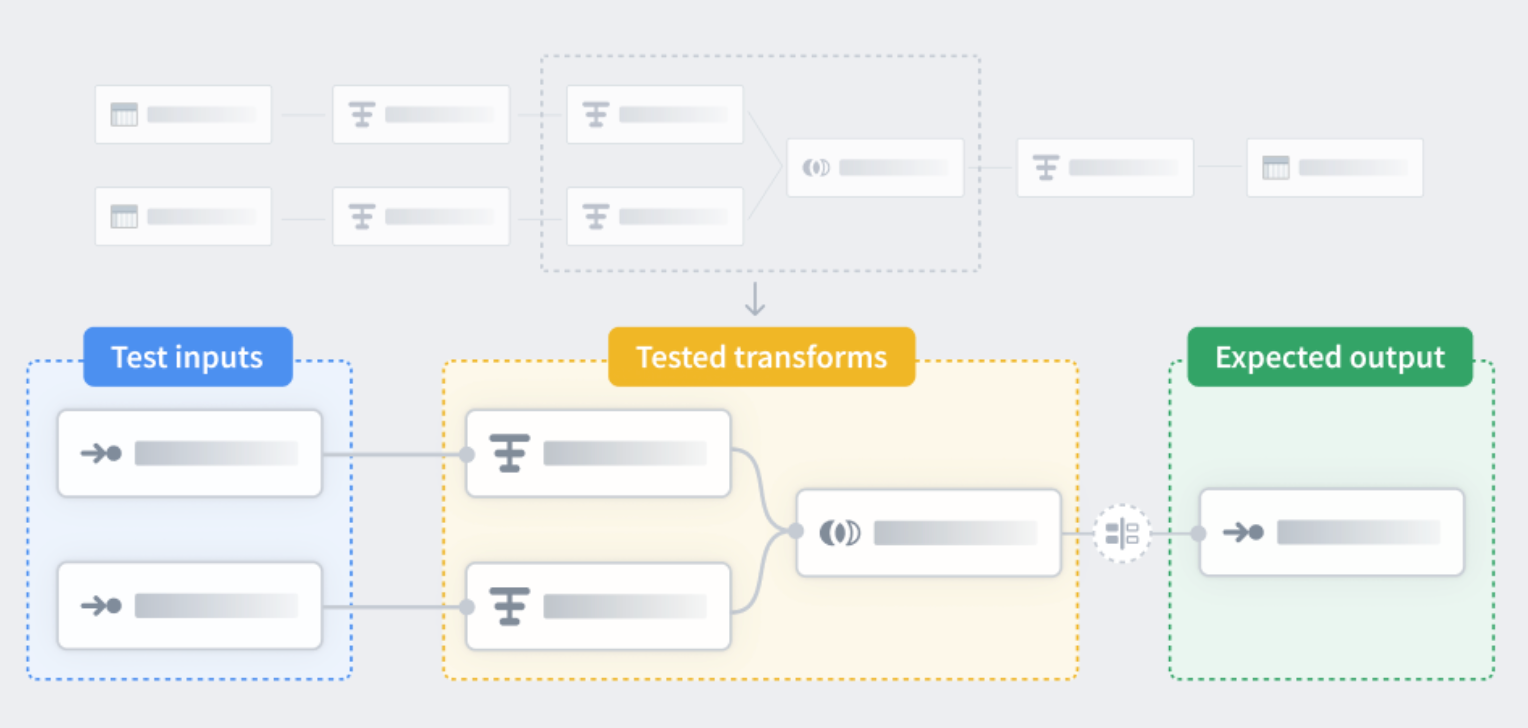
A diagram of the unit test workflow showing test inputs, tested transform nodes, and expected outputs.
Unit test capabilities
You can access unit tests by selecting the Unit tests icon on the right side panel. From there, you can create and fine tune unit tests by selecting the relevant nodes and providing input and output datasets.
The Unit tests icon on the right side panel.
After you have configured a unit test and created input and output datasets, select Run test to display expected and received outputs. From here, you can assess results and iterate on your pipeline or unit tests if necessary, all in one place.
