- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
REMINDER: You can now sign up for the Foundry Newsletter to receive a summary of new products, features, and improvements across the platform directly to your inbox. For more information on how to subscribe, see the Foundry Newsletter and Product Feedback channels announcement.
Foundry Newsletter and Product Feedback channels: Available for sign-up now [GA]
We are excited to announce the release of the Foundry Newsletter and Product Feedback channels, available now for sign-up by navigating to User Settings > Notifications > Updates & News.
The Foundry Newsletter will deliver a summary of new products, features and improvements across the platform, directly to your inbox. The first (GA) Foundry Newsletter will be sent to subscribers mid-November 2023. You can also opt-in to the newly-released Product Feedback channel, which provides opportunities to connect directly with Palantir engineers seeking targeted user input. This update presents an exciting opportunity to have your voice heard and play a role in shaping ongoing developments across the Foundry ecosystem.
Newsletters and other content shared through these opt-in subscriptions will be sent to the email address associated with the Foundry user account. Note that notifications information, as well as email addresses, are stored solely within the boundaries of the Foundry enrollment and not collected centrally for Notifications communications.
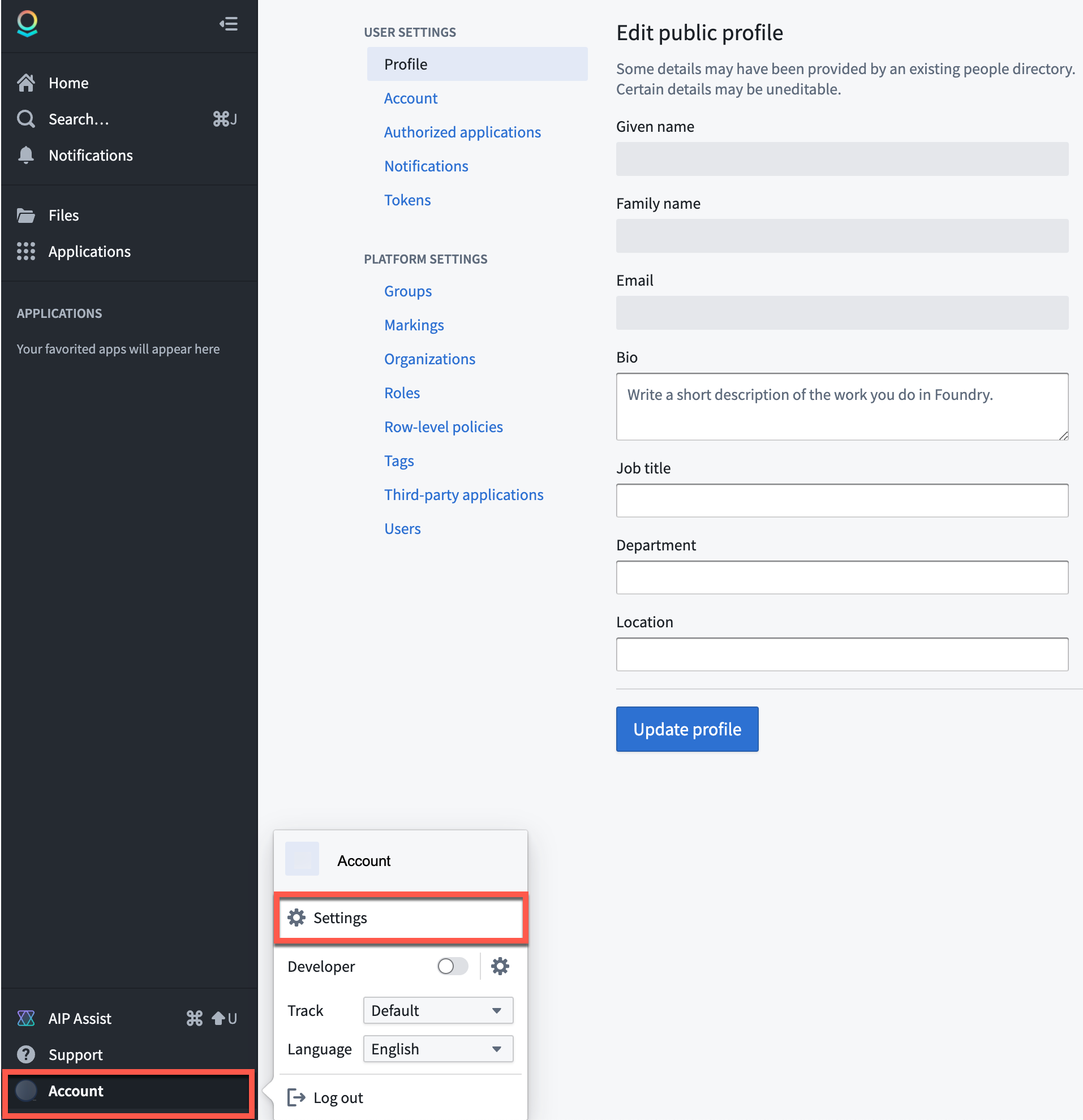
Steps to subscribe or change your notification preferences are as follows:
- Open your Foundry instance
- Navigate to User Settings:
- Select Account in the bottom left corner
- Select Settings in the pop-up menu (gear icon)
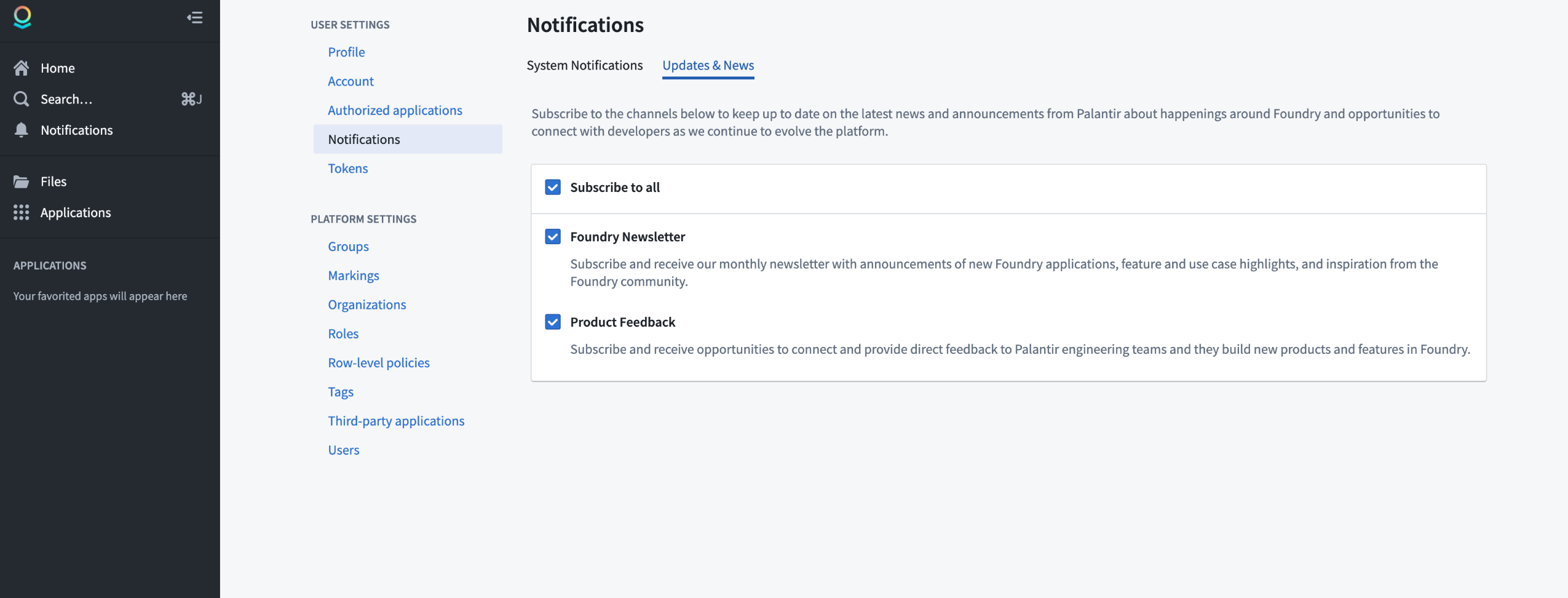
- Once on the User Settings page, navigate to the Notifications tab
