- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: You can now sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Introducing value types [Beta]
Date published: 2024-02-28
This feature is now generally available. Read the latest announcement.
Foundry Connector 2.0 for SAP Applications v2.30.0 (SP30) is now available
Date published: 2024-02-27
Version 2.30.0 (SP30) of the Foundry Connector 2.0 for SAP Applications add-on, used to connect Foundry to SAP systems, is now available.
This latest release features bug fixes and minor enhancements, including:
- An extended Post Installation Wizard that covers remote agents (NetWeaver 7.0 and above) and simplifies the setup process for remote agents.
- An extended API that indicates if a table is an enrichment table, which will be used by Palantir HyperAuto (all versions).
- A fix for an authorization problem for custom roles when the agent name and the RFC name to the agent system are different.
- A logic change implementation in the CDPOS incremental type to address an issue that caused potential data loss during incremental syncs using the CDPOS type exclusively.
Download directly from Foundry's in-platform custom documentation
Starting with SP29, the add-on installation packages can be downloaded directly from within the Palantir platform. To access SP29:
- Open the in-platform custom documentation from the bottom of the Foundry navigation bar.
- Search for
SAPin the documentation and select the Foundry SAP Connector. - From the How To section of the documentation, select Download the Add-On.
We recommend sharing this notice with your organization's SAP Basis team.
For more on downloading the add-on, consult Download the Palantir Foundry Connector 2.0 for SAP Applications add-on in documentation.
Introducing JupyterLab® and RStudio® support in Code Workspaces GA, coming March 2024
Date published: 2024-02-22
JupyterLab® and RStudio® support in Code Workspaces is now GA. See the April announcement for more information.
Introducing support for Palantir-provided language models in Code Workspaces
Date published: 2024-02-22
The Palantir-provided set of language and embedding models are now available for use in Jupyter® notebooks via Code Workspaces, similar to transforms. With this new capability, users can interactively run inference against Palantir-provided models to generate text completions and embeddings, and can quickly prototype with language models before deploying a full production pipeline.
Use language models in Code Workspaces
Using the Models view, Notebook authors can easily import Palantir-provided models into their code workspace and access the bindings for those models using the palantir_models Python SDK.
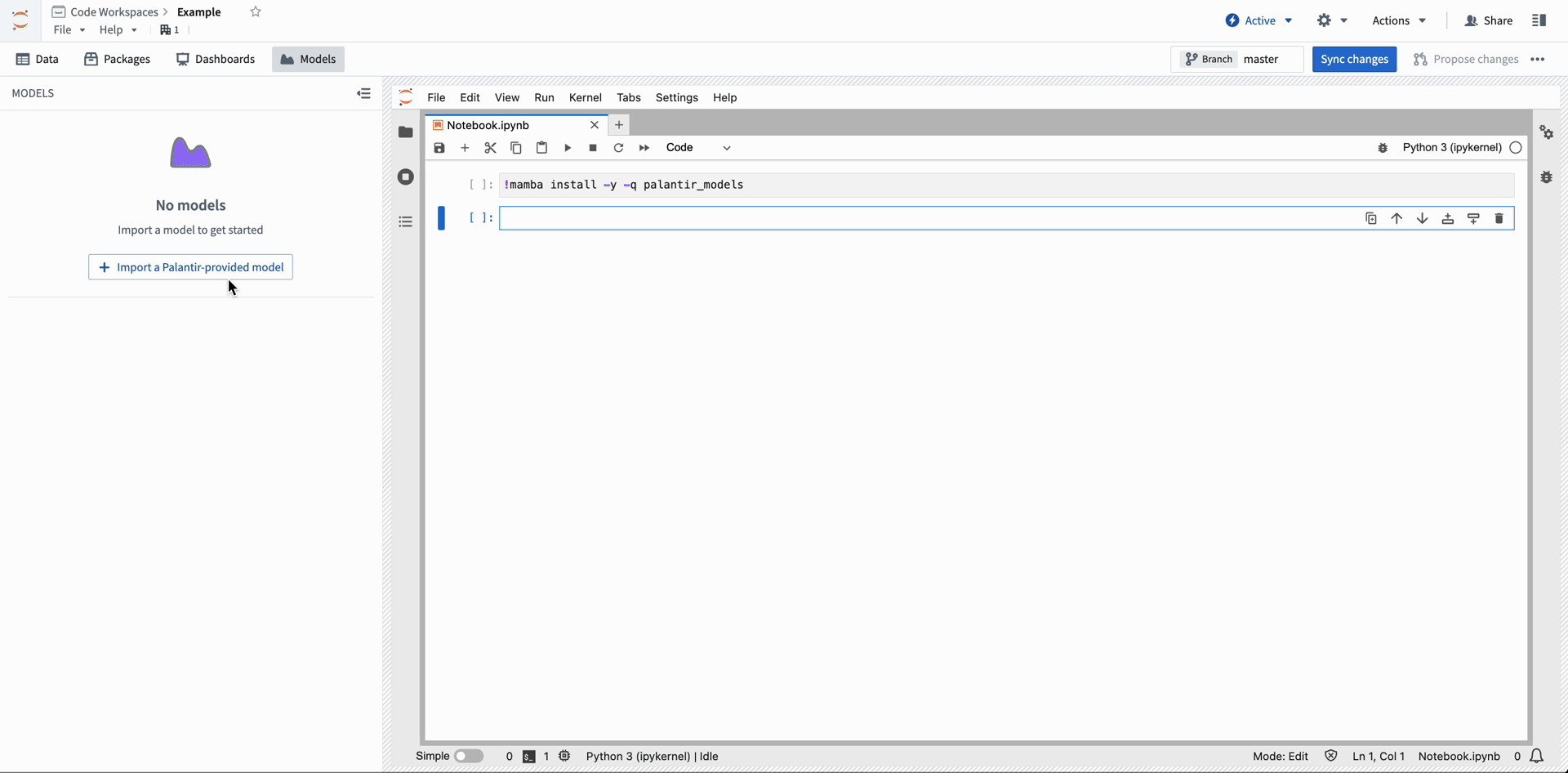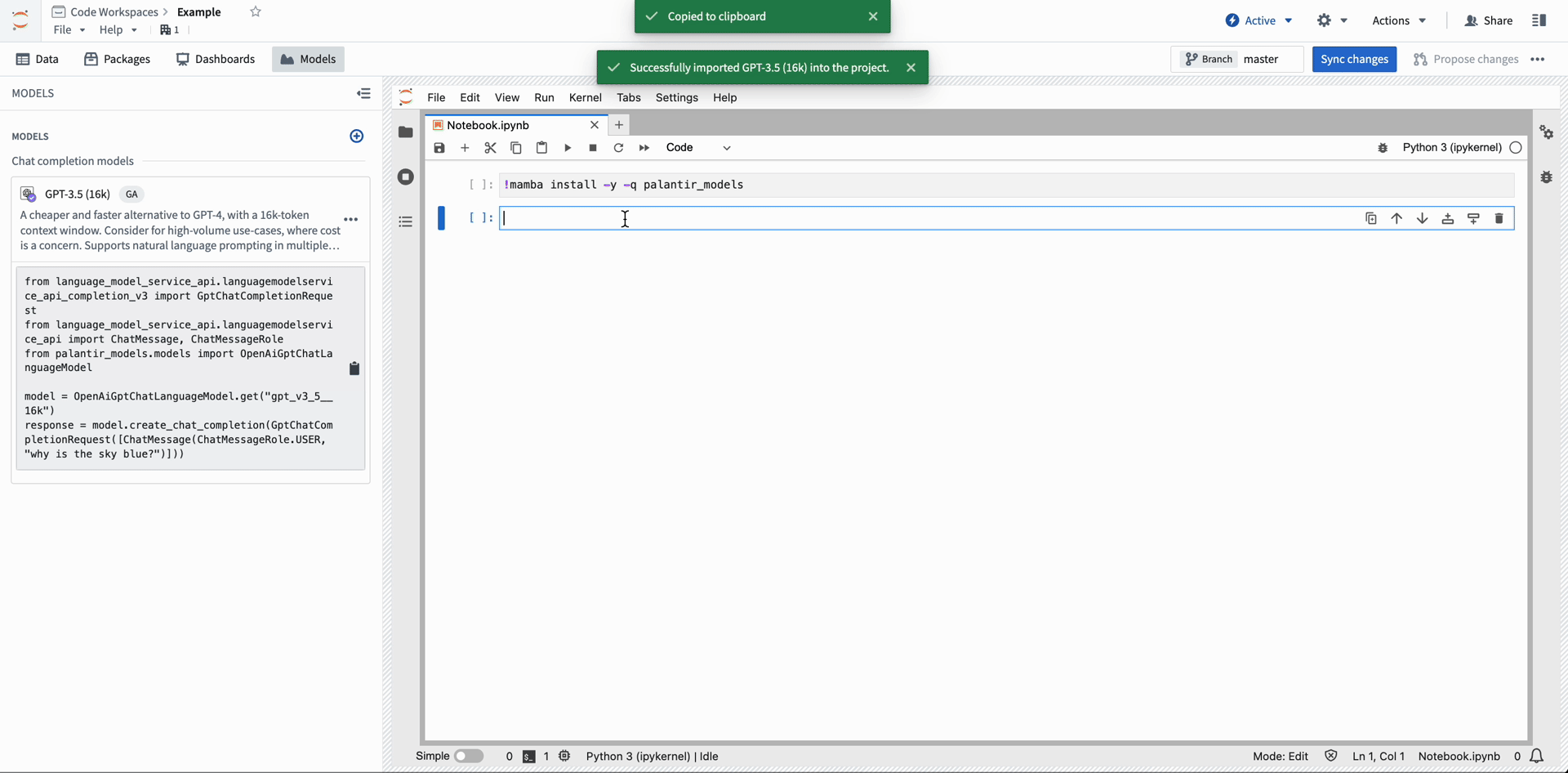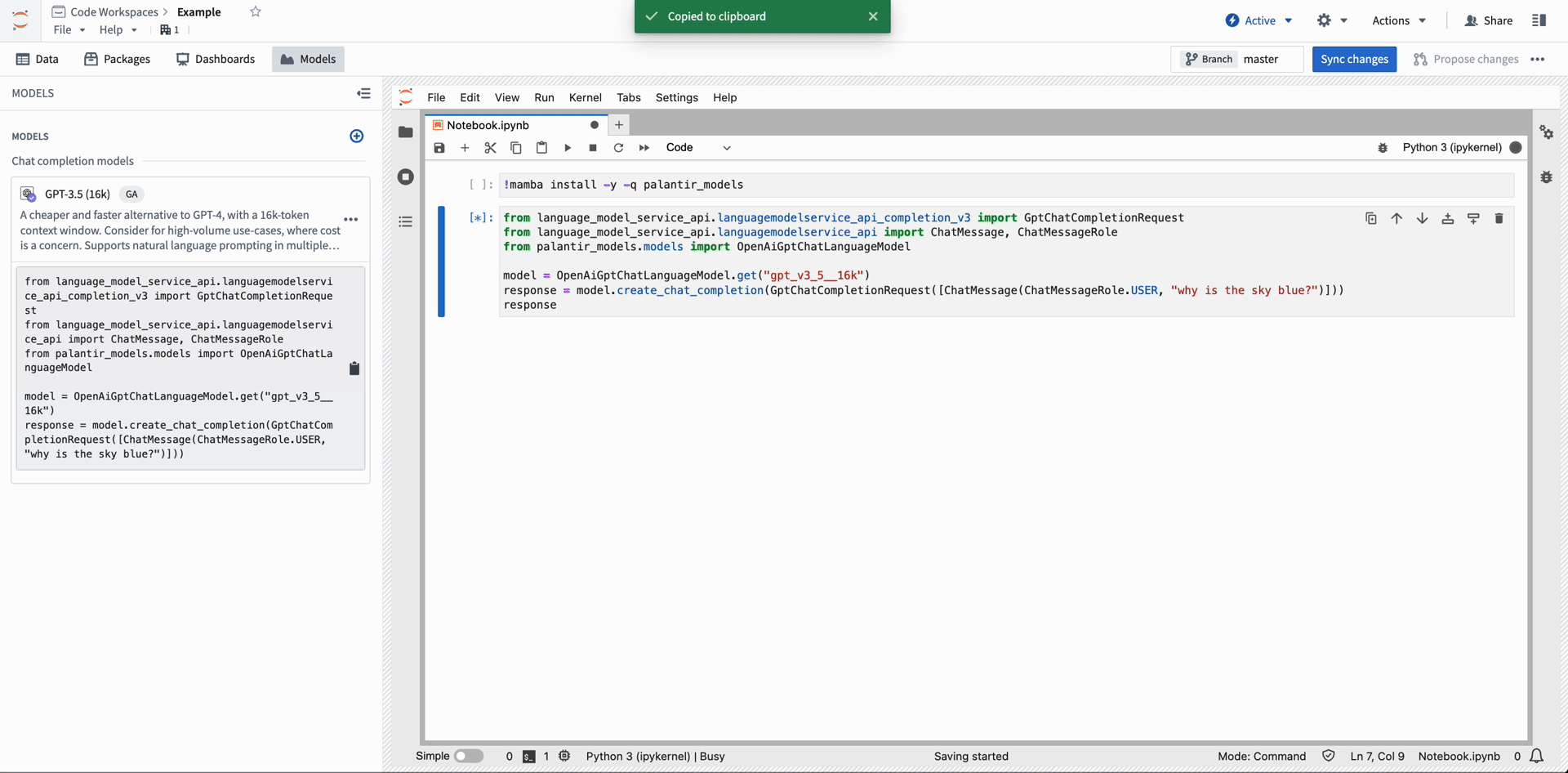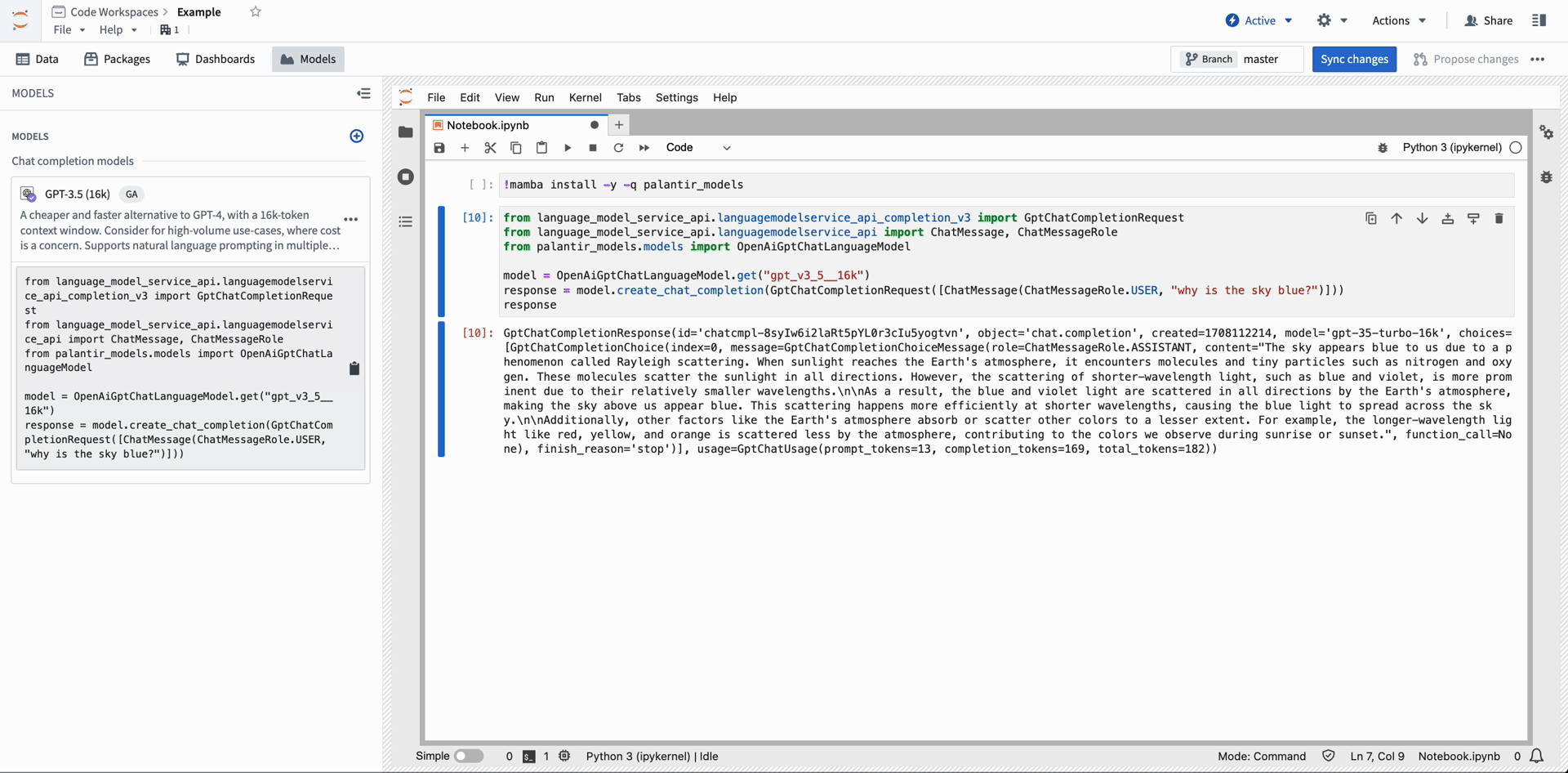
Import Palantir-provided models into Code Workspace from the Models menu.