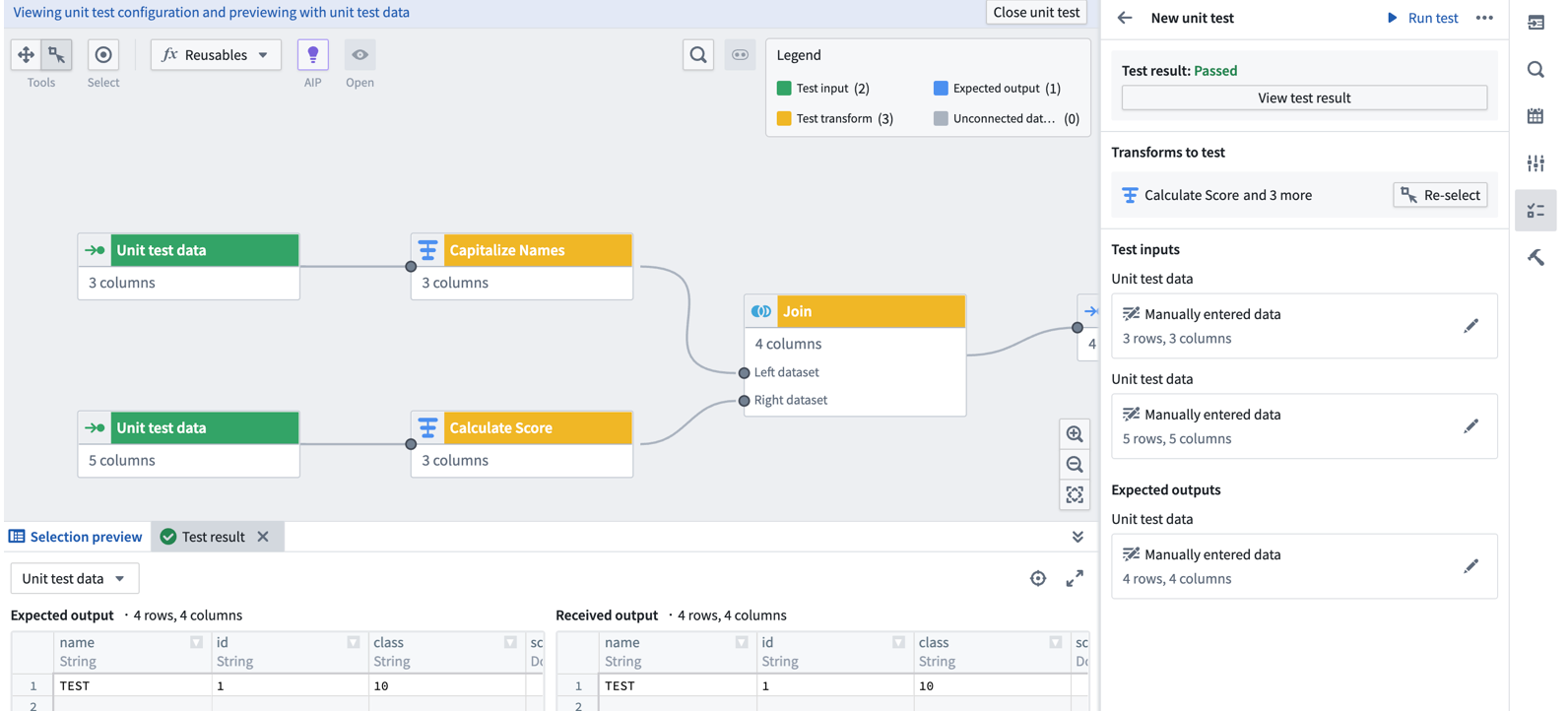
A sample unit test result, displaying test results and configuration on the right and expected and received outputs on the bottom.
As part of this flexible and fully-featured testing interface, you can easily edit and delete unit tests to keep up with rapidly evolving pipelines. Changes to unit tests will also show up in the proposals page, allowing you to track changes and ensure that all tests are passing before merging proposals.
Learn more about unit testing in Pipeline Builder.
Improved Pipeline Builder and Ontology integration
Date published: 2024-08-13
Pipeline Builder just got more powerful; it is now possible to create and edit Ontology object and link types, resolve conflicts, and migrate schemas directly from your pipelines. Thanks to an improved Pipeline Builder and Ontology integration, users can now benefit from streamlined workflows and added versatility when building on the Palantir platform.
Previously, it was not possible to edit Pipeline Builder-owned objects and links in Ontology Manager. Now, you can make changes to Pipeline Builder-owned objects in both Pipeline Builder and Ontology Manager, with the necessary conflict resolution and schema migration features to ensure consistency. Note that while objects created in Pipeline Builder can be edited in Ontology Manager, objects created in Ontology Manager cannot yet be edited in Pipeline Builder.
Enable edits through Actions
To get started, enable edits in Pipeline Builder or Ontology Manager. Toggle Allow edits to objects of this type to allow edits in both Pipeline Builder and Ontology Manager. This will also enable Action-based Ontology edits in Workshop and other applications. Note that only batch-backed objects created in Pipeline Builder currently support this feature, and stream-backed object types do not currently support edits.
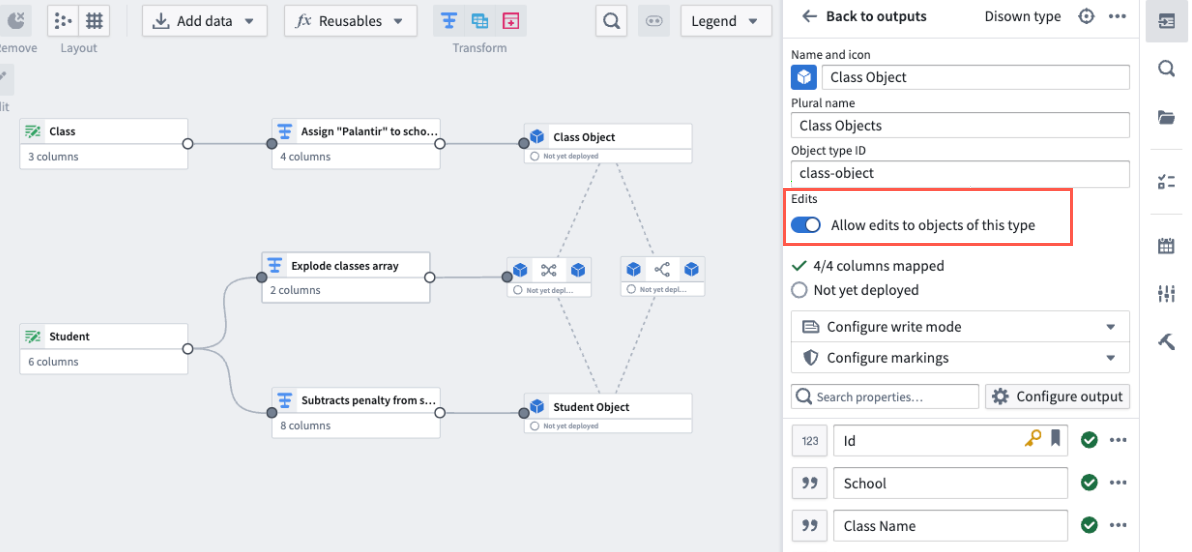
The Allow edits toggle in the edit object type panel.
Bidirectional change syncing between applications
To support Ontology changes from both Pipeline Builder and Ontology Manager, we have introduced the following features to ensure that conflicts, validation errors, and schema changes are handled seamlessly.