- Under Notifications, select the Updates & News tab
- Subscribe to the Foundry Newsletter channel, the Product Feedback channel, or both (Subscribe to all) by checking the associated box
- To unsubscribe from the Foundry Newsletter channel and/or the Product Feedback channel, deselect the associated checkbox
Account settings
Notifications
Note for platform administrators: Platform administrators should also register their email addresses in the Foundry Control Panel settings for Contact information in order to receive important communications related to platform administration, user support, service disruption announcements, and security updates that are designed for platform administrators and separate from the Foundry Newsletter and Product Feedback channels (designed for all users) described above.
Introducing Approvals tab in Control Panel: Streamlined workflow for sensitive operations
Date published: 2023-11-30
The Approvals inbox has now been integrated into Control Panel to support Control Panel-related workflows, allowing a seamless and centrally-managed approval request review of your sensitive operations. This Control Panel integration provides version control for security configurations, enabling administrators to trace the history and rationales behind modifications made, while an added layer of visibility guarantees that teams can easily monitor and assess updates to security settings, thereby contributing to the maintenance of a secure and compliant environment. Starting now, you can review network ingress configuration requests, with additional workflows in active development.
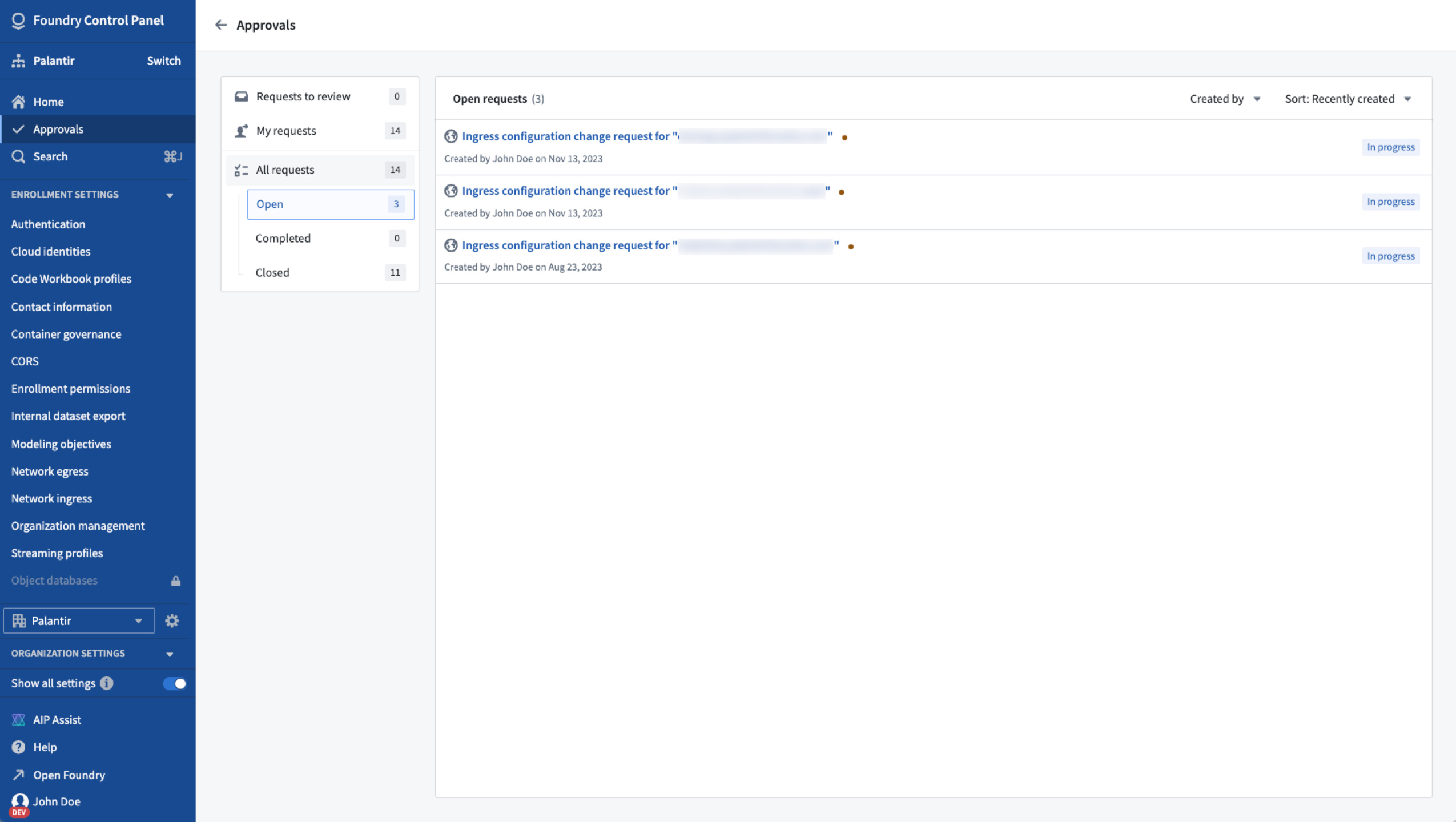
Approvals tab features an inbox with only Control Panel-related workflows, starting with ingress configuration change requests.