Example notebook cell
The code snippet below demonstrates how a developer can use Open AI's GPT-4 ↗ in their notebook. After importing a model into Code Workspace, copy and paste the provided snippet into a cell to run inference.
Copied!1 2 3 4 5 6 7from language_model_service_api.languagemodelservice_api_completion_v3 import GptChatCompletionRequest from language_model_service_api.languagemodelservice_api import ChatMessage, ChatMessageRole from palantir_models.models import OpenAiGptChatLanguageModel model = OpenAiGptChatLanguageModel.get("gpt_v4") response = model.create_chat_completion(GptChatCompletionRequest([ChatMessage(ChatMessageRole.USER, "why is the sky blue?")])) response.choices[0].message.content
For more information on using Palantir-provided models, consult the documentation on Palantir-provided models within Jupyter® notebooks.
Jupyter®, JupyterLab®, and the Jupyter® logos are trademarks or registered trademarks of NumFOCUS. All third-party trademarks (including logos and icons) referenced remain the property of their respective owners. No affiliation or endorsement is implied.
The foundry_ml Python library will be deprecated in favor of the palantir_models library on October 31, 2025
Date published: 2024-02-22
As of today, the foundry_ml Python library is in the planned deprecation phase of development. The foundry_ml library will be deprecated October 31, 2025, corresponding with the planned deprecation of Python 3.9. In its place, we recommend using the palantir_models framework to develop, test, and serve models in the platform.
What is the palantir_models framework?
The palantir_models framework offers significantly more flexibility to customize models for Foundry workflows, including:
- Custom serialization, API, and inference logic to easily support a wider range of models and inference modes
- Multi-input and multi-output models
- Automatic bundling of Python dependencies for immediate deployment
- First-class wrapping of externally-hosted models for model evaluation and inference in Foundry
- Container-backed models to enable very large or very custom modeling frameworks
- Direct access to media sets for model inference
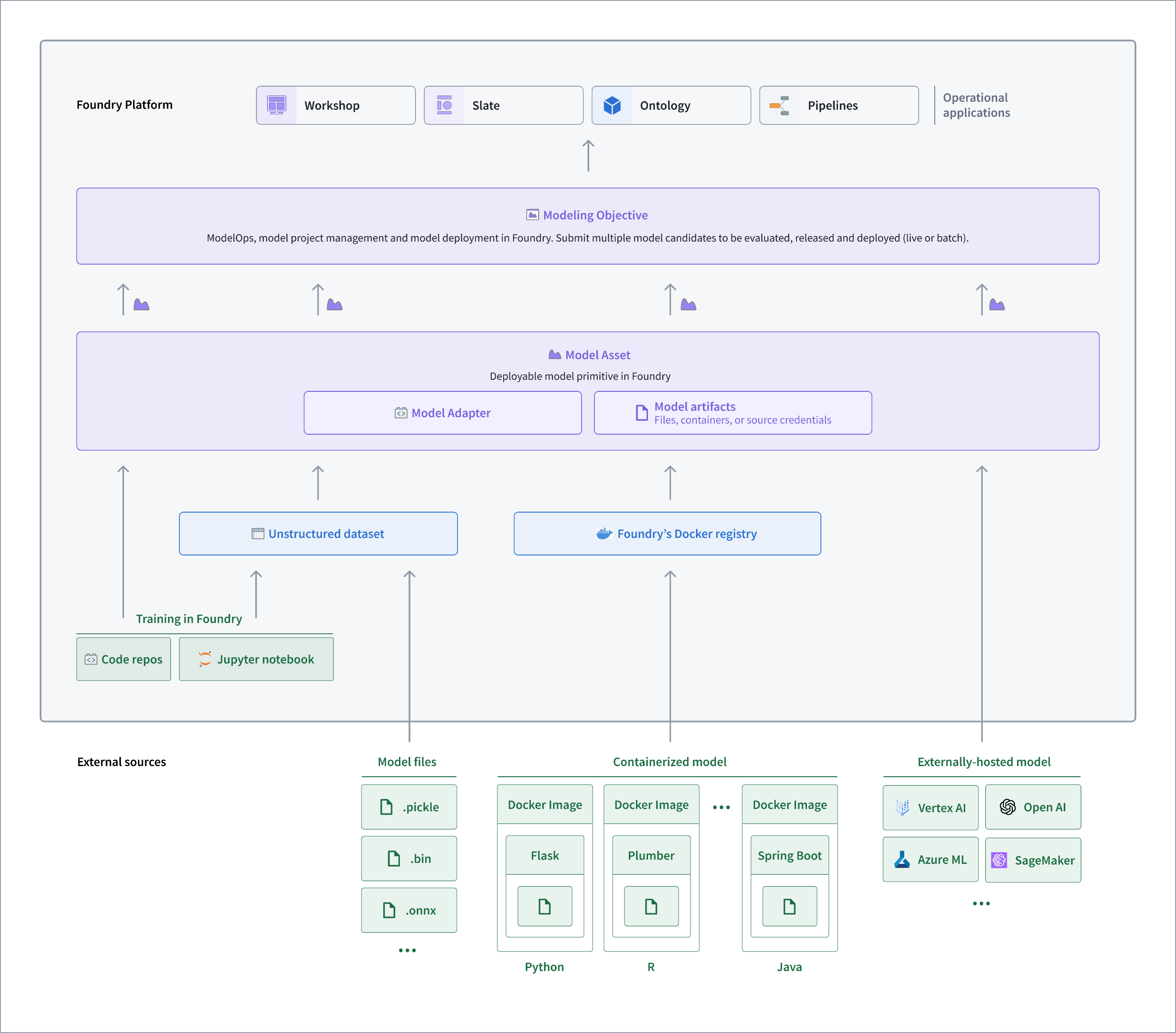
Architecture diagram of how palantir_models is used in Foundry.
Many models originally developed with foundry_ml can be migrated to palantir_models with minimal additional code by using the Model Training template in Code Repositories and one of the example model adapters found in the documentation as below:
- Train a binary classification model with scikit-learn in Code Repositories
- Example: Implement a container model adapter
- Example: Integrate an Amazon SageMaker model
Note that other models may require manual migration to the palantir_models framework. To learn more, review the following content:
How do I migrate to palantir_models?
Models trained with foundry_ml need to be updated to use the palantir_models framework by October 31, 2025. Equally, models developed with foundry_ml will not be supported in modeling objectives, Python transforms, or modeling objective deployments. For guidance on migration by building a new model with palantir_models, review How to train a model in Code Repositories.
As a reminder, Palantir will initiate an Upgrade Assistant intervention campaign to notify impacted teams using affected models in October 2024. If you have a concern regarding migrating your workflow to the palantir_models framework, contact Palantir Support.
Introducing Automate AIP Logic integration and manual execution features [GA]
Date published: 2024-02-20
AIP Logic functions now support automation, enabling Ontology edits to be either automatically applied or staged for user review. These automations can be triggered on existing objects or when new objects are created. This feature allows you to apply your AIP Logic functions-backed actions, such as making Ontology edits at scale, automatically to up to 100k objects.
How do I get started?
You can create a new automation from your AIP Logic dashboard using the Automations option on the right-side menu. Selecting this option opens a new view with a pre-populated automation flow based on your logic instructions. The condition will monitor an object set and trigger the AIP Logic function effect for each new object added or for existing objects.
You can also create an automation directly from the Automate user interface, as pictured below.
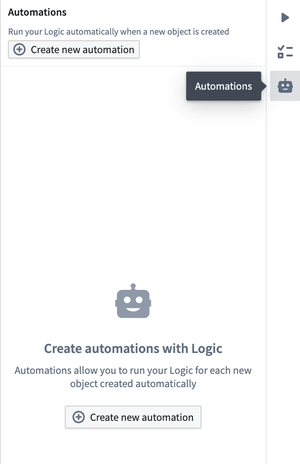
Create an automation by navigating to the Automation icon on the right-side menu.
Run effects over a set of existing objects with Automate manual execution
Automate now also supports running effects such as Actions and AIP Logic functions and triggering notifications over an existing set of objects. This feature is helpful if you would like to automatically run an AIP Logic function over an existing batch of objects, either to generate Ontology edit proposals or make Ontology edits directly.
How do I configure the effects?
After creating an automation, select Execute on the left side menu. Then, define the object to immediately execute effects. The object type in the object set must match that of the object set used when setting up the automation. To start, configure your desired batch size, then select Execute. Automations can be executed on object sets of up to 100k objects. The scheduled job will then display, allowing you to view the progress details of existing batches.
Keep in mind that if you wish to prevent effects from being executed on new objects, you must deactivate the automation by choosing the Mute option from the dropdown menu situated in the upper-right corner of your screen.
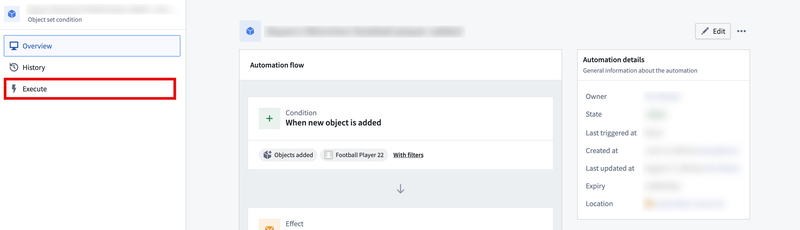
To prevent effects from an automation being executed over new objects, mute the automation from the dropdown menu.
For more information on setting up an automation, review the Automate documentation.
Introducing Foundry DevOps support for Quiver dashboards [Beta]
Date published: 2024-02-20
Foundry DevOps and Marketplace are tools for rapidly developing and deploying packages of data-backed workflows built in Foundry. We are excited to announce initial support for Quiver dashboards, available on all enrollments by mid-February.
Dashboards which use object analytics cards, object-based visualizations, and transform tables can now be packaged and deployed via Foundry DevOps as a Marketplace product. Additionally, dashboards can be packaged alongside other content. For example, a Workshop module and embedded Quiver dashboard can now be packaged together.
How to package dashboards
From the right side of the dashboard settings pane, select the Enable Marketplace templating option. Then, use the Run Validation option available in the header to identify potential Marketplace templatization issues, if any.
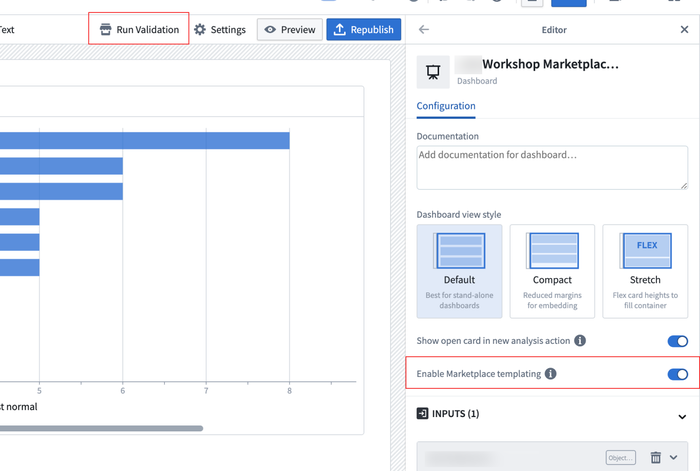
Options to enable Marketplace templating and template validation in Workshop.
If the validator does not display any errors, the dashboard's Publish or Republish options will save a Marketplace-ready version of the dashboard to be used in a new or existing Marketplace product.
View dashboard history
The Dashboards section of the Analysis History dialog also displays which dashboard versions have been validated for packaging.
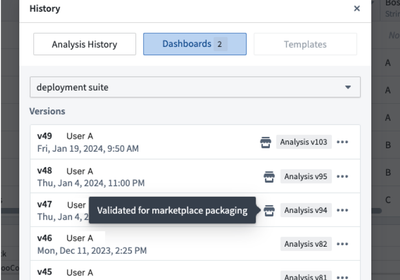
Dashboard history indicates when a version has been validated for Marketplace packaging.
What's on the development roadmap?
We are actively expanding the number of supported cards with the aim of adding time series and materializations cards in the near future. Additionally, we plan to provide a way to create a new Quiver analysis from an installed dashboard.
For more information, refer to the documentation to add Quiver dashboards to a Marketplace product.
Introducing Slate's health check dialog [GA]
Date published: 2024-02-20
With the new Slate Health Check dialog, application builders can now quickly identify and resolve failed queries and functions while preventing outdated or inaccurate data in widgets. Whereas previously errors may have gone unnoticed as they were only visible in the queries or functions panels, this new capability consolidates all errors and warnings from Slate queries and functions. By doing so, it simplifies the process of uncovering errors and facilitates a better understanding of the downstream implications on other application components.
Discover issues immediately
When a Slate application is opened in edit mode, the application automatically checks for a successful runtime of all queries and functions upon loading. However, users should note that queries with conditions may not run if the conditions are unmet in the default application state. Any errors or warnings encountered will appear in the action bar located atop the page.

Errors and warnings within your Slate application will appear in the action bar.
Select the issues icon to open the Health Check dialog. From here, jump directly to the query or function raising the issue either on the canvas or in the dependency graph view for further investigation.
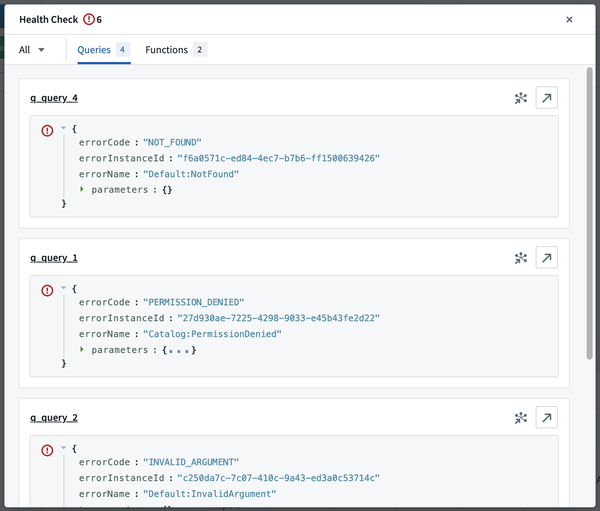
Jump directly to the query or function raising the issue.
With this, the new Health Check dialog improves the maintainability of Slate applications, particularly for large applications with hundreds of queries. This enhancement makes it easier to discover and resolve issues, ensuring a more streamlined user experience.
For more, review the documentation on debugging Slate applications.
Introducing Claude, Llama2, and other Palantir-hosted open source models on approved enrollments
Date published: 2024-02-15
Palantir AIP now supports Claude, Llama2, and other Palantir-hosted LLM models by default. The default models enabled in each enrollment may differ, and certain enrollments can take advantage of alternative models released under more permissive open-source licenses, when applicable.
A new Control Panel feature for approving terms and enabling new models is being developed and will be ready by the end of February.
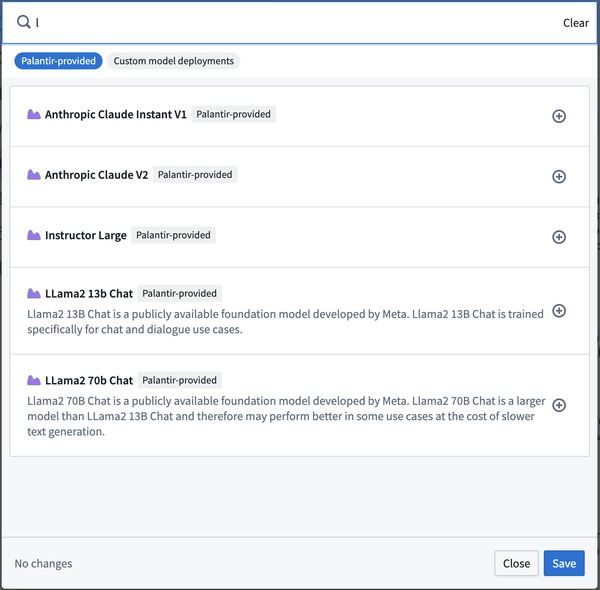
These models are now supported in Functions and transforms.