Merge conflict resolutions: We have added a merge conflict resolution dialog box for smoother editing across Ontology Manager and Pipeline Builder, preventing concurrent updates from being overwritten.
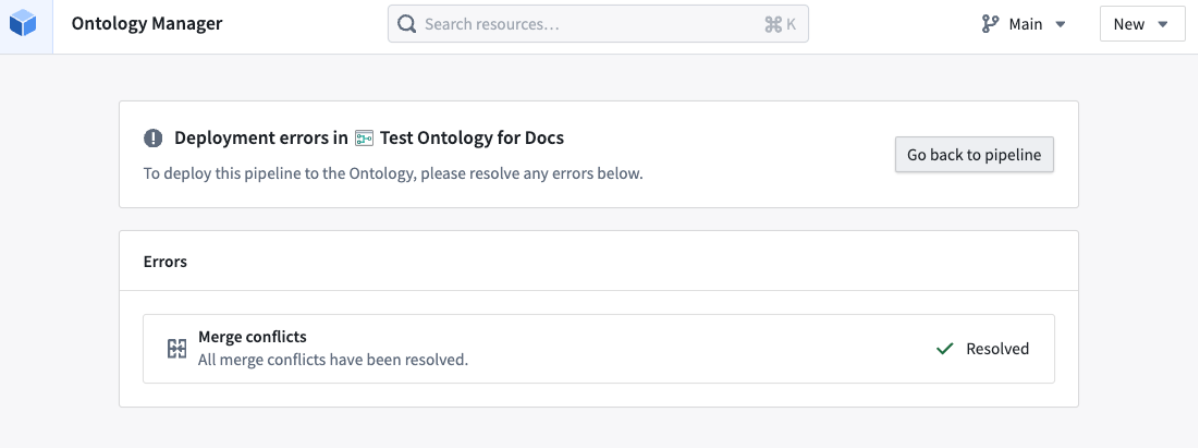
The merge conflict resolution page in Ontology Manager.
Validation error resolution: You will be informed of validation errors and provided with resolution options before deploying pipelines that make changes to the Ontology. This way, you can avoid errors and failures during pipeline deployment when attempting to push invalid changes to the Ontology.
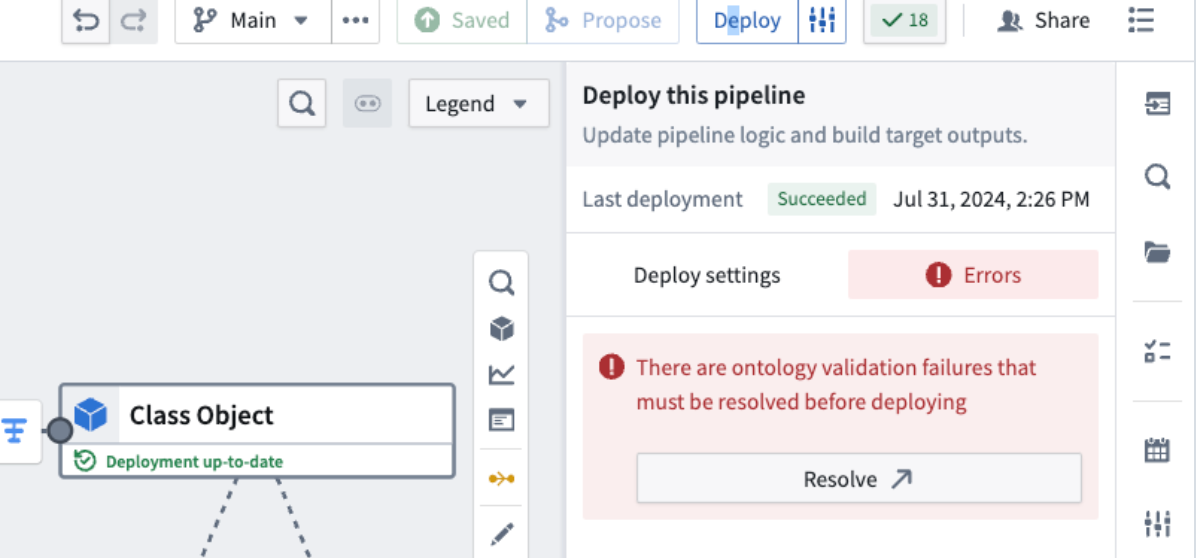
An example of validation failures that must be resolved before deployment.
Schema migration support: We have added a schema migrations dialog to let you choose between different schema migration options when required, such as dropping edits on a property or casting edits to a different data type.