Manage network ingress configuration
Starting December 4, an approval will be required to enact network ingress changes. This policy change seeks to ensure a more secure and controlled process for managing ingress configurations while adhering to the platform's existing permissioning model.
Only security officers can open change requests for network ingress configuration, and by default, change requesters can approve their own changes. For a minority of enrollments that require elevated security, the workflow will be configured to require approval from a second security officer.
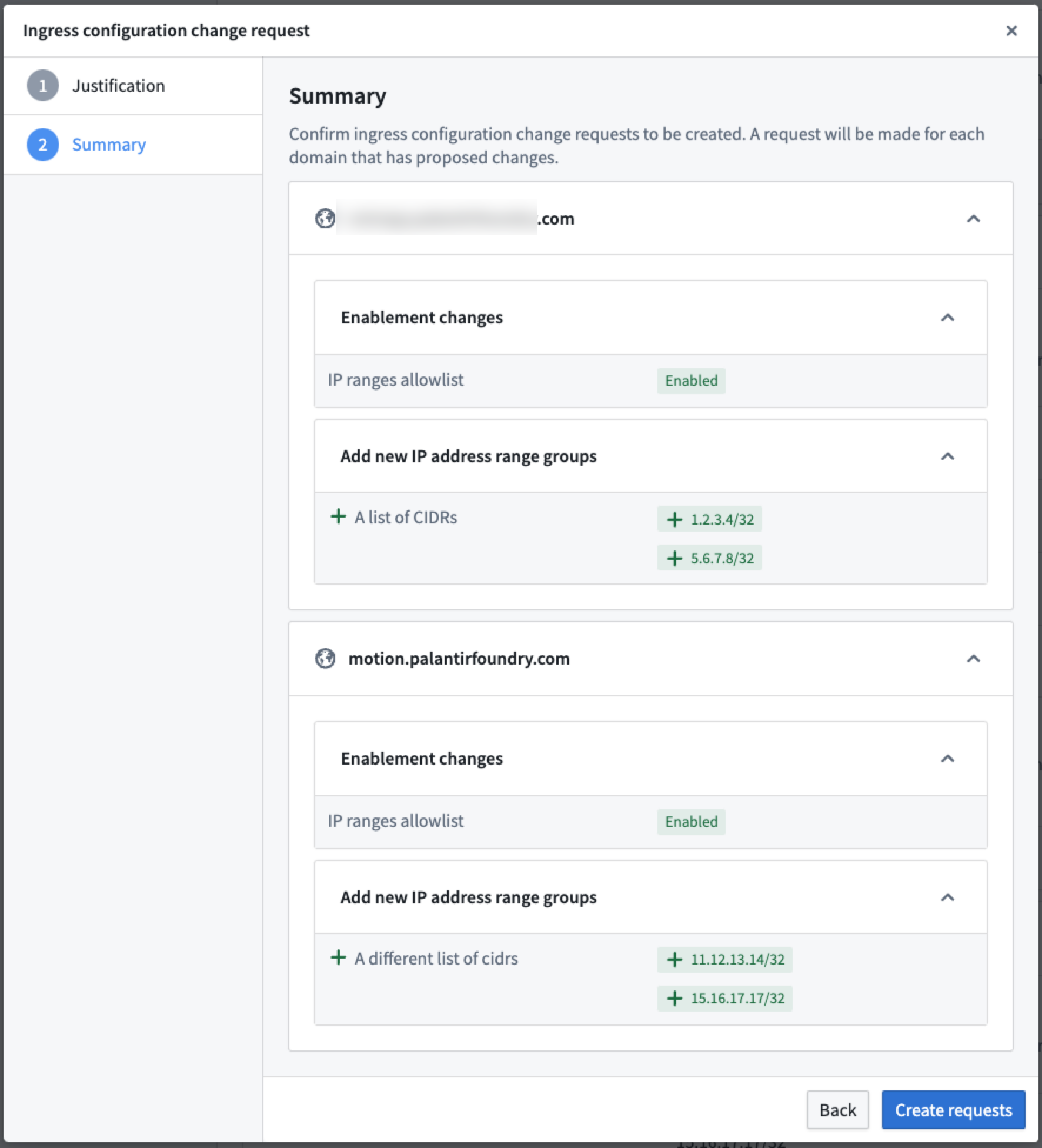
Network ingress configuration managed by Approvals within Control Panel.