For more details, review Palantir-provided large language models.
Introducing Vega-Lite plot selection
Date published: 2024-02-13
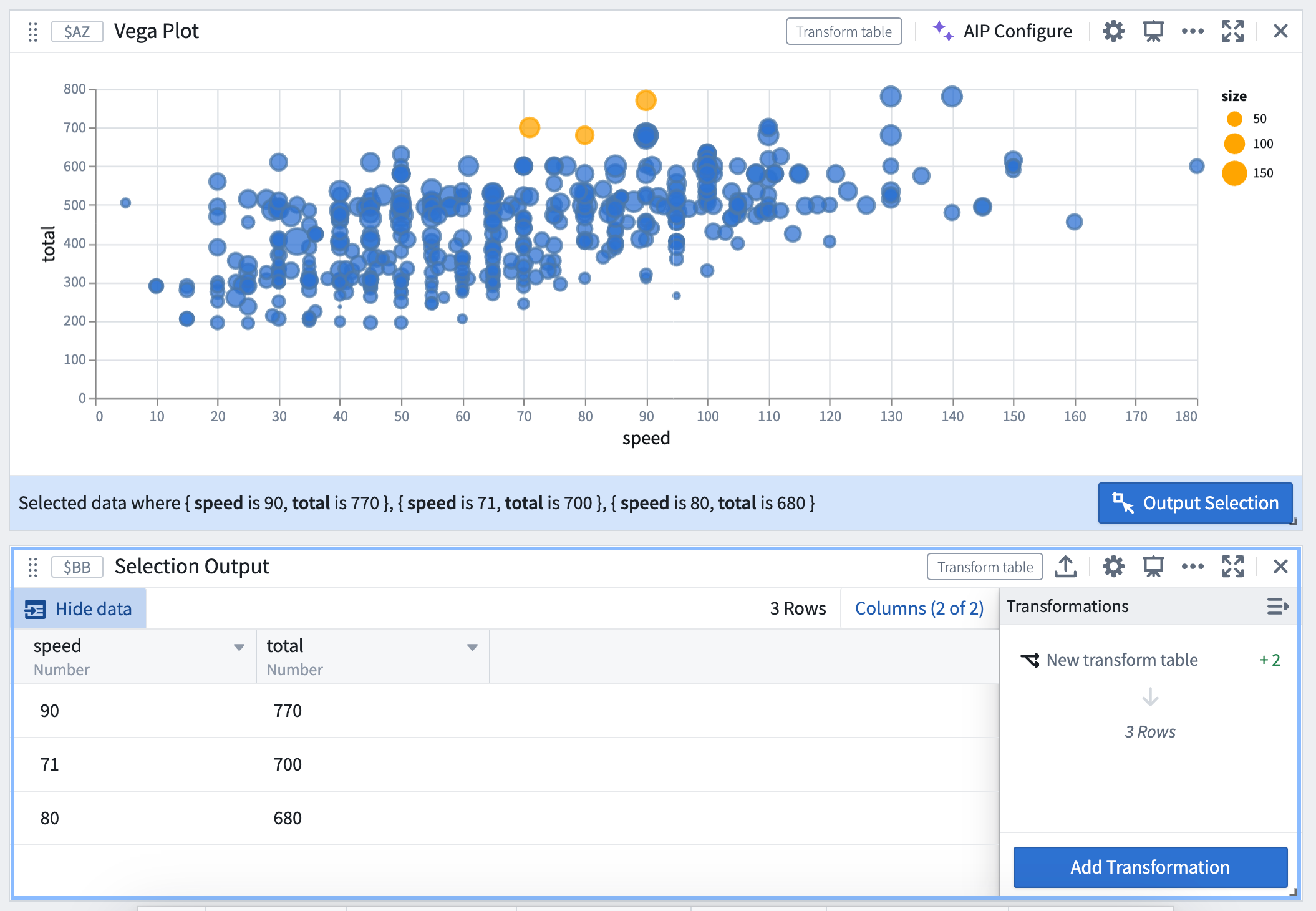
Quiver enables users to create fully-customizable visualizations using the Vega-Lite ↗ or Vega ↗ libraries. Previously, Vega plots did not support selection – a powerful and highly-customizable feature for building interactive visualizations. We are excited to announce that it is now possible to configure Vega-Lite plots to output selection data. Users can leverage the selection data to parameterize downstream cards, construct drill-down workflows, and continue analysis. Vega-Lite selection allows users to interact with charts through two types of selection:
- Point selection: Select a single point, or
Shift+clickto select multiple points. - Interval selection: Drag to select a bounded rectangular region on the canvas.
Define selection parameters
Write custom selection parameters in your Vega-Lite specification, and connect them to a transform table output by naming them quiverDefaultClick or quiverDefaultBrush. Define the encoding fields you wish to select over, such as x, y, or shape.
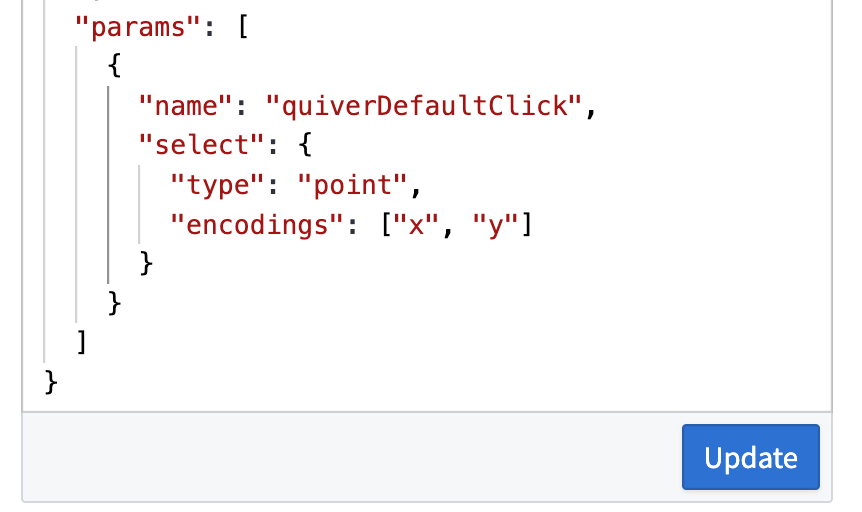
Write custom selection parameters in Vega-Lite specification.
Output selection data as a transform table
Point selections are output as a table of fields and values, where each column corresponds to a field, and each row represents a selected point.
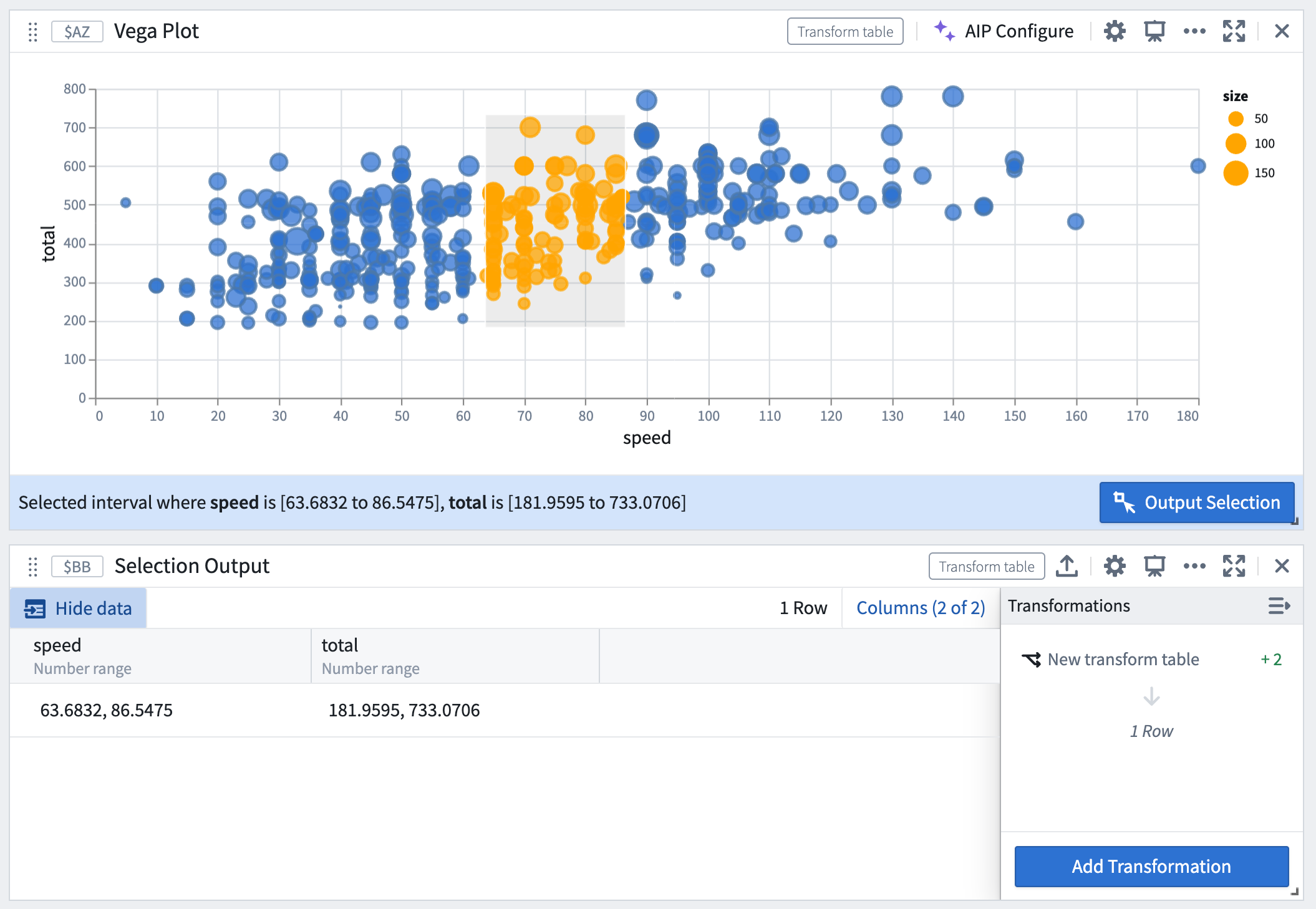
Interval selections are output as a range of the interval’s bounds if the field is continuous, or as an array of values if the field is discrete.
Construct drill-down workflows
Selection data from Vega-Lite plots can be used to construct drill-down workflows, where chart selections act as a filter and users can continue analysis on a subset of data based on the selection upstream.
For example, the image below demonstrates a workflow where selections in the Vega plot act as a real-time filter on the downstream transform table.
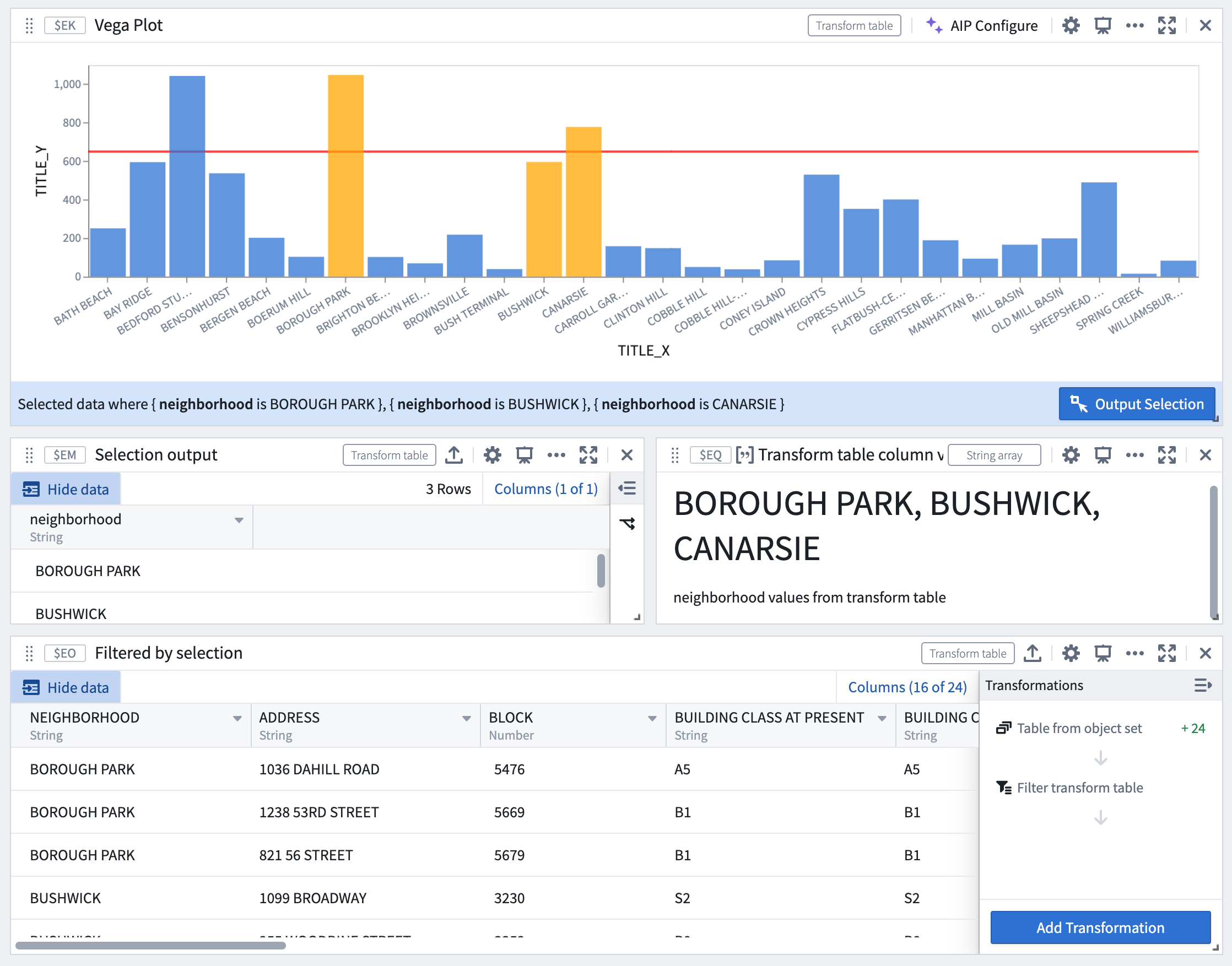
Selections in the Vega plot act as a real-time filter.
Customize selection behavior
Selection parameters can also be customized to select over different fields, or be triggered on different mouse events.