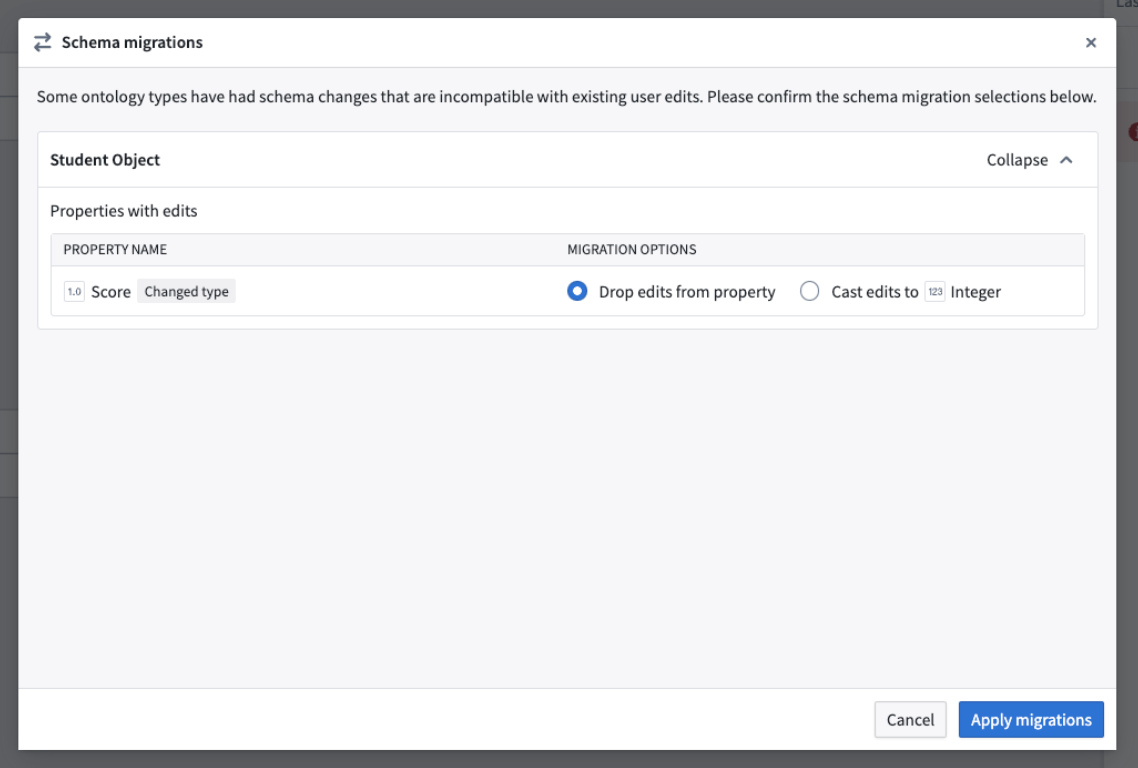
The Schema migrations dialog providing different options to enable schema migrations when needed.
Share pipelines with full Marketplace compatibility
Pipelines with Ontology outputs can now be packaged and installed via Marketplace. Share or download pipelines that include Ontology object and link types to more easily set up and deploy workflows.
Learn more about Ontology outputs in Pipeline Builder.
Platform settings Organization permissions UI will be deprecated, with members being migrated to Control Panel roles
Date published: 2024-08-08
Phase 2 of migrating Organization permissions from Platform Settings to Control Panel Organization roles is taking place the week commencing September 9. This phase streamlines the administrative workflows within the Palantir platform by consolidating two separate categories of Organization permissions to a single source of truth, represented by Organization roles.
Phase 2: Automatic migration and removal of the Platform Settings user interface
Remaining members with Platform Settings permissions will be transitioned to the corresponding roles in Control Panel, which were enriched with the necessary workflows and permissions in the first phase of the migration. With the completion of Phase 2, the permissions granted by the legacy Organization settings will be available exclusively through Organization roles in Control Panel. Environments that do not have Control Panel installed will have the current Platform Settings permissions sidebar replaced by a lightweight organization permissions component.
You can expect the following changes:
-
Automatic migration: All existing permissions members will be automatically migrated to ensure continuity and no loss of access or privileges. Two new custom Control Panel Organization roles will be created as needed for any individual members of legacy permissions to avoid expanding access. The diagram below shows which members of legacy permissions will be added to corresponding Organization roles.
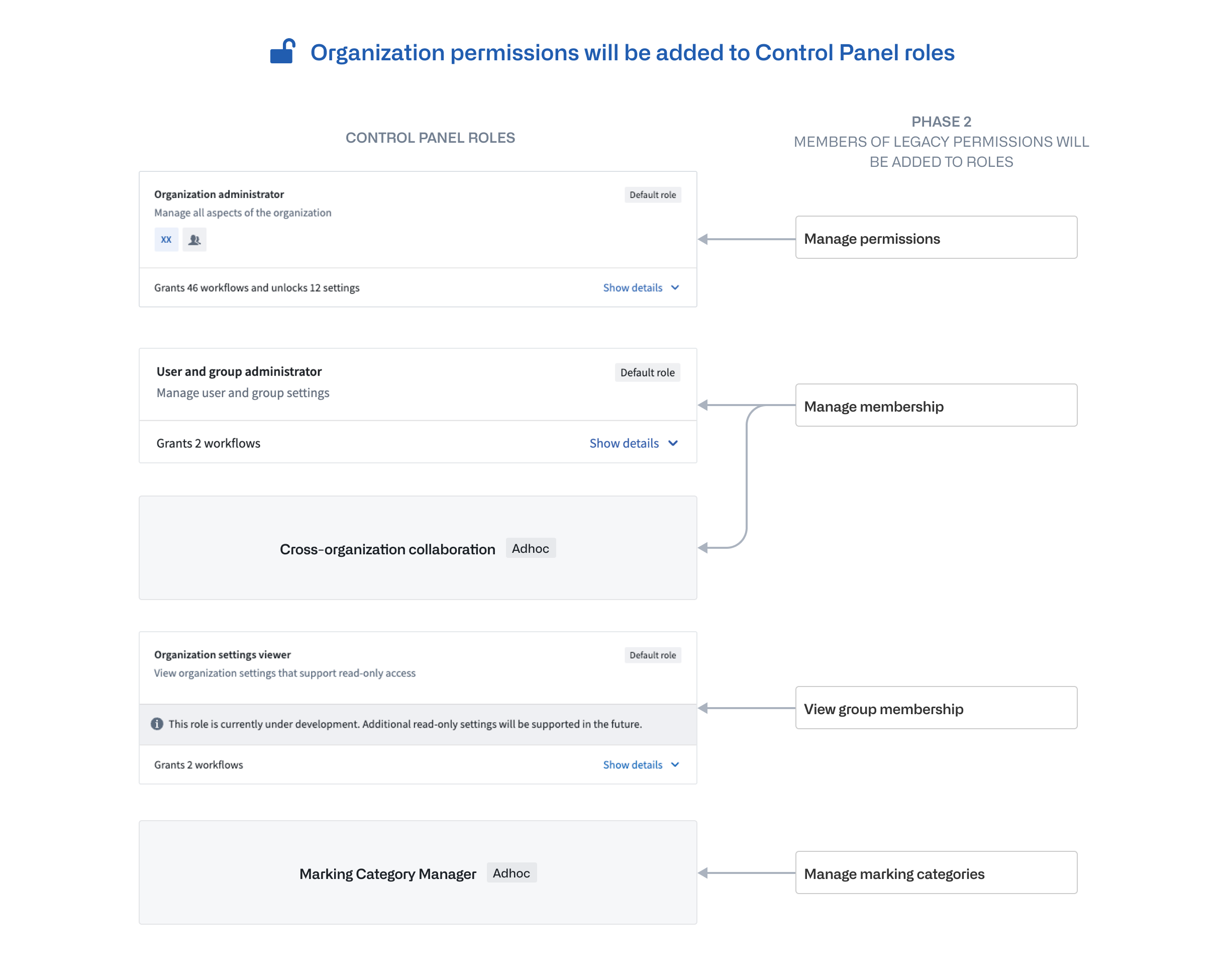
Diagram showing which members of legacy permissions will be added to corresponding Organization roles.