What's next on the development roadmap?
Approvals' integration with Control Panel aims to bolster security and control over sensitive workflows and ensure that crucial operations are administered with appropriate oversight. The Approvals inbox will improve by adding new workflows, making sensitive task management more organized and enhancing collaboration.
For more information on how to use the approvals inbox, review Control Panel approvals. Alternatively, to learn more about managing access to the platform, review Configure network ingress documentation.
Embedded Module widgets now available in Workshop [GA]
Date published: 2023-11-28
Workshop application builders can now build reusable application components using Embedded Module widgets, now generally available. This new capability unlocks a powerful composition primitive that enhances the maintainability and reusability of use cases.
For example, consider a Workshop module that has many pages, hundreds of widgets, and thousands of variables. By leveraging the Embedded Module widget and its variable sharing capabilities, this large Workshop module can be divided into smaller, separate embedded modules. Builders can develop these focused embedded modules independently and later combine them into one Workshop module. Any parts of the module which are duplicated, for instance, a filter widget in combination with some display widget, may be separated to another module which is embedded in multiple places.
Getting started with Embedded Modules
Within the Foundry apps section of the widget selection page, locate the Workshop: Embedded Module widget as illustrated below.
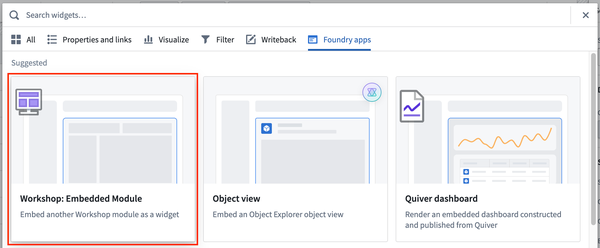
The Embedded Module widget is located on the widget selection menu.
Configure your widget by selecting a module for which the module interface variable definitions will be displayed. Then, map parent module variables to child module variables.
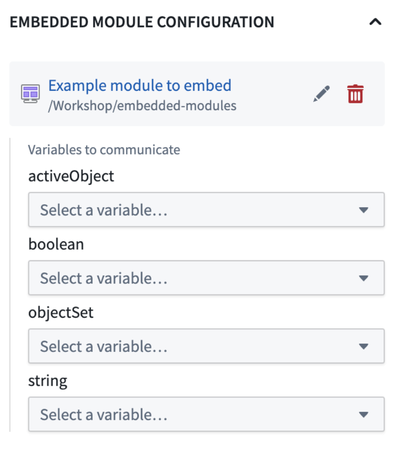
Configuration section for the Embedded Module widget for variable mapping.
For more detail, review the Embedded Module widget documentation.
What's next on the development roadmap?
Several additional improvements to embedded modules are planned, including:
-
Loop layouts: Currently in beta, these layouts will extend embedded module capabilities by allowing looping over an object set and displaying a module for each object in the set. Read the Loop layouts documentation to learn more.
-
Module interface variable experience: An improved module interface variable experience for more straightforward configuration and usage with embedded modules is in active development.
Foundry Connector 2.0 for SAP Applications v2.29.0 (SP29) is now available
Date published: 2023-11-28
Version 2.29.0 (SP29) of the Foundry Connector 2.0 for SAP Applications add-on, used to connect Foundry to SAP systems, is now available.
This latest release features minor bug fixes and several enhancements, including:
- Significantly improved throughput of batch data ingests with parallelized data extraction.
- Support for low-latency workflows by streaming data from the SAP Landscape Transformation (SLT) Replication Server to Foundry.
- Handling of multiple outputs from BAPI (Business Application Programming Interface) functions.
Download directly from Foundry's in-platform custom documentation
Starting with SP29, the add-on installation packages can be downloaded directly from within Foundry. To access SP29:
- Open the in-platform custom documentation from the bottom of the Foundry navigation bar.
- Search for "SAP" in the documentation and select the Foundry SAP Connector.
- From the How To section of the documentation, select Download the Add-On.
We recommend sharing this with your organization's SAP Basis team.
For more on downloading the add-on, consult the documentation.
Model inference history datasets [GA]
Date published: 2023-11-28
We are excited to announce that you now have the ability to create model inference history datasets in Foundry. These datasets capture all inference requests (inputs) and inference results (outputs) handled by a live deployment in a modeling objective, simplifying a wide range of workflows, including drift detection, continuous retraining, performance evaluation, and usage analysis.
Harness live deployment data
Model inference history datasets track requests and responses for live deployments. This capability provides valuable feedback for production use cases where the model developer is interested in understanding how the model is being used by real customers and users.
For example, consider the use of a live deployment to serve recommendations on a website. The model inference history records user visits and the recommendations provided to each user. With this, developers can analyze the dataset to determine the effectiveness of the recommendations for specific users. In this case, the dataset creates value by enabling usage analysis which can inform decisions about optimization and resource allocation.
While current model evaluation processes support continuous retraining and performance evaluation, these existing capabilities do not provide user feedback of model usage. As a result, and in contrast to model inference history datasets, these capabilities are more useful for those cases in which there is existing training and testing data, as opposed to live data.
Using model inference history datasets
To create a model inference history dataset, navigate to the Deployments page of your modeling objective, select the live deployment, and choose Create dataset under the Model Inference History section. We highly recommend adding security markings, as inputs and outputs may contain sensitive information.