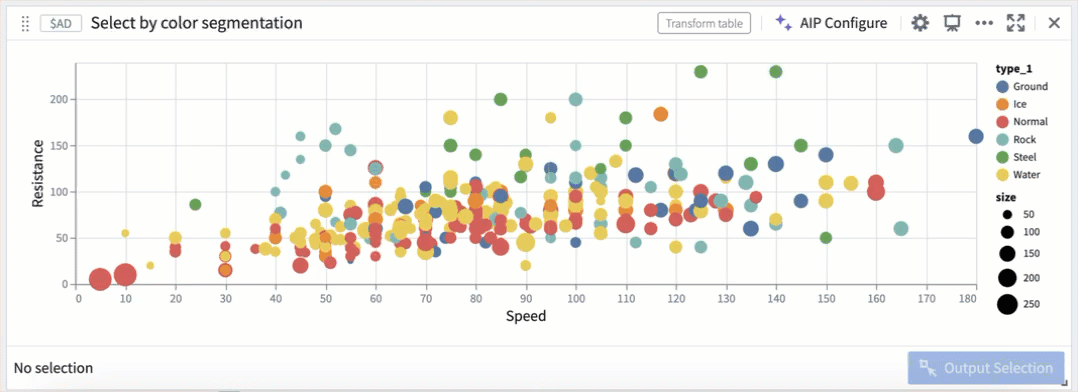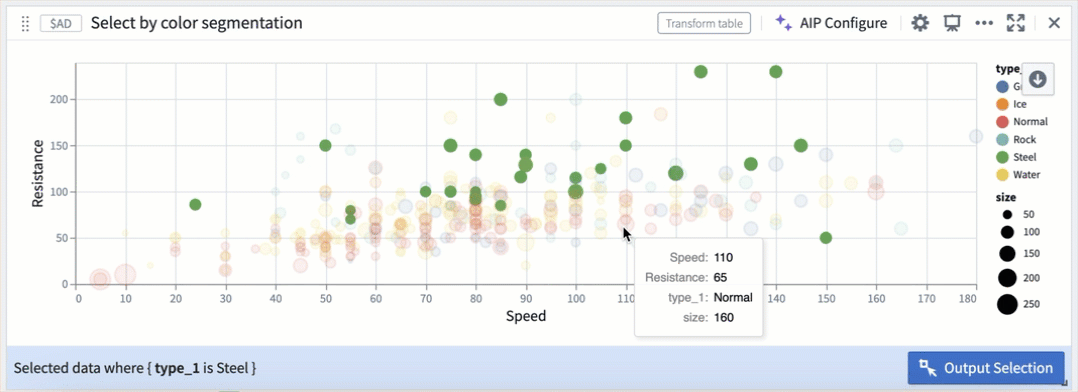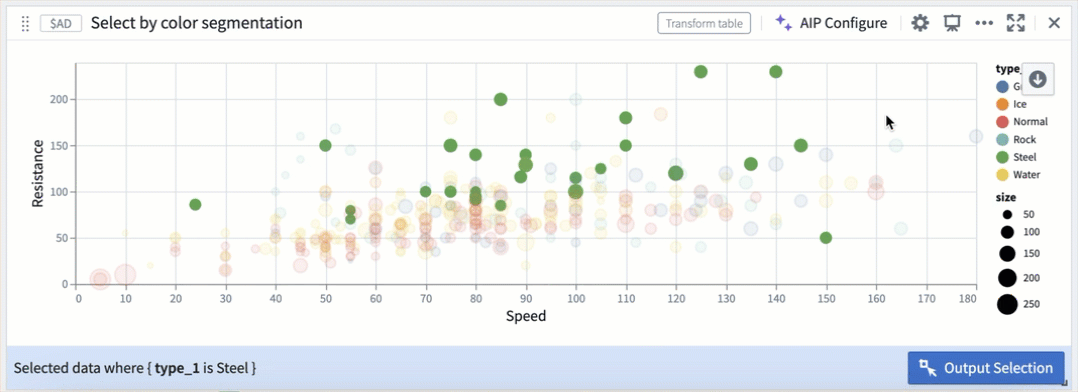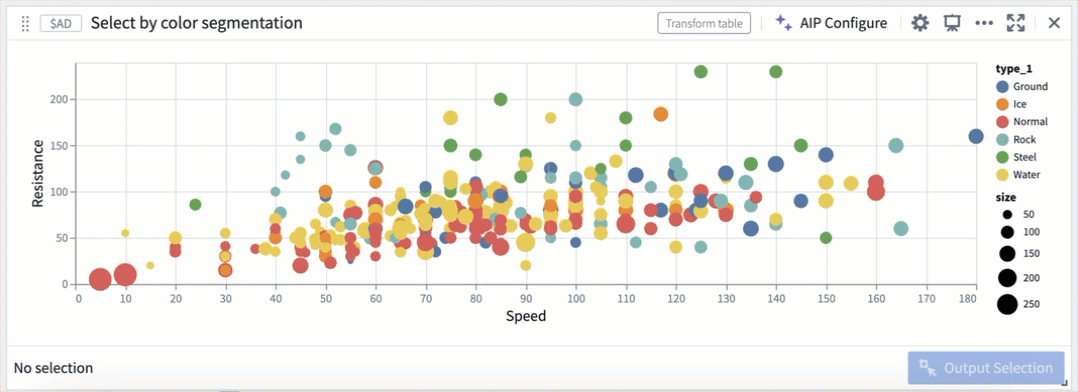
Selection by color segmentation within a scatter plot.
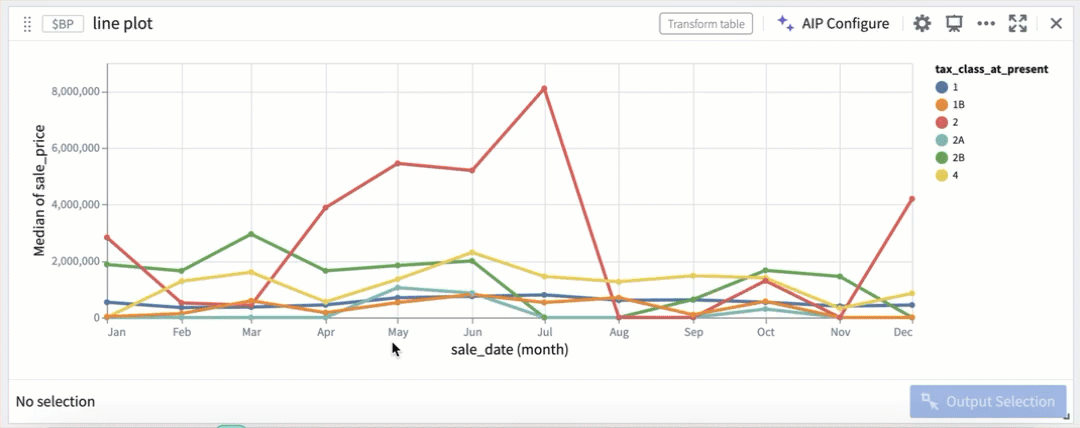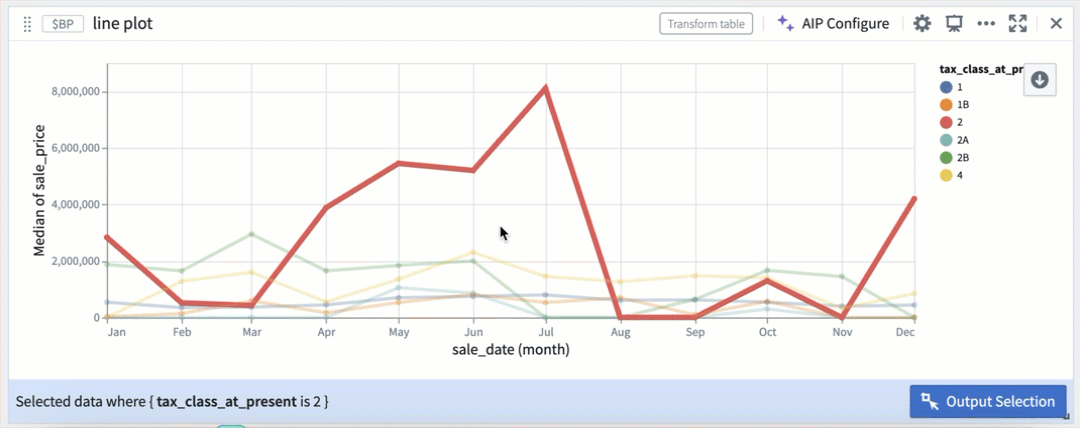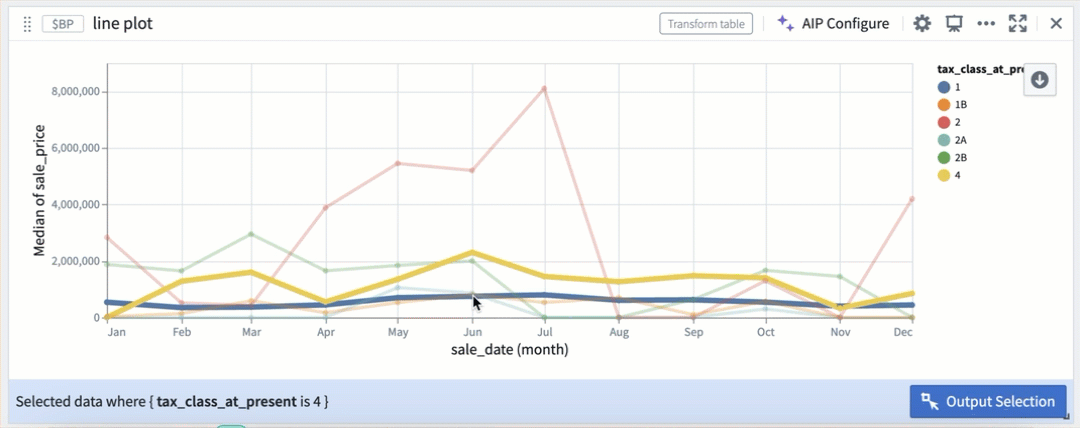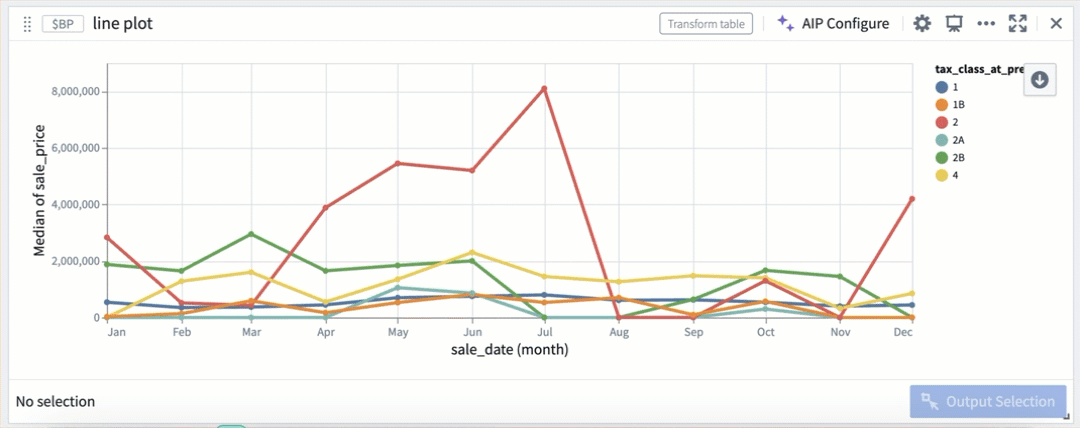
Selection by color segmentation within a line plot.
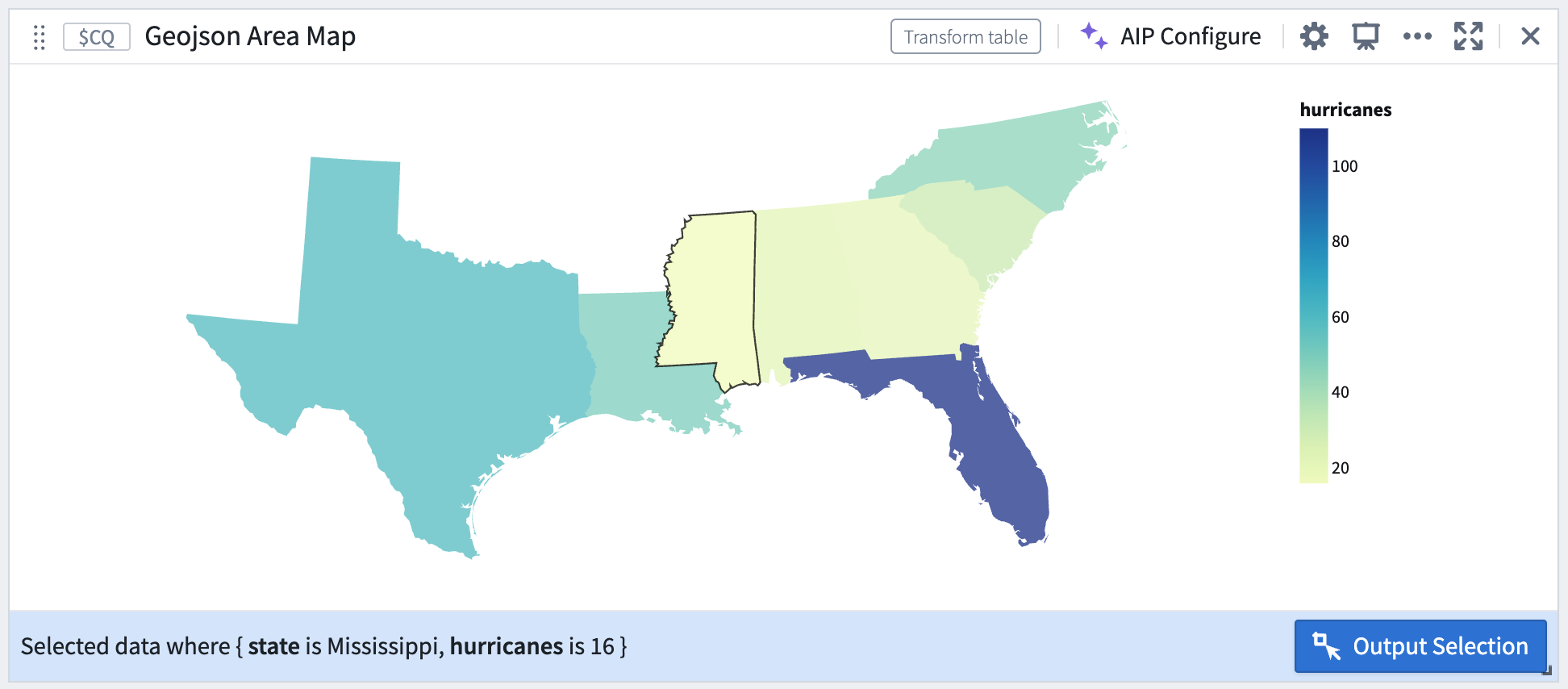
Selection by geographic area.
For more on using Vega plots in Quiver, review the documentation.
Introducing Sensitive Data Scanner [GA]
Date published: 2024-02-08
Sensitive Data Scanner (“SDS”, formerly known as "Foundry Inference") helps organizations discover and secure sensitive data within Foundry across datasets. Governance users can use SDS to define patterns of sensitive data, identify them, and automate actions to be taken when matching data is discovered. In addition, users benefit from an updated interface to accurately track and monitor launched scans.
Sensitive Data Scanner will be generally available the week of February 19 across Foundry enrollments.
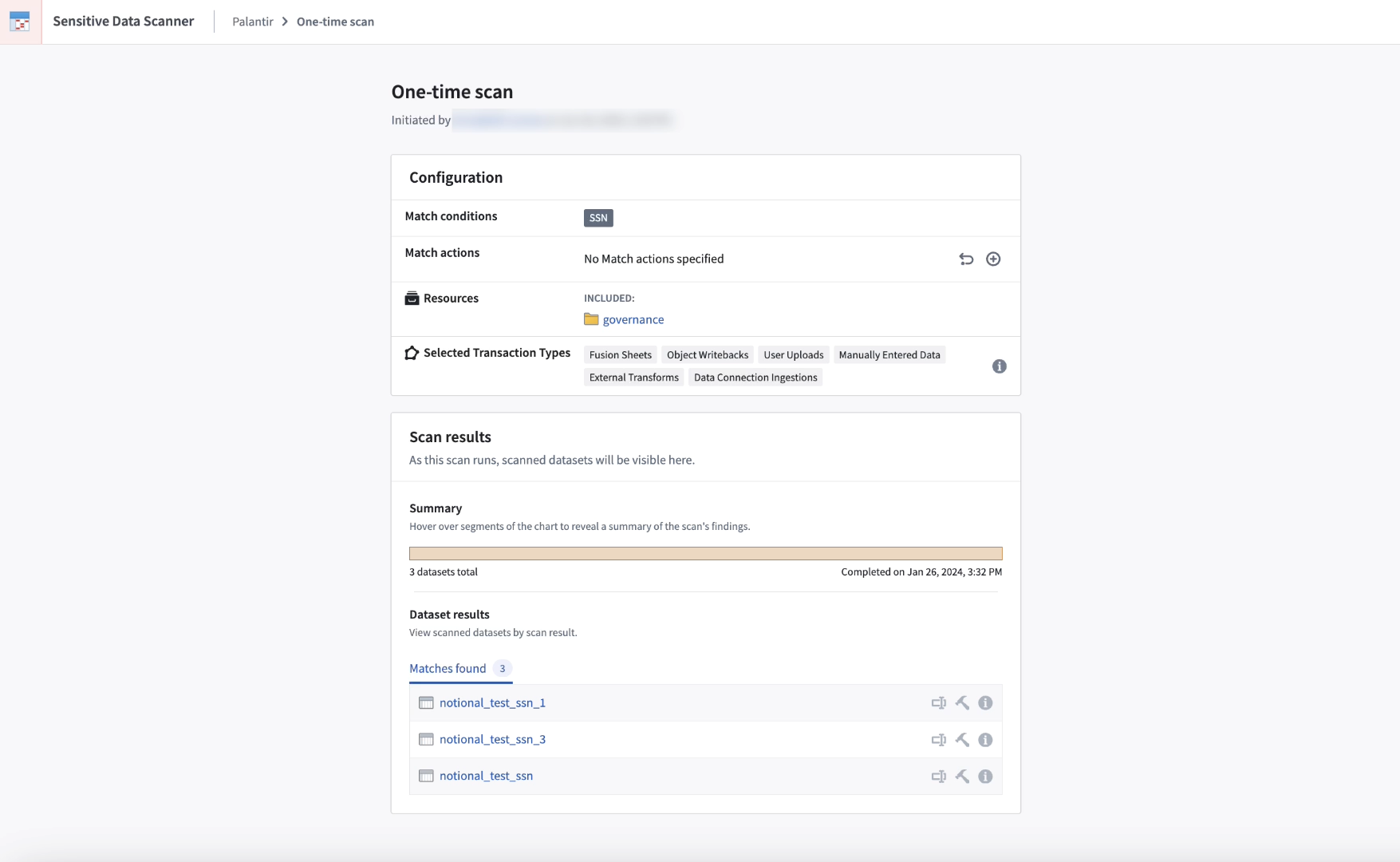
Sensitive Data Scanner one-time scan overview.