-
Removal of the Platform Settings user interface: The user interface for permissions management in Platform Settings will be deprecated, consolidating permission management solely within Control Panel, where available.
Administrators should audit permissions and review documentation
The consolidation of permissions into a single interface is part of our ongoing efforts to simplify administrative tasks and improve the user experience. By enhancing role customization and granularity in permissions, administrators can more efficiently manage their Organization's settings and security.
As Phase 2 starts, we ask all administrators to:
- Audit permissions: Perform a final audit to ensure that all permissions are correctly assigned in line with your Organization's requirements.
- Review documentation: Take the time to review the updated documentation on permissions management in the Palantir platform to familiarize yourself with the new workflows.
For more information on how permissions and its primitives work in the Palantir platform, review the documentation on Enrollments and Organizations.
Use struct variables in Workshop to decrease network calls and speed up your workflows
Date published: 2024-08-06
Workshop now supports a new struct variable type, which are composite variables containing fields of other variable types, backed by functions. This new feature gives application builders the ability to return custom types from functions or structs from Logic functions, decreasing both the amount of functions that need to be called and total network calls. Use the struct variable type to reduce complexity, bolster generative AI responses, and boost your Workshop module performance.
Create struct variables within Workshop to support your workflows
You can create a struct variable using either a function written in code repositories, or a Logic function. If a field's type is not supported in Workshop, it will be ignored and omitted from the initialized variable's fields. Note that the following are not currently supported: struct nesting (for example, inside a person struct, you cannot have another struct bestFriend), and struct arrays.
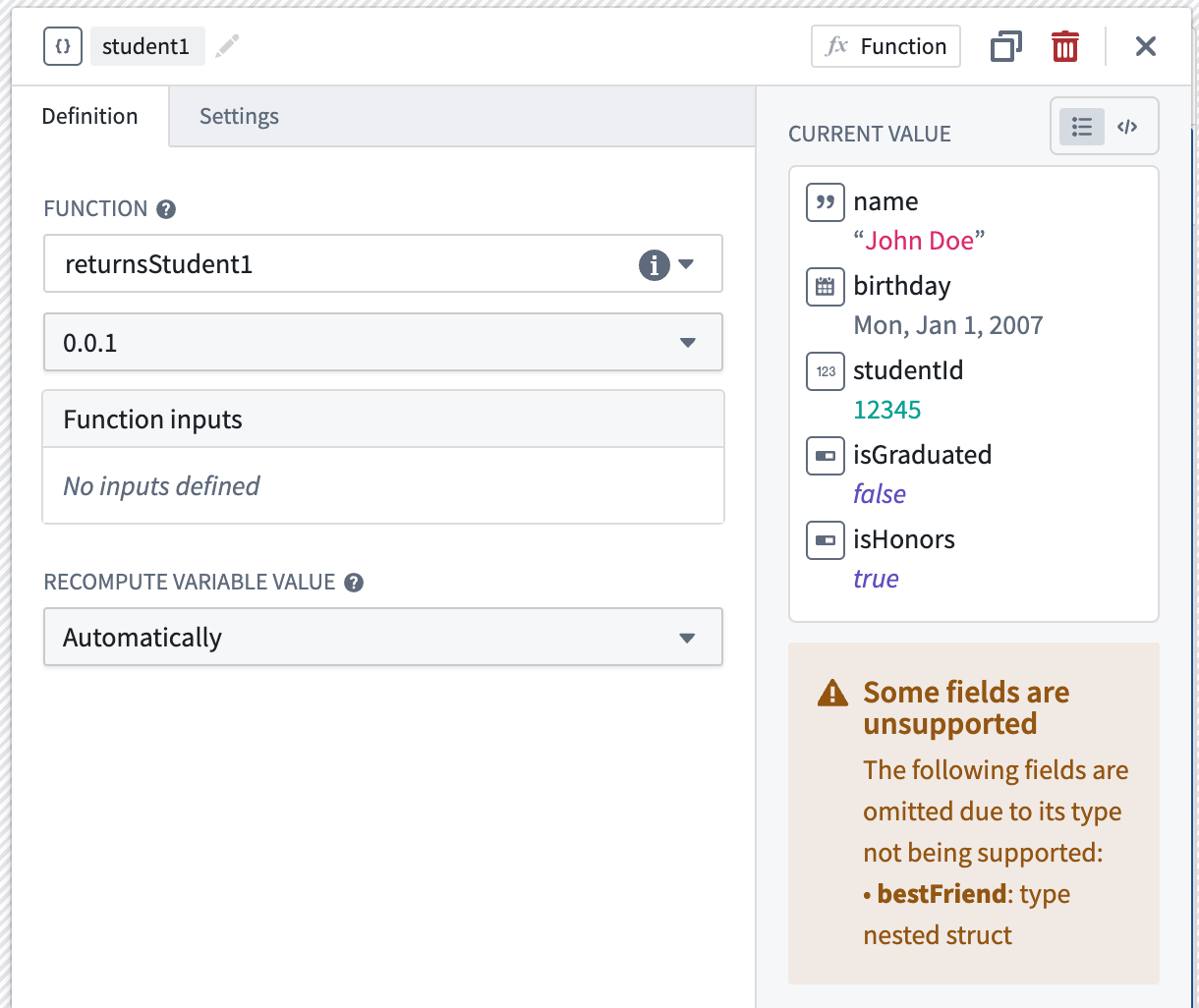
Struct variable student1 is backed by a function that returns fields name, birthday, studentId, isGraduated, isHonors of field types string, date, number, boolean, boolean, respectively. Unsupported field bestFriend which is a type of nested struct is not yet supported and is omitted.