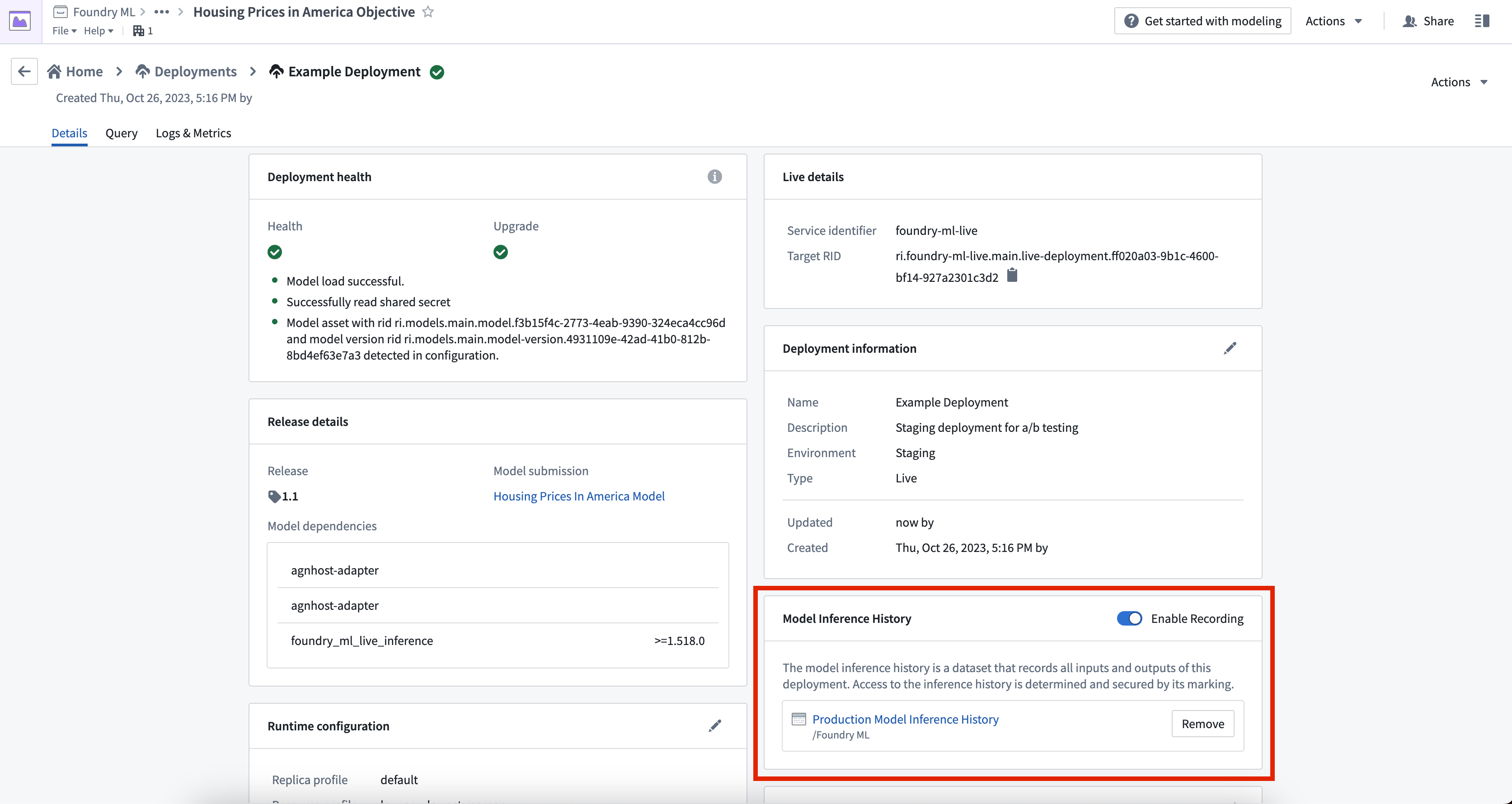
Model inference history is created from the Deployments page of your modeling objective.
Once created, the dataset will record essential information such as timestamps, user IDs, request UUIDs, and JSON representations of inputs and outputs.
Enabling and disabling datasets
To temporarily enable or disable a model inference history, navigate to the Model Inference History card and use the Enable Recording toggle. To permanently disable a model inference history, select the Remove button next to the dataset in the Model Inference History card.
For more information on this topic, refer to the model inference history documentation.
Introducing faster transforms for small-to-medium-sized datasets
Date published: 2023-11-15
We are announcing Lightweight API, an alternative to Spark transforms that capitalizes on the unparalleled performance of container transforms to speed up transforms for small-to-medium-sized datasets that do not need to rely on Spark. As an increasing number of data transforms can now be run on a single node, Lightweight API allows you to eliminate the considerable overhead from the orchestration of distributed parallelism and instead rely on single-node alternatives for authoring data pipelines.
To turn your Pandas transform into a Lightweight Pandas transform:
- Upgrade your Python repository to the latest version.
- Install foundry-transforms-lib-python from the Libraries tab.
- Import and apply
@lightweighton top of your existing decorators, as in the following code snippet:
Copied!1 2 3 4 5 6 7 8 9from transforms.api import transform_pandas, Input, Output, lightweight @lightweight @transform_pandas( Output('/Project/folder/output'), df=Input('/Project/folder/input') ) def compute(df): return df[df['Name'].str.startswith("A")].sort_values(by="Age")
Benchmark study of transformations
The benefits of Lightweight API are demonstrated when comparing the benchmarks of optimizing a complex transformation and a trivial transformation. For context, the two benchmark graphs displayed below demonstrate a controlled optimization comparison of the mean end-to-end running time across seven repetitions of five compute engines executing the same transformation logic on 19 different dataset sizes. The bands represent standard error. Each transformation was provisioned 8 vCPUs and 32 GBs of RAM. The premature ending of lines denotes an out-of-memory (OOM) condition being reached. Polars was used in streaming mode accessible through .polars(lazy=True).
The benchmark image below shows a reasonably complex pipeline containing an explode operation followed by multiple joins and a group-by, natively implemented using the APIs of Pandas, Polars, and PySpark.