Automate discovery and protection of sensitive data
Sensitive Data Scanner (SDS) enables administrators to discover and secure sensitive data within Foundry. Setting up a sensitive data scan is straightforward and can be completed by both technical and non-technical users. First, provide a natural language prompt for AIP, or directly input regex to specify sensitive data patterns. Then, configure automated actions for Foundry to take when data matching the patterns are found.
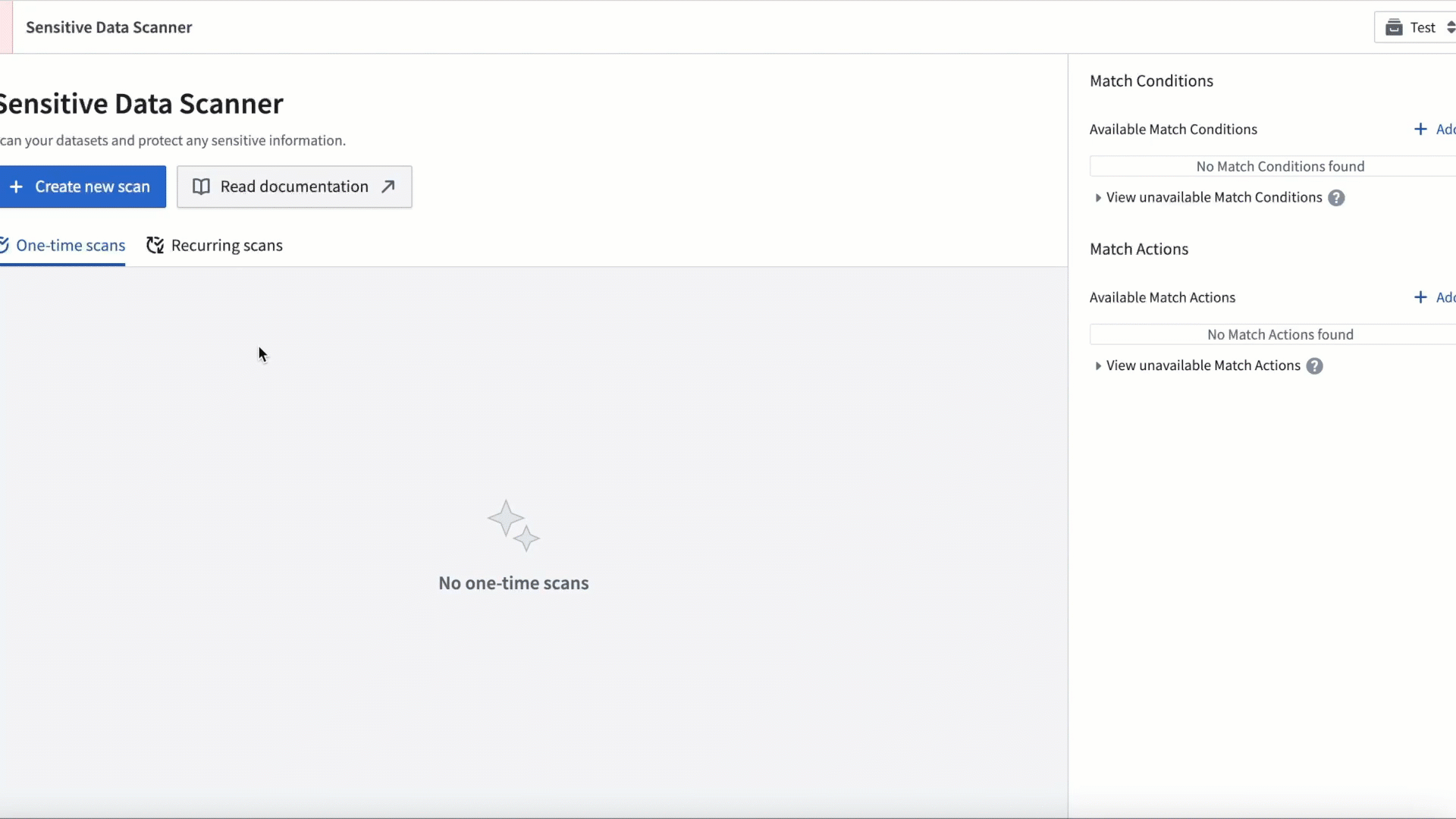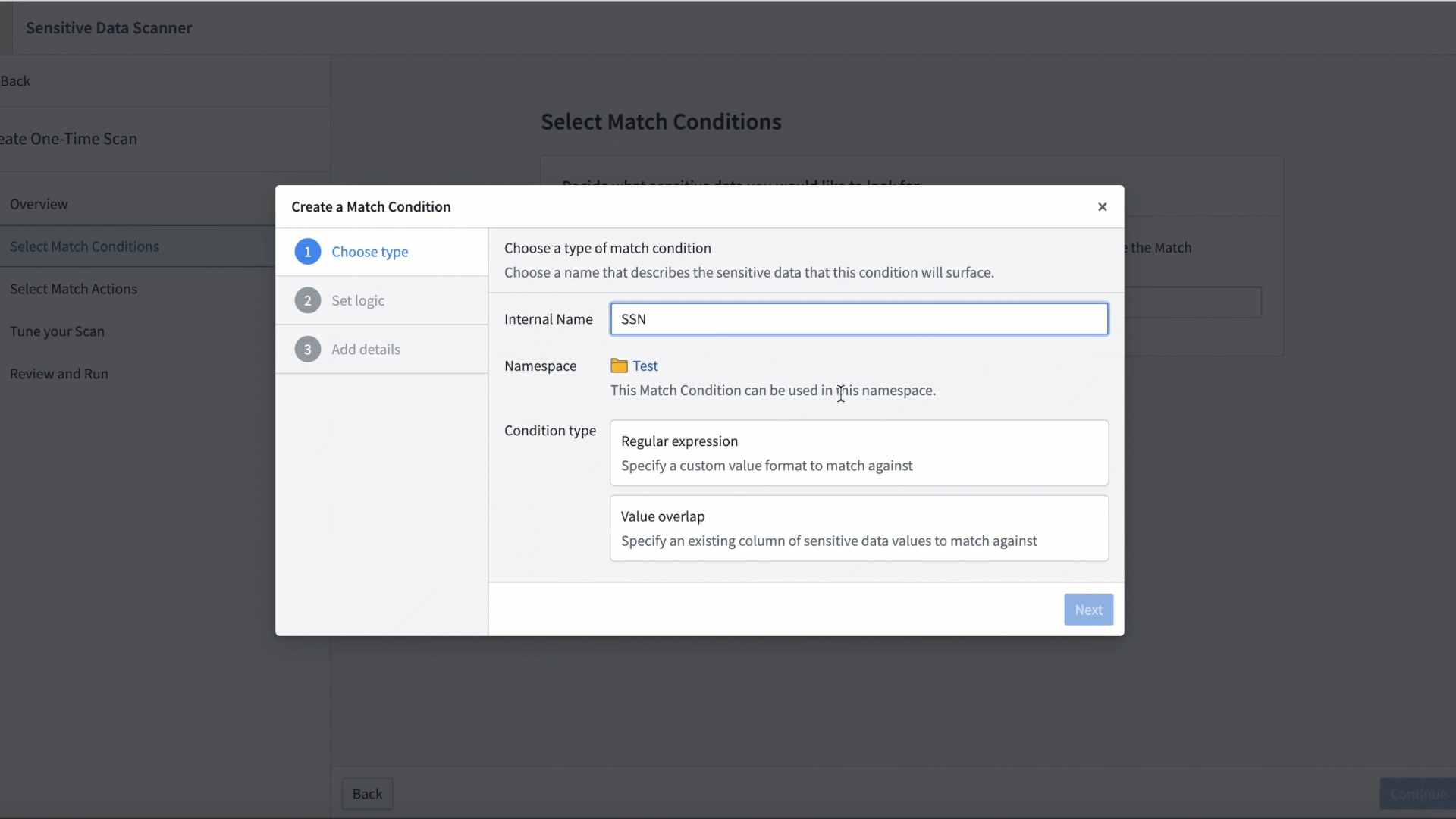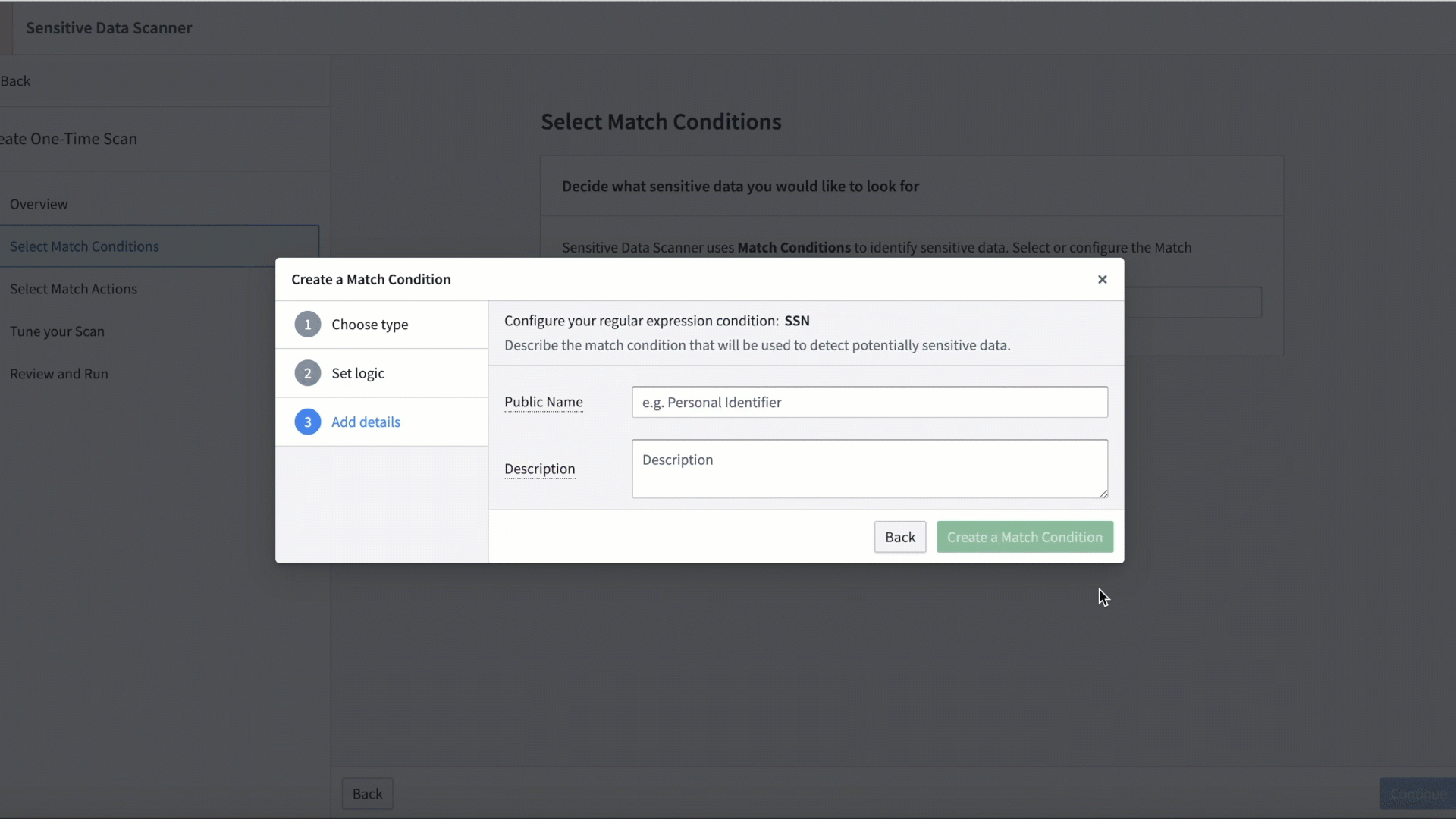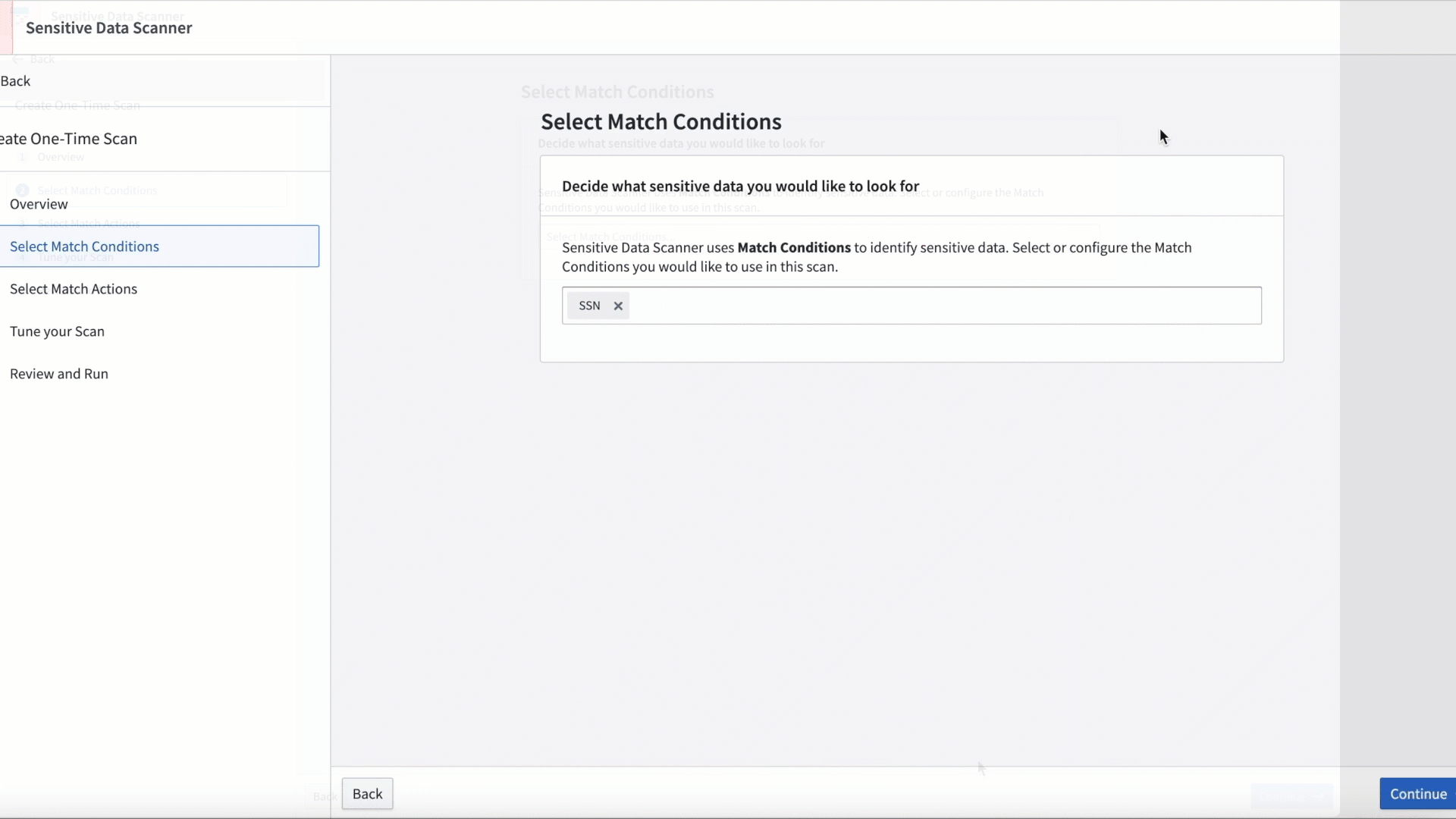
Creating a SDS Match condition.