Extract fields from struct variables to display in widgets
As widgets and variable transformation operations cannot use structs as a whole, extract individual struct fields for use. The image below shows how the string type name field is extracted from the person struct variable using an extract struct field variable transform, and then used in a Metric card widget.
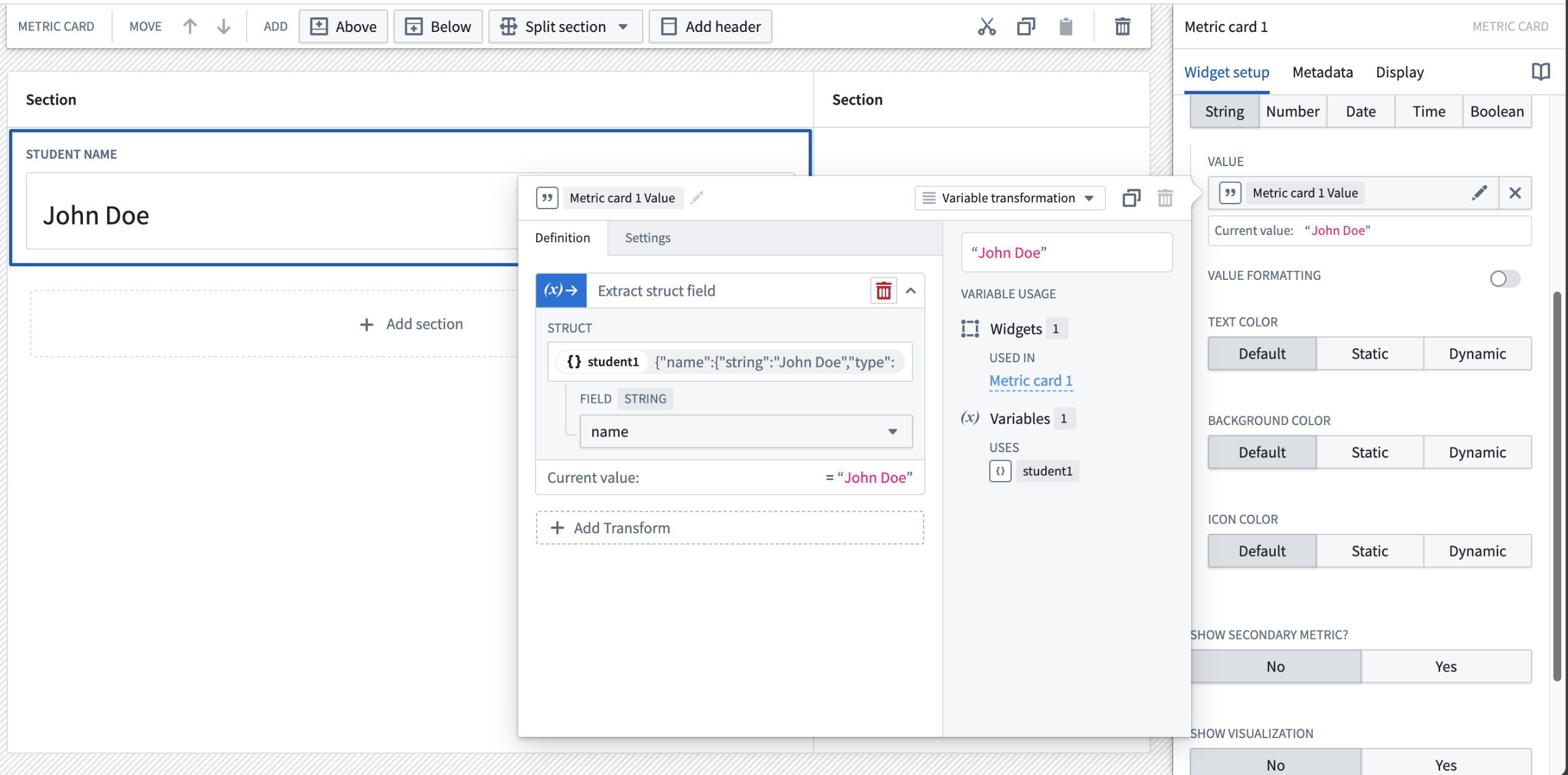
Field name on struct variable student1 is extracted into a string variable and displayed on a Metric card widget.
Pass struct variables as inputs to functions
Finally, understand that struct variables can also be used as inputs to functions. When configuring a function that uses a struct as an input, the required fields of the struct input may be previewed by hovering over the Preview schema label. In doing so, application builders can easily verify that the expected input schema matches that of the selected struct variable by referencing it to the struct variable's raw Current value.