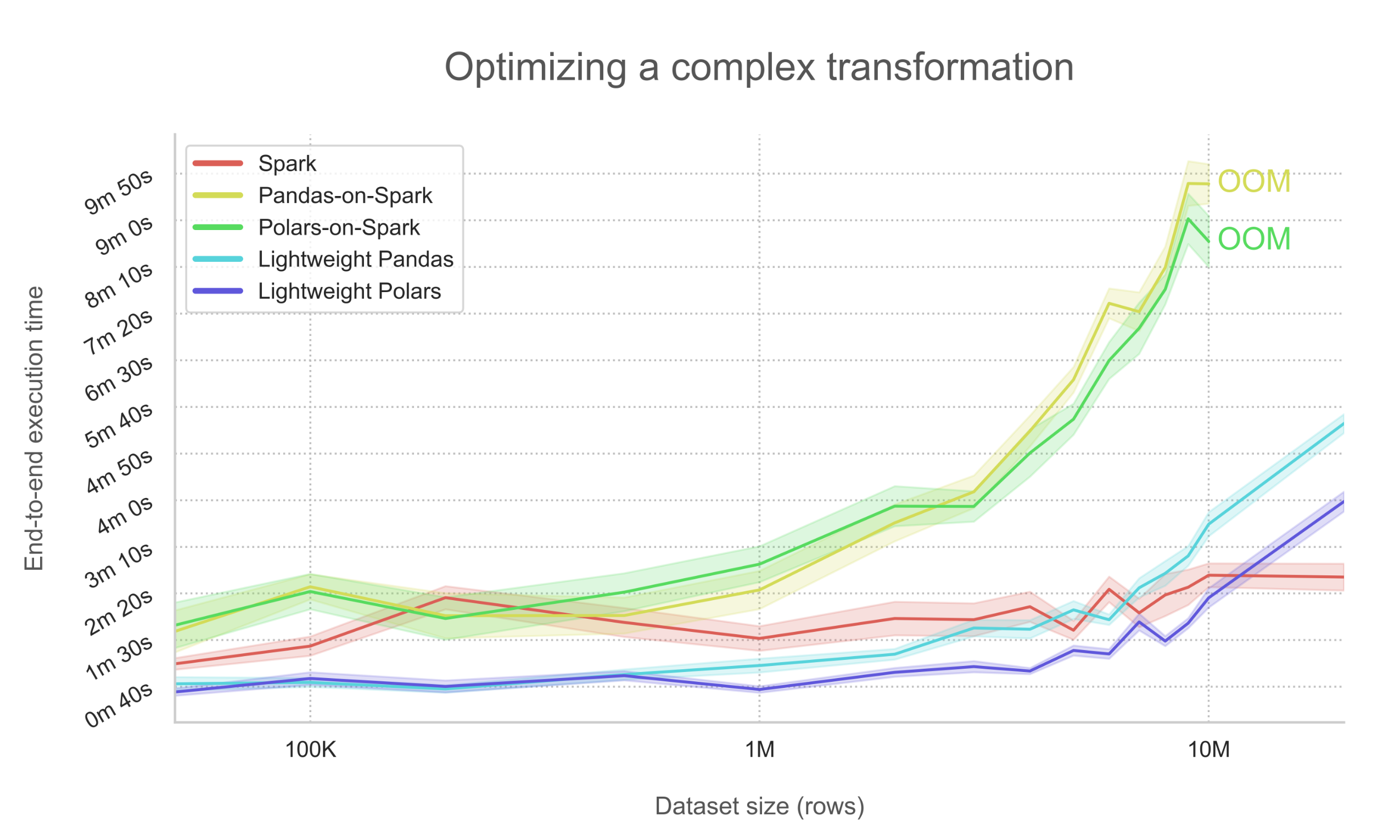
Benchmark graph showing the optimization of a complex transform
In this case, the startup overhead is nearly cut in half when using the Spark-less Lightweight backend. Additionally, both single-node optimized data processing libraries Pandas ↗ and Polars ↗ remain significantly faster up until around 10 million rows, as they do not wait for the results of network-bound shuffles as Spark does. However, for larger datasets and more complex operations, Spark's query plan scales to be much more efficient and is thus recommended in these use cases.
In contrast, applying a simpler pipeline to even larger data indicates that Spark does not always manage to outperform Polars, even on immensely large datasets.
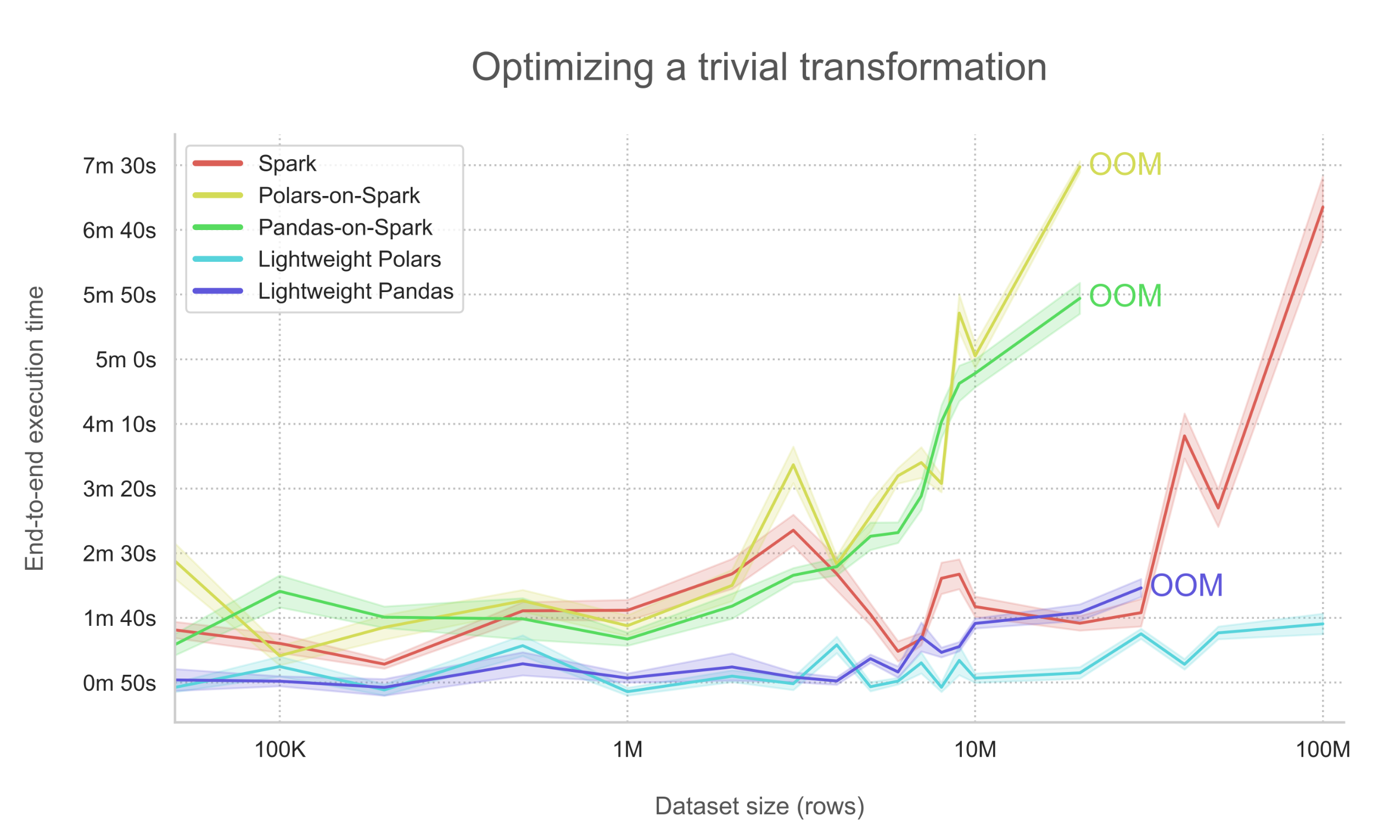
Benchmark graph showing the optimization of a trivial transform
The above chart highlights a key observation that the implemented transformation logic is close to trivial, containing only a single filter operation on a column by which the dataset is not partitioned. In this setup where the pipeline is simple (such as fewer operators and memory-friendly joins), Lightweight Polars' streaming mode ↗ vastly outperforms Spark and is recommended for all dataset sizes. As a reminder, when a @transform is decorated with @lightweight, Spark methods are not accessible.
What's next on the development roadmap?
We are actively developing Lightweight API. As such, some features including unmarking workflows or external transforms are not yet supported. The following features are coming soon:
- More compute engine support (such as DuckDB or cuDF)
- Custom Docker image support
- Incremental transform support
Additional information
In cases of smaller-scale datasets or simpler processing logic, we recommend using Lightweight transforms for faster computation.
For more details, review the documentation on Lightweight API and transform_polars or give it a try by installing the Lightweight transforms examples Marketplace product from your Reference Resources.
Support for semantic search in Foundry is now available [GA]
Date published: 2023-11-13
Palantir Foundry now supports semantic search in the Ontology with the introduction of vector properties and functions. Users can now create a vector property type for objects in the Ontology and use a K-nearest neighbors (KNN) function on objects (FoO) to enable semantic search over objects. This feature makes it possible to use the outputs of models leveraging the Ontology for more accurate results.