SDS can be used for ad-hoc scans or scheduled to run on a recurring basis as new data is added to the platform.
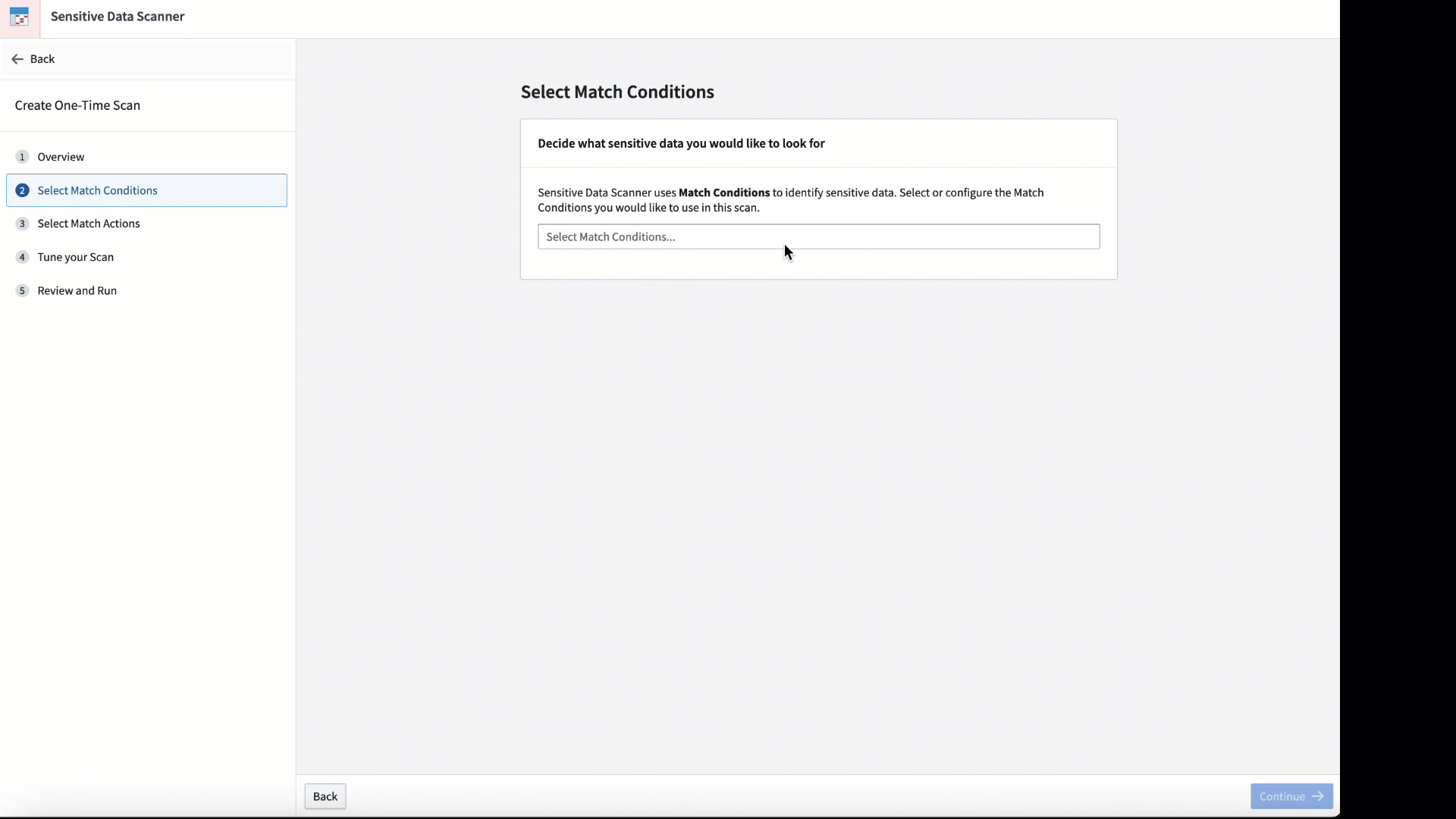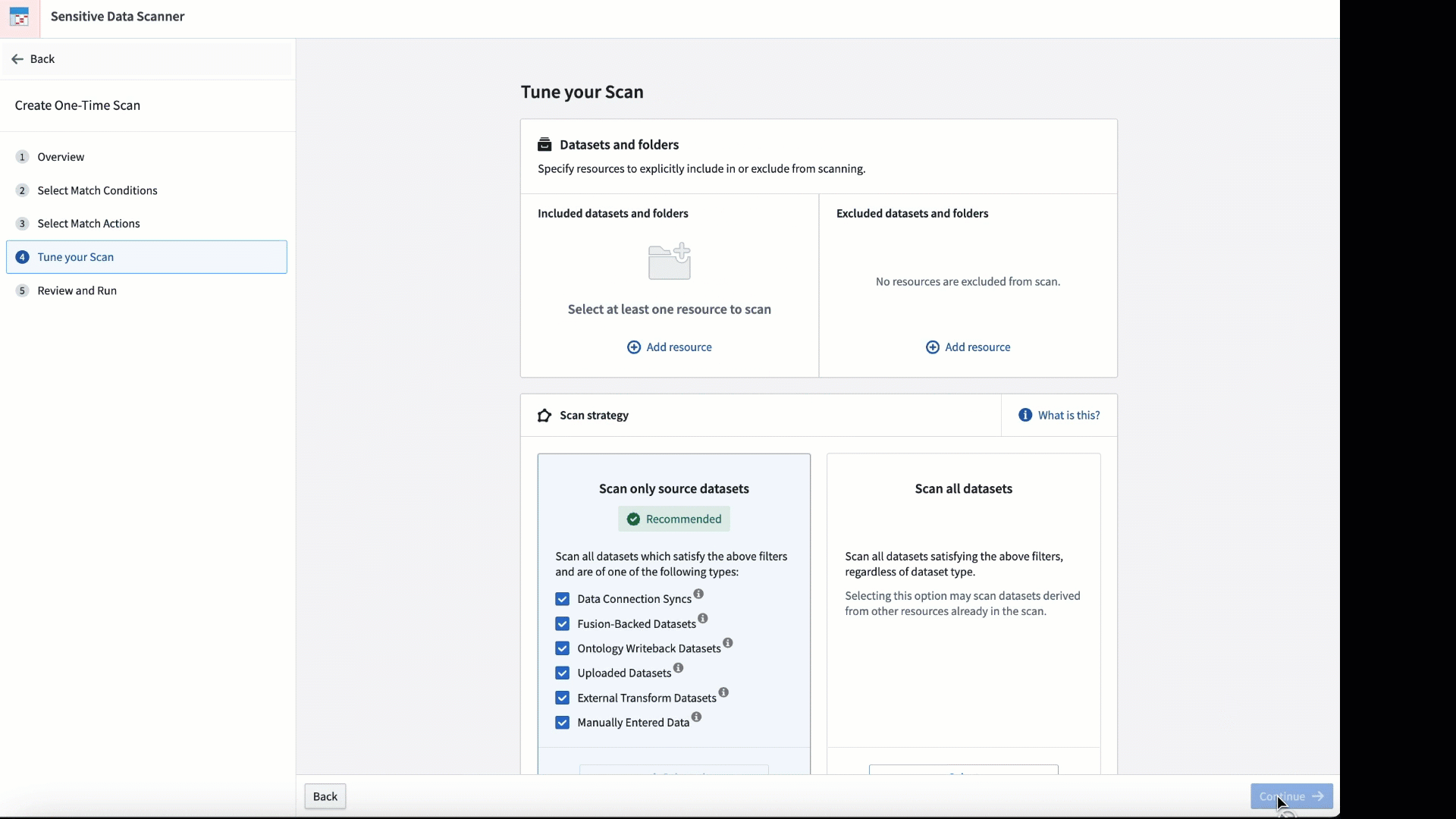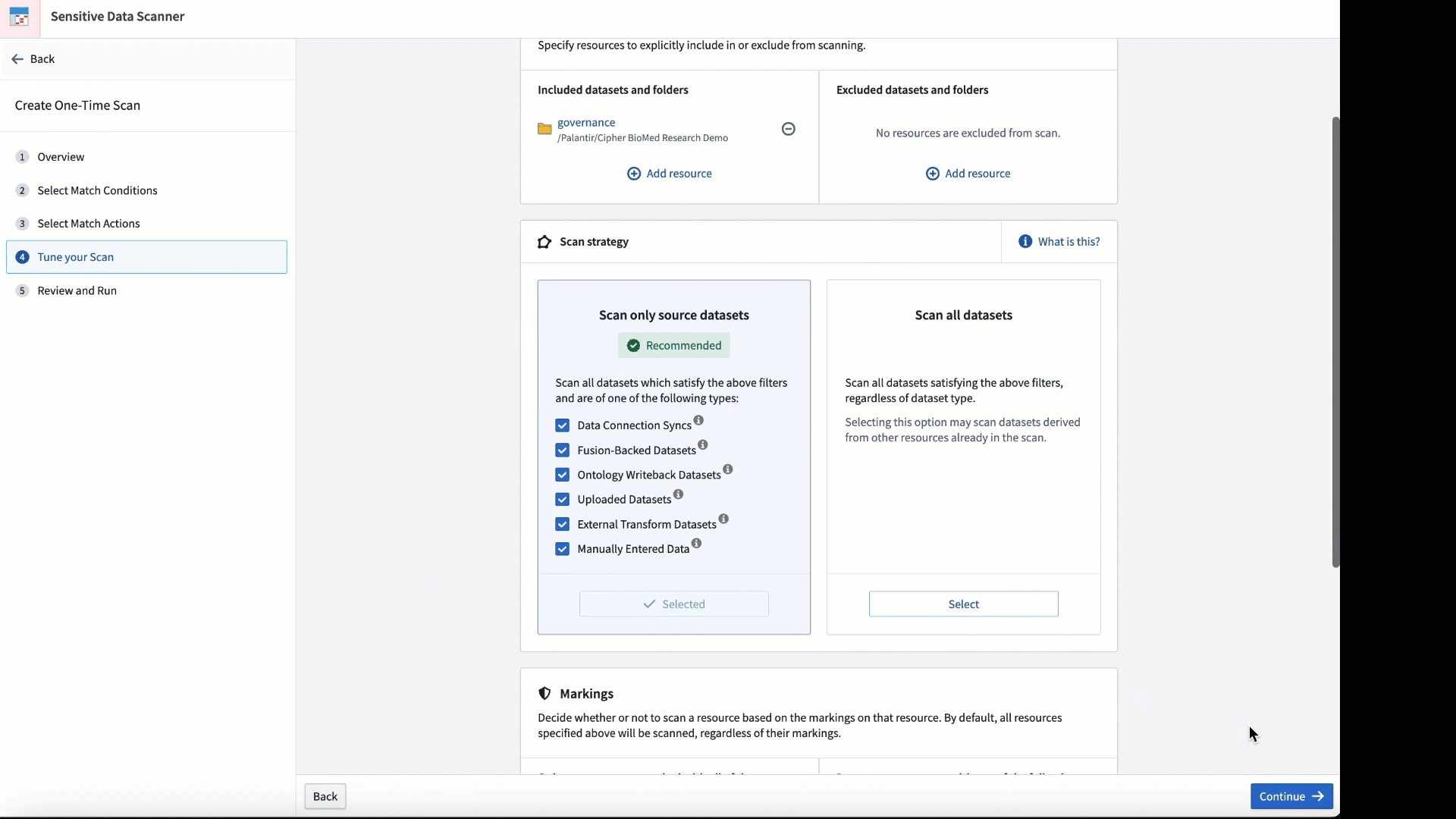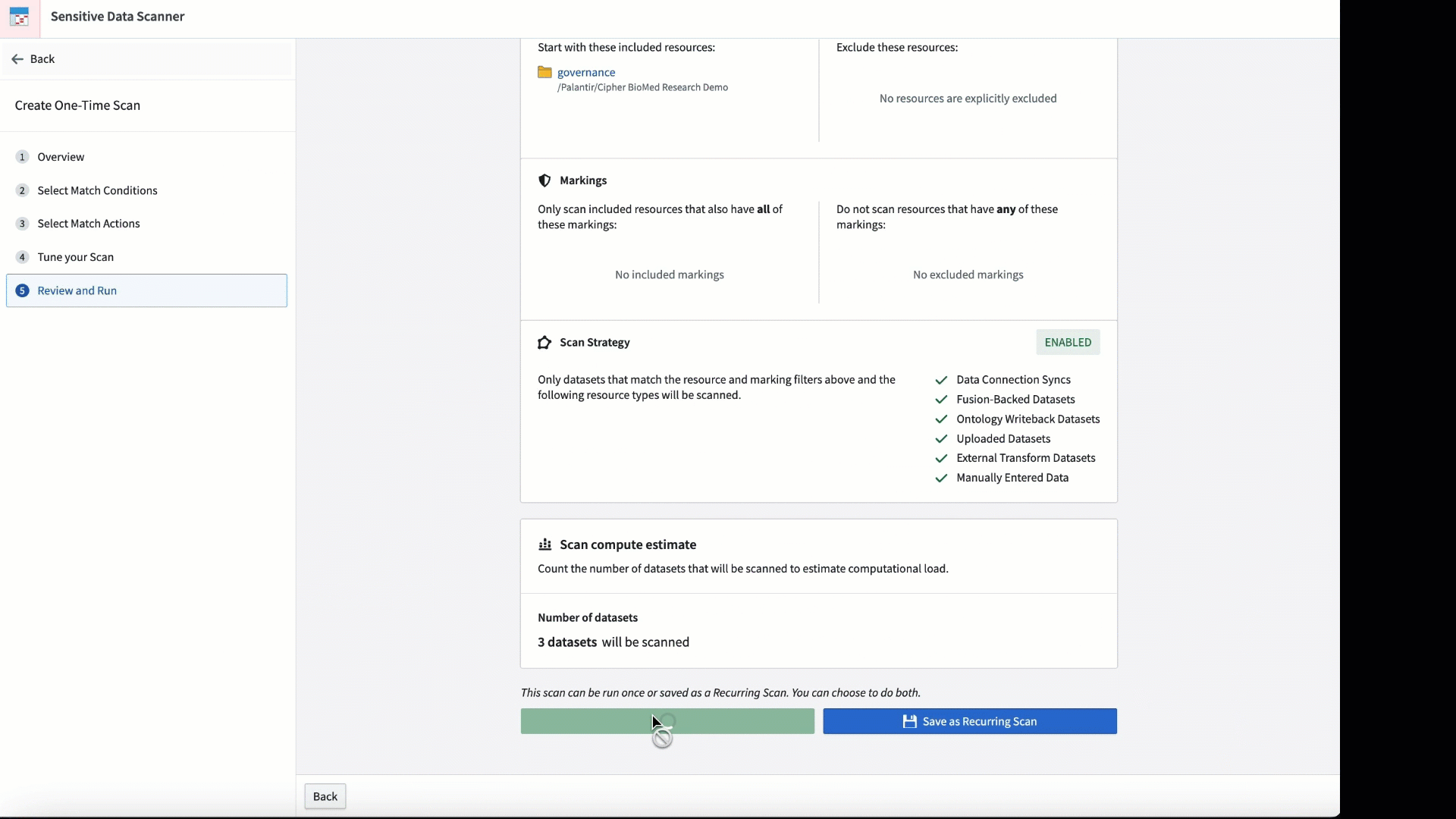
Personalize your scan by adjusting the match condition and the frequency with which the scan is conducted.
Peace of mind across multiple applications
Sensitive Data Scanner can be employed to protect your data. Consider the following notional examples:
- An organization that regularly ingests data that includes personally identifiable information (PII) through manual uploads, as well as Magritte ingests, may forget to set markings on new datasets. Recurring SDS scans can be used to prevent inadvertent leaks of PII to unauthorized users at large.