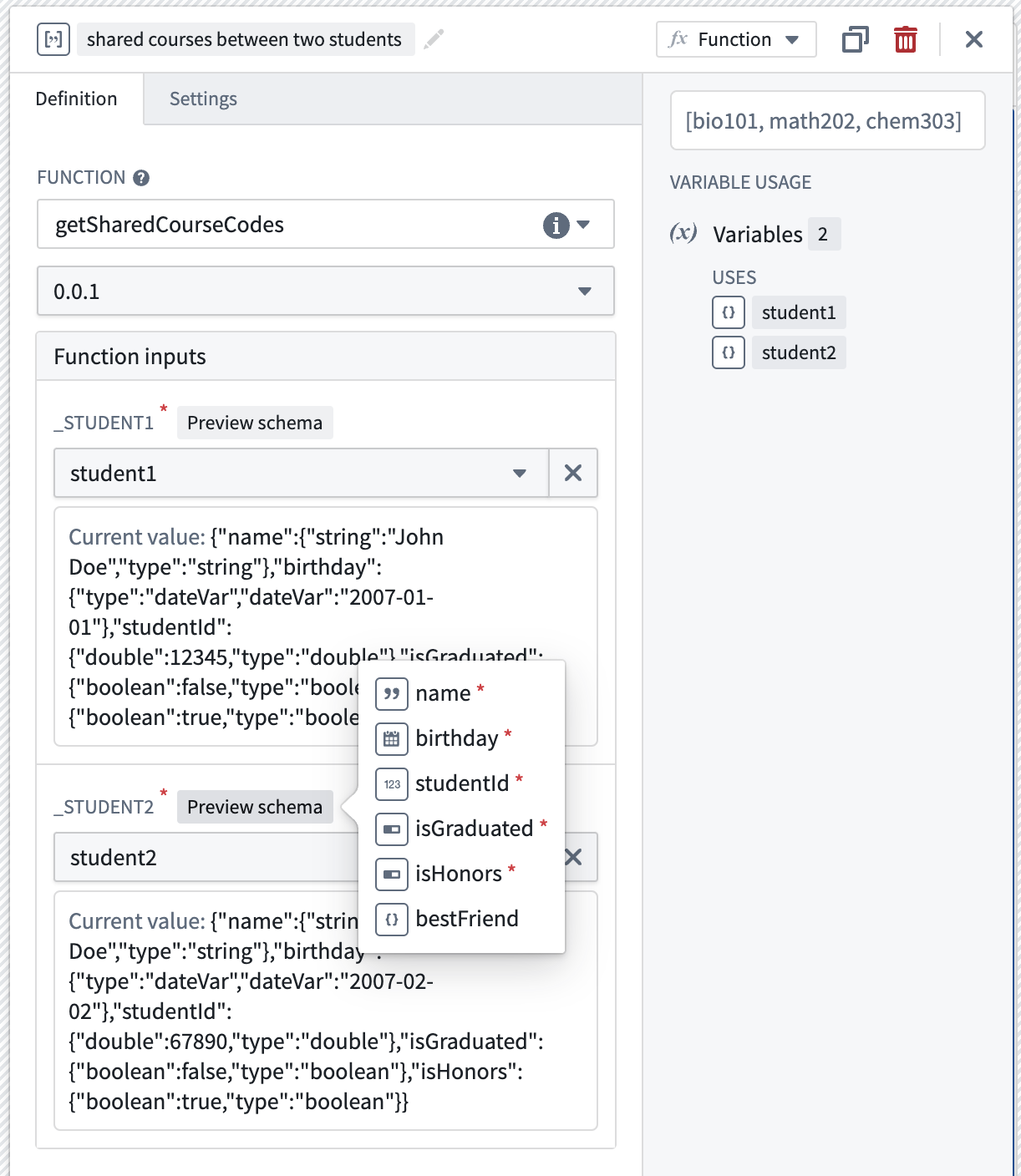
A function that returns a list of common course codes shared by the two students takes in two student structs as inputs.
Review the documentation on struct variables in Workshop.
Value types are now generally available in the Ontology and Marketplace
Date published: 2024-08-01
Value types are now generally available, providing semantic wrappers around field types that include metadata and constraints to enhance type safety, expressiveness, and context. These value types can be reused across multiple object types and pipelines in the platform, with no need to duplicate validation logic. You can easily create and manage value types through the new Value Types application, then apply them to properties in your Ontology using the Ontology Manager. With their move to general availability, you can also package and install value types in Marketplace for use in your Marketplace products.