Semantic search capabilities in Foundry enable a range of use cases, including improved experience for documentation base users searching for a specific topic. With semantic search support, a user's query can be matched with its semantic meaning and return related objects. Additionally, with access to the Ontology, these results can then be piped back into the LLM to generate a useful user-friendly prompt boosting existing AIP builder features.
What is semantic search?
Semantic search is a search technique that takes into account the context of a query to return more accurate and relevant search results. Unlike keyword search, which simply matches whole phrases from a query regardless of context, semantic search incorporates the meaning behind the user's search terms.
Support for semantic search in Foundry is facilitated by various enhancements made to the Ontology, including:
- Introduction of vector property type in Object Storage V2 (OSv2)
- K-nearest neighbors (KNN) searches through functions on objects
Generate a vector property from a float array obtained from a Foundry modeling objective to then allow searches using KNN in a FoO function for similar vectors. For a detailed end-to-end semantic search workflow example, refer to the semantic search workflow tutorial.
Configure a vector property type
The new vector type can be used to capture embeddings from models into the Ontology. These can be created on any float array dataset field of fixed dimension. There are a few similarity functions to compare vectors that can be chosen based on use case and model output.
From within Ontology Manager, you can configure the vector property, starting with a type, choosing the dimension (output length of model that this is based on), and then selecting the similarity function that decides how you want to compare this vector property type with other objects that have the same vector property type.
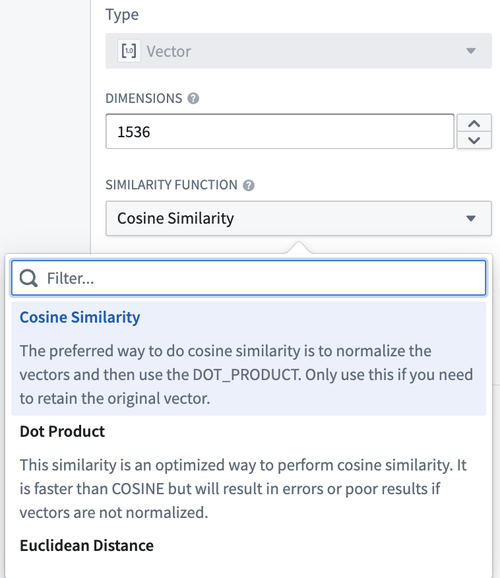
K-nearest neighbors functions on objects
The addition of K-Nearest Neighbors (KNN) Function on Object (FoO) support simplifies the process of creating a function to semantically query an object type. A live model-generated vector or existing vector from an object can be used to perform the KNN search over the object type. Review additional information on KNN FoO functions in the documentation.