- Data Governance teams at organizations handling sensitive data can employ SDS to lockdown highly-sensitive information by executing recurring scans on datasets using an appropriate set of parameters. Members of the team can create an overlap match condition for the scan and ensure that the most sensitive data remains secured and restricted for analysis.
- An organization leveraging AIP to develop operational workflows with LLMs can apply SDS to examine text extracted from documents through optical character recognition (OCR) before integrating it into Ontology objects, which can help to prevent sending sensitive information to an LLM.
For more information, review the Sensitive Data Scanner documentation.
Introducing web hosting in Developer Console [Beta]
Date published: 2024-02-08
Developer Console will soon support hosting for static websites. Static websites contain a pre-defined number of files (for example, HTML, CSS, JavaScript) that are downloaded and rendered to the end user's browser directly as stored. Previously, to host a static web application built using OSDK, users had to use their own external web hosting solution with frameworks such as React ↗. This new feature allows developers to use Foundry to host and serve websites directly, simplifying the workflow by eliminating the need for external web hosting infrastructure.
This capability will be available as a beta feature for all Foundry managed domains by mid-February, with plans to be generally available later this year.
Host your site directly on Foundry
Configuration of static website hosting in Developer Console can be accomplished in a few simple steps. First, select Website hosting in the left side menu, then:
- Set an application domain for the site to define the URL from which users will access the site.
- Upload the asset containing the site to Foundry.
- Preview the results of your upload and publish to the site.
You can also configure access to the website and set advanced Content Security Policy (CSP) settings for your site directly from the settings page.
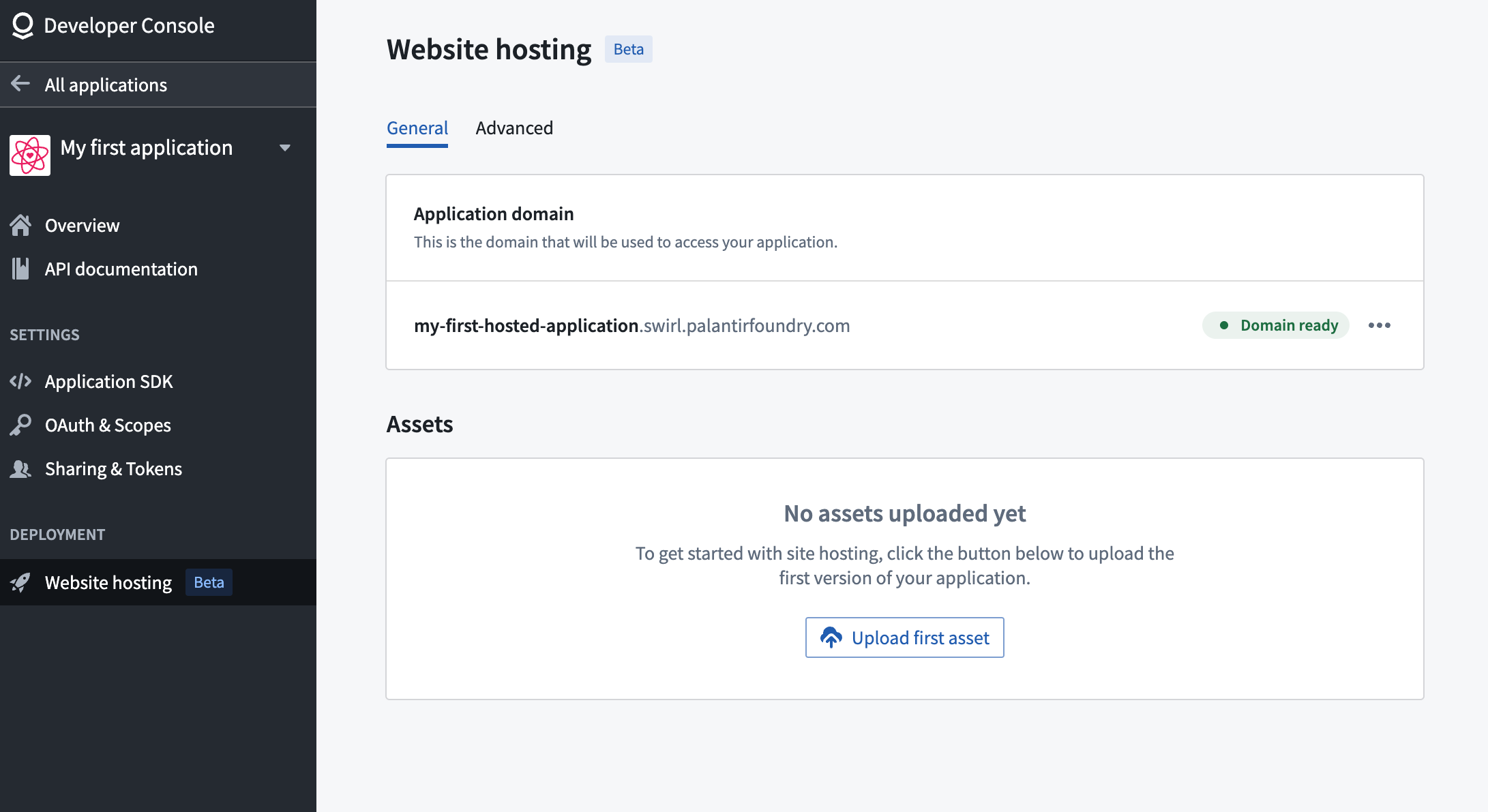
Support for static website hosting is coming soon to Developer Console.
Who can configure website hosting?
Any user with Developer Console edit permissions or an owner role can configure static website hosting. The subdomain address for the application must be approved by the Enrollment Information Officer (EIO). Approval requests can be managed within the Developer Console Settings, while EIOs grant approvals through Control Panel.
What's on the development roadmap?
We are working on enabling web hosting for customer-owned domains. Additionally, APIs for integrating site deployment to this web hosting service from your continuous integration and continuous delivery (CI/CD) pipelines are in active development.
To learn more about website hosting configuration, review Deploy an Ontology SDK application on Foundry (Beta).
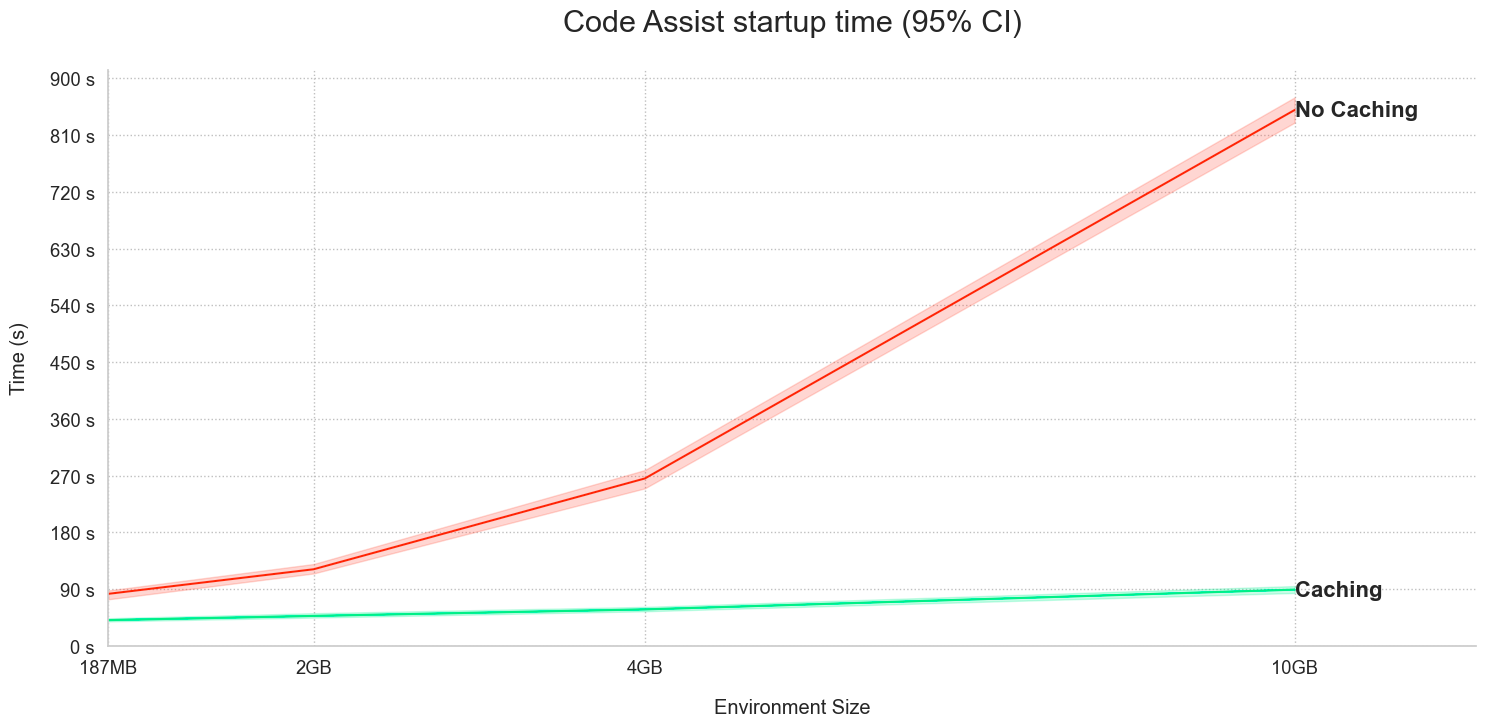
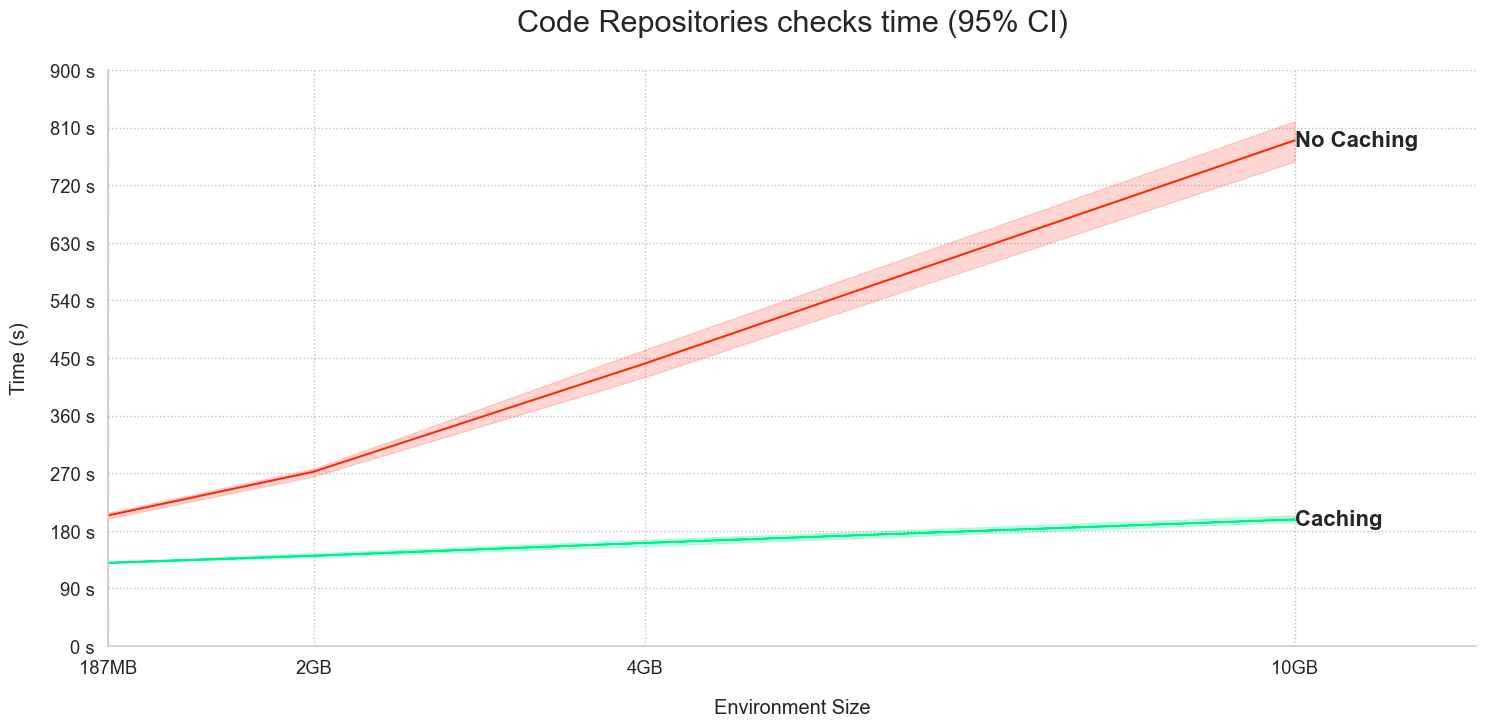
Significantly faster Code Assist startup and checks in Python Code repositories
Date published: 2024-02-01
Code Assist and Checks in Python repositories now share Python environment caches, resulting in a significant performance improvement on Code Assist startup and faster Checks (CI). To benefit from this improvement available on all enrollments, upgrade your code repositories.
The following workflows benefit from new performance enhancements:
-
Running checks: When a user triggers Checks, an environment is built and cached. Code Assist startup now performs faster by using the cached environment published by Checks.
-
Code Assist startup: The Python environment is created and cached, with Checks running faster due to the cached environment published by Code Assist. Additionally, any subsequent Code Assist startups will also use the same cache for performance optimization.
Consider the time graphs for the following two examples:
- Code Assist startup using Checks caches:
- Checks performance using Code Assist caches:
Note that this feature is not currently available when installing dependencies using the Task Runner.
New extensibility features for Lightweight Transforms
Date published: 2024-02-01
Lightweight transforms now support a wide range of data processing engines and bring-your-own-container (BYOC) workflows.
In addition to speed, Lightweight transforms are easy to connect with arbitrary data processing solutions. We have introduced a new set of APIs allowing you to quickly integrate your Foundry datasets with not just Pandas and Polars, but also DuckDB, Ibis, DataFusion, cuDF, and other data processing engines that rely on industry standard data formats, such as Arrow and Parquet. The new APIs give you additional options for running your transform with the engine of your choice based on your needs. As opposed to Spark transforms, integrating with these systems through @lightweight transforms does not incur additional serialization and deserialization overhead. For instance, the following snippet demonstrates using the Lightweight API to integrate with Apache DataFusion:
Copied!1 2 3 4 5 6 7 8 9 10@lightweight @transform(my_input=Input('/input'), my_output=Output("/output")) def my_datafusion_transform(my_input, my_output): ctx = datafusion.SessionContext() table = ctx.read_parquet(my_input.path()) my_output.write_table( table .filter(starts_with(col("name"), literal("John"))) .to_arrow_table() )
Additionally, Lightweight transforms now support BYOC workflows in which you can bring an arbitrary environment to Foundry and run executables that were previously unsupported. The next code snippet shows how you can even compile and run a COBOL program to generate data:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13@lightweight(container_image='my-image', container_tag='0.0.1') @transform(my_output=Output('my_output')) def compile_cobol_data_generator(my_output): """Demonstrate how we can bring dependencies that would be difficult to get through Conda.""" # Compile the Cobol program # (Everything from the src folder is available in $USER_WORKING_DIR/user_code) os.system("cobc -x -free -o data_generator $USER_WORKING_DIR/user_code/resources/data_generator.cbl") # Run the program to create and populate data.csv os.system('$USER_WORKING_DIR/data_generator') # Store the results into Foundry my_output.write_table(pd.read_csv('data.csv'))
For a full walkthrough of the two examples above, review the documentation for Advanced compute options and BYOC. Furthermore, additional examples can be found in the Lightweight examples product on the Reference Resources Marketplace store.
To start using the full feature set of the new Lightweight API, upgrade your repository to the latest version and install the latest version of foundry-transforms-lib-python. For more detail, review our documentation.
Introducing SMB Connector [Beta]
Date published: 2024-02-01
The SMB Connector [Beta] allows you to connect to Server Message Block (SMB) file shares and ingest files into the Palantir platform. Common examples of SMB file shares include Windows File Server, Samba File Server, and most commercial NAS devices.
Until now, our recommended pattern for connecting to SMB file shares has been to mount the share as a directory on a Foundry Agent's server and then use the Directory Connector to ingest the files. We encourage anyone using the old pattern to migrate to the new SMB Connector.