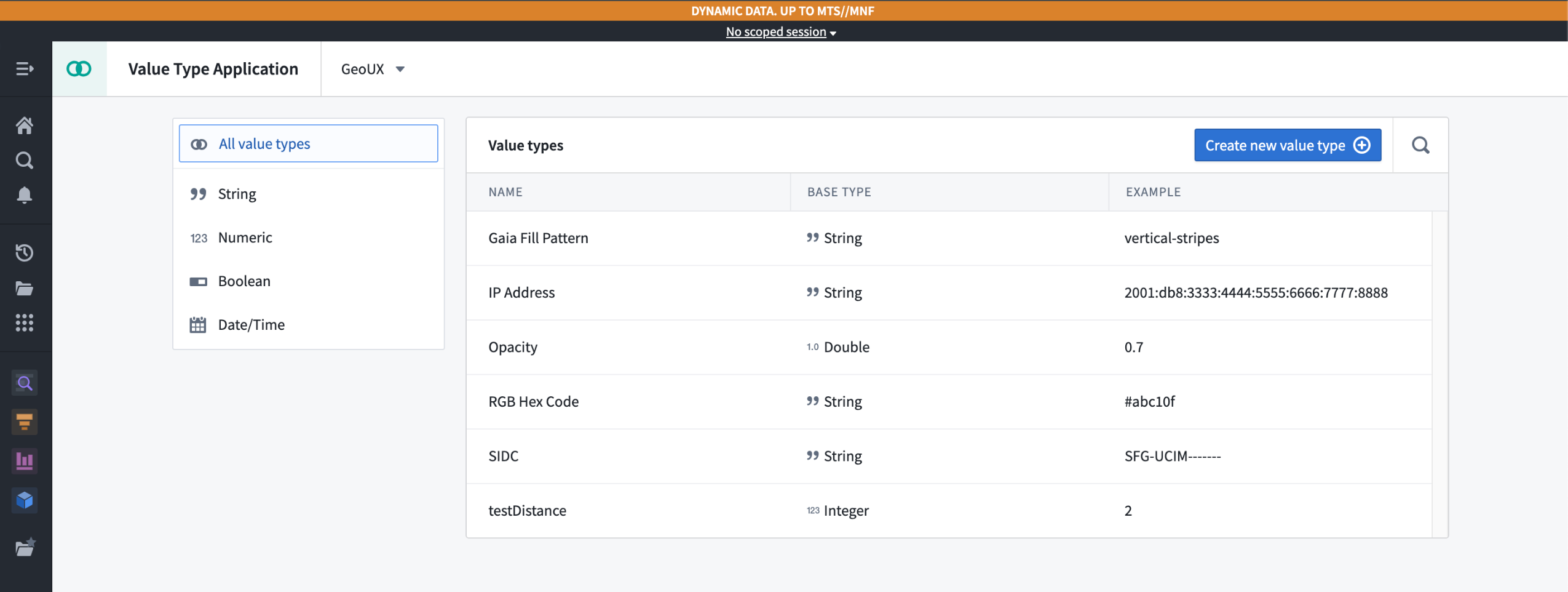 The Value Types application, displaying available value types in a given namespace.
The Value Types application, displaying available value types in a given namespace.
Add user-defined semantic types
With value types, you can capture the context and semantic meaning of data while centralizing data validation. You can intuitively define and consume meaning directly from the value type without relying on information like column names or property descriptions. Value types also enforce validation constraints on data in Pipeline Builder pipelines and the Ontology, allowing data integrators and ontology managers to ensure proper semantic typing in their data flows and models.
For example, you can define an email value type that has a regular expression constraint to ensure that any property using the value type represents a valid email address. This value type can then be reused across multiple object types and pipelines, without needing to duplicate the validation logic for every given property. Additionally, each property that uses this value type is explicitly understood to contain an email address.
Use value types in the platform
Once you create a value type, you can use it to provide data validation across Foundry. You can use value types in a variety of use cases:
- Assigning a value type to an object type property
- Assigning a value type to a shared property
- Assigning a value type to a Pipeline Builder pipeline property as a logical type, using the
logical type castexpression and selecting the value type on the property when you write to the objects target.
To assign a value type to a property, select the value type from the dropdown menu during property configuration.
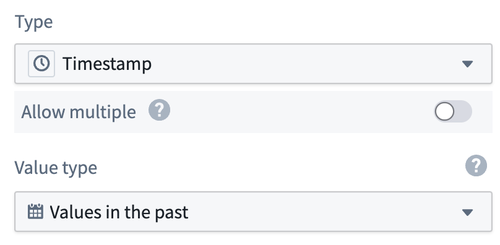
The value type selector in Ontology Manager, allowing a user to assign a value type to a property.
Value types packaged in a Marketplace product.
Additional highlights
Administration | Workspace
View platform updates from the workspace sidebar | Users can now navigate to the latest public announcements and release notes from Foundry using the Platform updates link available in the Support menu of the workspace sidebar.
Data Integration | Builds
Introducing live logs | The live logs feature enables you to monitor logs from any job run in real time, directly within the Palantir platform. You can access live logs within the Builds application and in most areas where logs are typically available for viewing. To use live logs, select the View live option located in the top right corner of the log viewer.
Data Integration | Data Lineage
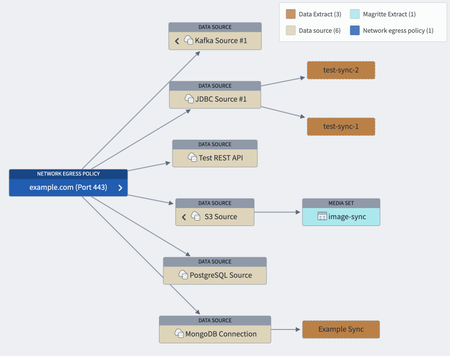
Egress policy integration in Data Lineage | Sources with egress policies are now visually integrated into the Data Lineage downstream flow, offering improved insights into data movement.
Data Integration | Pipeline Builder
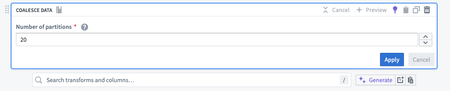
Coalesce partitions with a new transform | We are excited to introduce partition coalescing with a new Pipeline Builder transform to reduce the number of partitions in your input. By reducing partitions, you can significantly speed up data processing tasks, leading to faster job completion times. Additionally, fewer partitions mean less overhead and more efficient use of system resources.
To use this transform, select Coalesce Data and enter the number of partitions to coalesce to. If you have a large number of partitions and coalesce to a smaller number, a shuffle will not occur; instead, each of the new partitions will claim a set of the current partitions. If a larger number of partitions is requested, the current number of partitions will remain.
Ontology | Ontology Management
Enhanced date and time formatting in Ontology Manager | Ontology Manager has now introduced expanded capabilities for customizing date and time formats. Users can tailor date and timestamp properties through a new selector. You can also now have a uniform format for all users regardless of local date formats.