Advantages of the SMB Connector over file system mounting:
- Does not require SSH access to your agent
- Can be run as a direct connection
- Does not store credentials as plaintext on agent servers
- Persists across server restarts
For more information, review Server Message Block (SMB) [Beta] in the public documentation.
Additional highlights
Administration | Workspace
Date published: 2024-02-29
Deprecation of the Help Center sidebar | The Help Center sidebar is deprecated and replaced in favor of comparable integrations with the Foundry documentation and Foundry Issues.
Analytics | Contour
Date published: 2024-02-27
New Visualization Timezone Setting in Contour | Contour now features a new setting, Visualization Timezone, that allows users to control how date times are displayed across all boards in an analysis. This setting can be configured to either a user's local timezone or a fixed timezone, providing a unified approach to timezone behaviors. For new analyses, the default setting will be the user's local timezone. However, for existing analyses, users will need to manually select a visualization timezone. Review the documentation.

App Building | Workshop
Date published: 2024-02-27
Improved Workshop Filtering: GA Linked Object Filtering | Linked property filtering in Workshop's filter list is now generally available, allowing users to filter based on linked object properties, offering a more precise and focused search experience.
Analytics | Quiver
Date published: 2024-02-27
New Aggregation Metrics in Quiver: Exact Unique Count, Standard Deviation, and Variance | Quiver now supports new aggregation metrics: Exact Unique Count, Standard Deviation, and Variance. Users can calculate the exact unique count over a property type, though this is not supported for object types backed by Object Storage V1 and may degrade performance for results exceeding 10,000. In addition, users can now calculate the standard deviation and variance over a property type, with the option to switch between calculating sample or population standard deviation and variance. For details review the Quiver Charts documentation.
Model Integration | Modeling
Date published: 2024-02-27
Python 3.9 Support Added to foundry_ml library | We have updated the foundry_ml library to add support for Python 3.9. As per our announcement, this will be the last Python version that the foundry_ml library will support.
App Building | Workshop
Date published: 2024-02-27
Enhanced Linked Object Filtering in Object Set Editor | The Object Set Editor now supports filtering on linked objects, allowing builders to easily configure link filters, such as retrieving all 'Flights' linked to an 'Alert' with 'high priority'.
Security | Approvals
Date published: 2024-02-27
Completed Requests Now Show Completion Date in Approvals Inbox | Completed requests in the Approvals inbox will now display a "Completed on " message to aid in auditing processes. Note that the display of the user who completed the task is currently in development and will be available in a future update.
Analytics | Notepad
Date published: 2024-02-27
Improved 'Lock Data' Snapshot Security in Notepad | The Lock data feature in Notepad now mandates markings on all resources supplying data to a widget when creating a static snapshot, enhancing data security. Note that Lock data for widgets receiving data from restricted views or resources with undeterminable access controls is no longer possible. Refer to the documentation on Snapshot widgets for more details.
App Building | Ontology SDK
Date published: 2024-02-27
Enhanced Website Style Customization | Users can now configure the 'style-src' in the Content Security Policy (CSP) of their hosted websites, enabling more extensive customization of website styles.
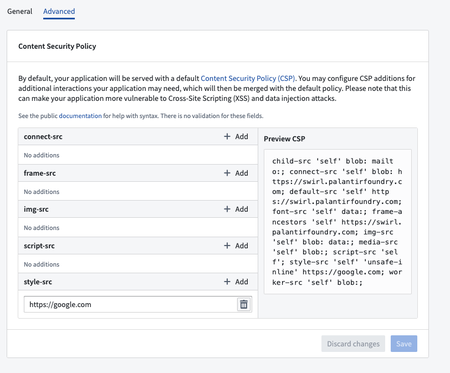
Security | Approvals
Date published: 2024-02-27
Enhanced Marking Popover Accessibility in Approval Tasks | The Approvals component now provides improved access to the marking popover within marking access tasks, such as 'Add members to marking' and 'Add marking to project constraints'. This improvement enables users to effortlessly navigate to settings for viewing markings or additional metadata, delivering a more seamless and efficient user experience.
Models
Date published: 2024-02-27
Model Training template now supports PyPI dependencies | Models produced in the Model Training template in code repositories now support PyPI dependencies. These dependencies will automatically be included in batch and live deployments through the Modeling Objectives application.
Ontology | Vertex
Date published: 2024-02-27
Improved Vertex Widget Experience in Workshop | The Vertex widget in Workshop has been upgraded to offer a more dynamic user experience. Now, whenever the Selected Objects variable is updated by another widget, the Vertex widget will automatically refresh. This ensures that users always have the most up-to-date information at their fingertips.
Ontology | Vertex
Date published: 2024-02-27
Custom Label Names for Maps | Users can now define custom label names in Maps, providing more flexibility and personalization. This update allows users to better organize and manage their data by using labels that are more meaningful to them.
Model Integration | Modeling
Date published: 2024-02-22
Python 3.9 Support Added to Modeling | We have introduced support for Python 3.9 in Modeling, enabling users to take advantage of the latest features and enhancements in Python 3.9, and further improving their ability to create and manage models in Foundry.
App Building | Workshop
Date published: 2024-02-22
Image Annotation Widget Now Generally Available | The Workshop Image Annotation widget is now generally available, allowing users to display images via media URL or media reference property and create annotations by marking areas of interest. Annotations can be easily referenced as action parameters for creation, modification, or deletion of annotation objects, with support for up to 1000 annotations per image. The widget also offers optional configuration for annotation coloring and triggering events on annotation creation. Learn more
App Building | Workshop
Date published: 2024-02-22
Object References in Markdown: General Availability | The Markdown widget within Workshop now includes Object References, enabling users to link objects to text and set up on-click events. This update enhances the reliability of written or AI-generated content by connecting it to authoritative objects in the Ontology. Custom rendering of Object References is compatible with standard Markdown features, such as lists, backquotes, tables, and more. Find more details in the documentation

Data Integration | Code Repositories
Date published: 2024-02-22
Enhanced Debugging Capabilities for TypeScript Functions in Code Repositories | The Code Repositories now offer enhanced debugging capabilities for TypeScript functions. With the new TypeScript Functions Debugger tool, you can examine unit tests in real-time, set breakpoints to pause execution, and gain a deeper understanding of your functions and libraries. For a step-by-step guide on how to use this feature, refer to the Set breakpoints documentation.
Analytics | Quiver
Date published: 2024-02-22
Create Duration Unit Parameters in Quiver | Quiver now supports the creation of duration unit parameters, allowing users to specify the types of duration units they wish to include or exclude. The configuration process is consistent with other Quiver parameter configurations, ensuring a seamless user experience.
Analytics | Notepad
Date published: 2024-02-15
Enhanced Sorting Capabilities in Templates | Notepad templates now include a Sorting configuration field in each row or section generator. This new feature allows users to sort the output of these generators by object property value, offering additional configuration options such as case sensitivity and ascending or descending order. When a Notepad is generated from the template, the generated rows and sections will be sorted according to the configured property, providing a more organized and customizable user experience.
Security | Projects
Date published: 2024-02-15
Enhanced Permission Checking | The Data Lineage application now offers enhanced permission checking for object types and Ontology Actions. Users can verify if they have the ability to view an object type or objects within that type. Any limitations from the upstream data source will also be visible. Users can also check if they have the permission to view and submit an Action, along with any potential submission limitations.
Security | Checkpoints
Date published: 2024-02-13
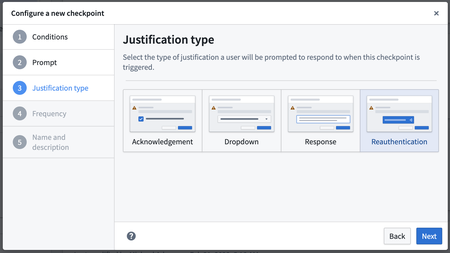
Reauthentication Justifications Now Supported in Checkpoints | Checkpoints now includes reauthentication as a justification type, alongside acknowledgements, free-text responses, and dropdown selections. This feature allows users to justify a checkpoint when performing a sensitive action by reauthenticating with the platform. When encountering a Checkpoint that requires reauthentication, users will be prompted to reauthenticate with their configured Identity Provider (IdP) in a separate window. Upon completion of the reauthentication process, users can proceed with their intended action. A record of this reauthentication justification will be available for review in the Checkpoints application by authorized users. Reauthentication justifications are compatible with all checkpoint types, excluding Login and Scoped Session Select types. For guidance on creating a checkpoint using this justification, refer to the Checkpoints documentation.
Analytics | Quiver
Date published: 2024-02-13
Quiver Time Series Chart Display Sections | Adds an Axes Options section to Quiver Time Series Charts Editor, and renames Y-Axes Compression editor.
Data Integration | Data Lineage
Date published: 2024-02-13
Enhanced permission checks in Data Lineage | The Data Lineage application now includes improved permission checks for object types and actions. Users can view whether they have access to an object type, as well as any limitations from upstream data sources. Additionally, users can see if they can view or submit actions, along with any submission limitations. To view other user permissions, users must have access to the user, underlying object types, actions, and backing datasets.
Analytics | Contour
Date published: 2024-02-13
Enhanced Parameter Cross Filtering at Higher Scales | Parameter cross filtering in Contour has been significantly improved to handle higher scales. This enhancement reduces the likelihood of hitting cardinality limits when parameter values are filtered by another parameter. Users can now create parameter filtering groups and experience a more seamless interaction with suggested values for parameters while editing or working with number parameters.
Model Integration | Modeling
Date published: 2024-02-13
Model Asset Auto Serialization | The palantir_models package has been updated to include default methods for automatic serialization and deserialization of model artifacts. Using the new auto_serialize annotation in a model adapter removes the need to manually write save() and load() methods in a model adapter.
App Building | Ontology SDK
Date published: 2024-02-13
Application search in Developer Console available | Users can now search for applications in Developer Console, providing a more efficient way to find and access specific applications.
Analytics | Quiver
Date published: 2024-02-13
New Boolean Filter Transforms in Quiver | Quiver now supports two new Boolean comparison transforms for Transform Tables, allowing users to compare and filter rows based on boolean column values.
Foundry Advanced Search
Date published: 2024-02-07
Advanced Search enhancement | Advanced Search is Foundry's comprehensive, full-screen extension to QuickSearch for finding hard-to-find resources. Advanced Search includes support for Artificial Intelligence Platform powered queries, copy-paste query sharing, and extensive search filtering.
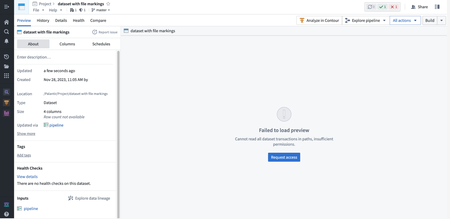
Security | Projects
Date published: 2024-02-07
Request access button added for data marking permissions | Users facing permissions dead-ends as a result of missing data or file markings can now request access to missing marking(s) in-platform using the Approvals application. For more information on Approvals, refer to the Approvals documentation.
App Building | Workshop
Date published: 2024-02-06
Easier semantic search setup in workshop | Semantic search is now easier to support within Workshop modules. Previously, Workshop builders needed to write custom typescript Functions to allow for semantic search atop objects with vector embedding properties. Now, Workshop's Object Set Definition panel allows configuring of semantic search filtering in the frontend with just a few clicks.
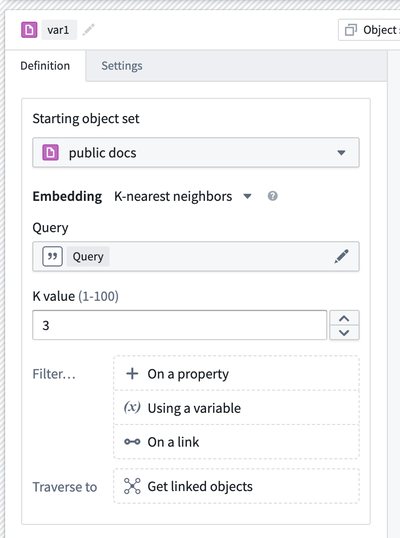
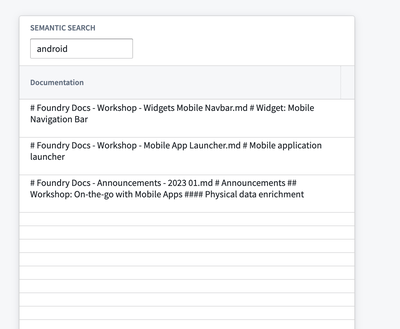
Ontology | Vertex
Date published: 2024-02-06
Vertex UI Improvements | Several UI enhancements have been made to the Vertex home page, layout selection, and timeline. Users will experience a more polished interface, with clearer object type UI, improved layout selection visuals, and reduced flashing in the timeline.
Ontology | Ontology Management
Date published: 2024-02-06
Enhanced Validation for Property Types in Ontology Manager | The Ontology Manager now includes enhanced validation to prevent saving invalid property types when reverting to Object Storage V1 to ensure data integrity and consistency when migrating property types.
Analytics | Contour
Date published: 2024-02-06
Top Values Custom Board | Introducing the Top Values Custom Board, allowing users to filter and display the top or bottom values of a column based on a specified number or percentage. This new board provides a dynamic way to analyze data and create useful reports.
Ontology | Vertex
Date published: 2024-02-06
Duplicate Annotations in Vertex | Users can now duplicate one or more selected annotations in Vertex, making it easier to create similarly-styled annotations.
Ontology | Ontology Management
Date published: 2024-02-06
Custom Error Messages for Top 20 Ontology Manager Errors | Ontology Manager now provides custom error toast messages for the top 20 most common errors users encounter when saving changes to their Ontology. This enhancement improves user experience by providing clearer and more specific error messages.
Ontology | Ontology Management
Date published: 2024-02-06
Update Input Datasources for MDO Exports | Users can now update the input datasources for multi-datasource object (MDO) export types in Ontology Manager. This allows for greater flexibility when changing input datasets for object types backed by multiple datasources.
Ontology | Vertex
Date published: 2024-02-06
Custom Label Names for Vertex | Users can now define custom label names in Vertex, providing more flexibility and personalization. This update allows users to better organize and manage their data by using labels that are more meaningful to them.
Analytics | Contour
Date published: 2024-02-06
Expanded Dataset Access in Analysis Submenu | Users can now access datasets in the Analysis submenu across all resource selector dropdown menus, improving convenience and efficiency when working with join and union boards.
App Building | Workshop
Date published: 2024-02-06
Workshop: Edits History Widget Now Available | Introducing the Edits History Widget in Workshop, which allows users to view edits made to an object's properties. Builder's can configure the set of viewable properties, and the order in which edits are displayed. This widget is only compatible with object types using Objects Storage V1, with V2 support coming later in the year.
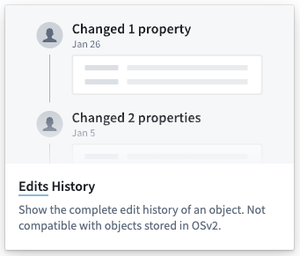
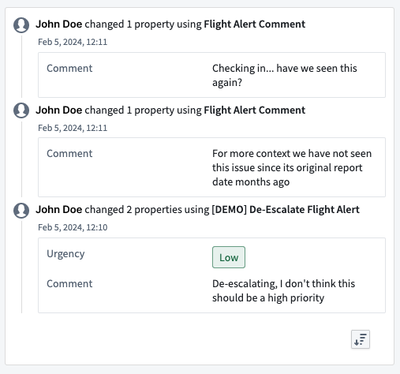
Data Integration | Code Repositories
Date published: 2024-02-06
Enhanced TypeScript Debugger for Unit Tests | Introducing enhanced debugging capabilities for TypeScript functions, allowing you to run your unit tests in debug mode. Set breakpoints throughout your code and step through the execution process to gain a better understanding of how everything works behind the scenes.
Ontology | Ontology Management
Date published: 2024-02-06
Improved Display Name Sorting in Ontology Manager | Ontology Manager now sorts display names more intuitively by combining uppercase and lowercase results. Previously, entities starting with an uppercase letter were sorted separately from those starting with a lowercase letter. The new sorting behavior groups entities starting with any letter together.
Model Integration | Modeling
Date published: 2024-02-06
Live Deployments as Functions | Users can now publish live deployments as functions and access a new deployments table for better organization and management.
App Building | Foundry Developer Console
Date published: 2024-02-06
New Permissions Page in Developer Console | Developer Console now has a dedicated Permissions page where you can manage sharing the app, sharing the website, and application discovery. The OAuth client role grants will also be moved to this page in the future.