For more information on topics related to this announcement, refer to following documentation:
- Create an end-to-end semantic search workflow
- K-nearest neighbors in API: Object sets
- Vector property type limitations
Introducing the ability to pin a Spark module version to a repository in-platform
Date published: 2023-11-13
We have simplified and sped-up the process of enforcing usage of a specific Spark module version (also known as "pinning") on your desired code repository. You can now select the Spark module version directly from within in-platform from the Settings > Runtime override tab of your repository in Code Repositories. Previously, this action required a manual and time-consuming CDConfig process.
As a reminder, the use of pins is intended to solely be a temporary approach. We always recommend using the most recent version of Spark to benefit from the latest performance and security enhancements.
To pin a Spark version, open your repository in Code Repositories and navigate to the Settings > Runtime overrides tab.
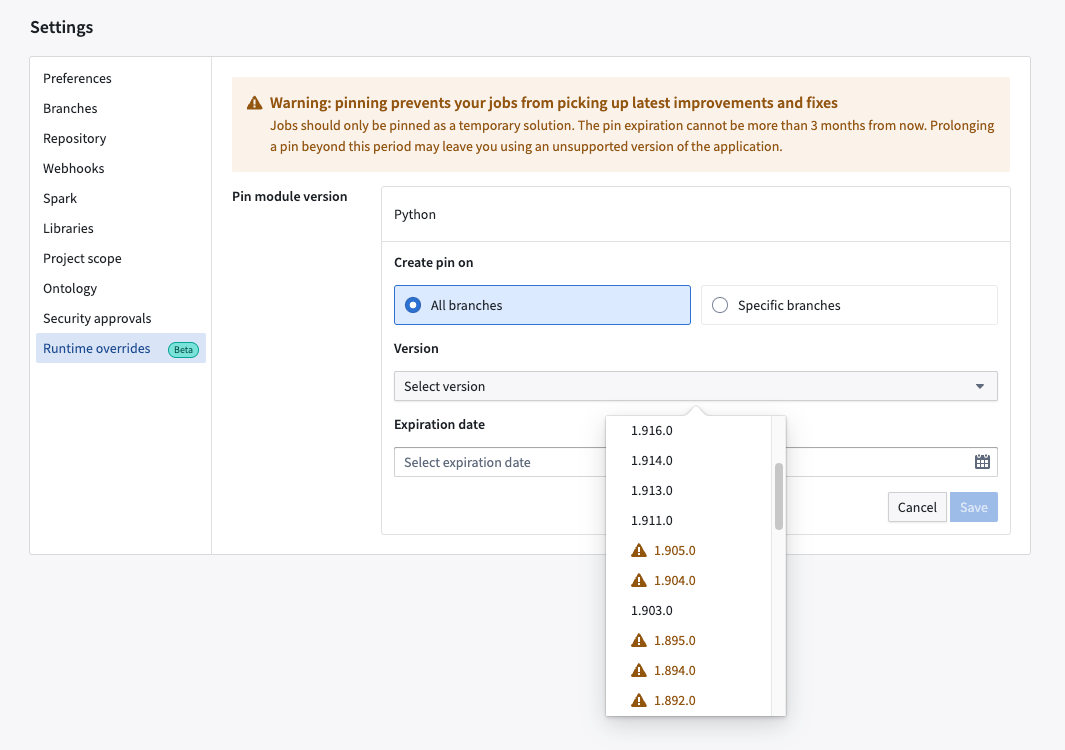
Configure your module versions in the Runtime overrides tab of your code repository's Settings view
You can Create pins and select specific Versions of Spark that you would like to pin on All branches or Specific branches. An Expiration date must be specified and cannot be more than 90 days from the current date.
Once you Save a pin, you can see confirmation in the Runtime overrides tab as depicted in the image above. Existing pins are displayed and can be Edited or Archived where they will no longer be in effect. Archived pins are tagged with an Expired label and can be restored if necessary.
The pin can also be viewed on the Build Preview > View details page:

Code repositories will display a "Pinned" tag listing the Spark module version when the feature is enabled
What's on the development roadmap?
This feature currently supports pinning Spark module to repositories. Our team is working to include pinning support for the following:
- Individual builds via the Job Tracker interface
- Pipeline Builder pipelines
For more details on this new feature, review the Pin Spark modules in-platform documentation.
Control Panel roles will now grant members Organization permissions in Platform Settings
Date published: 2023-11-02
Organization permissions are migrating in two phases from Platform Settings to Control Panel in order to improve legibility, reduce confusion, and provide greater flexibility in permission setups for platform administrators. Currently, the controls which govern how users experience Foundry, including the management of permissions, membership, marking categories, and group memberships are managed in the Platform Settings interface but will be consolidated to Control Panel by this move.
-
Phase 1 (Starting the week of November 20th): Platform Settings workflows/permissions added to Control Panel roles.
-
Phase 2 (Expected Q1 2024): Remaining members of Platform Settings permissions are migrated to the Control Panel roles that contain the workflows/permissions. Once users have been fully migrated, legacy Organization platform settings will solely be available in Control Panel. The details of phase 2 changes will be communicated in a future announcement.
Review the following notice carefully to understand how permissions updates will affect you and your Organization.
Why are we doing this?
We have seen instances where users are confused by which permissions are granted in Control Panel vs. Platform Settings. Consolidating into a single UI improves clarity and reduces the complexity of administrative workflows.
The current permissions system is inflexible and burdens top-level administrators with excessive workload due to their exclusive access to certain tasks. Roles in Control Panel allow for customization out of the box, and permissions for these workflows can be granted in a granular manner via custom roles.
How will these changes impact users and existing permissions?
By the end of Phase 2, all existing permissions will be automatically migrated and result in no loss of access or privileges. However, there are a few important changes to note:
Phase 1 changes (Effective the week of November 20th)
To shift away from using Platform Settings permissions, we first have to grant these permission/workflows to roles in Control Panel. One new role will be created, and some existing roles will have new workflows added, resulting in existing role members gaining additional permissions inline with the description of the role.
We recommend you review the changes below against your Organizations' role memberships in advance for considerations of security and update roles in Control Panel where necessary.
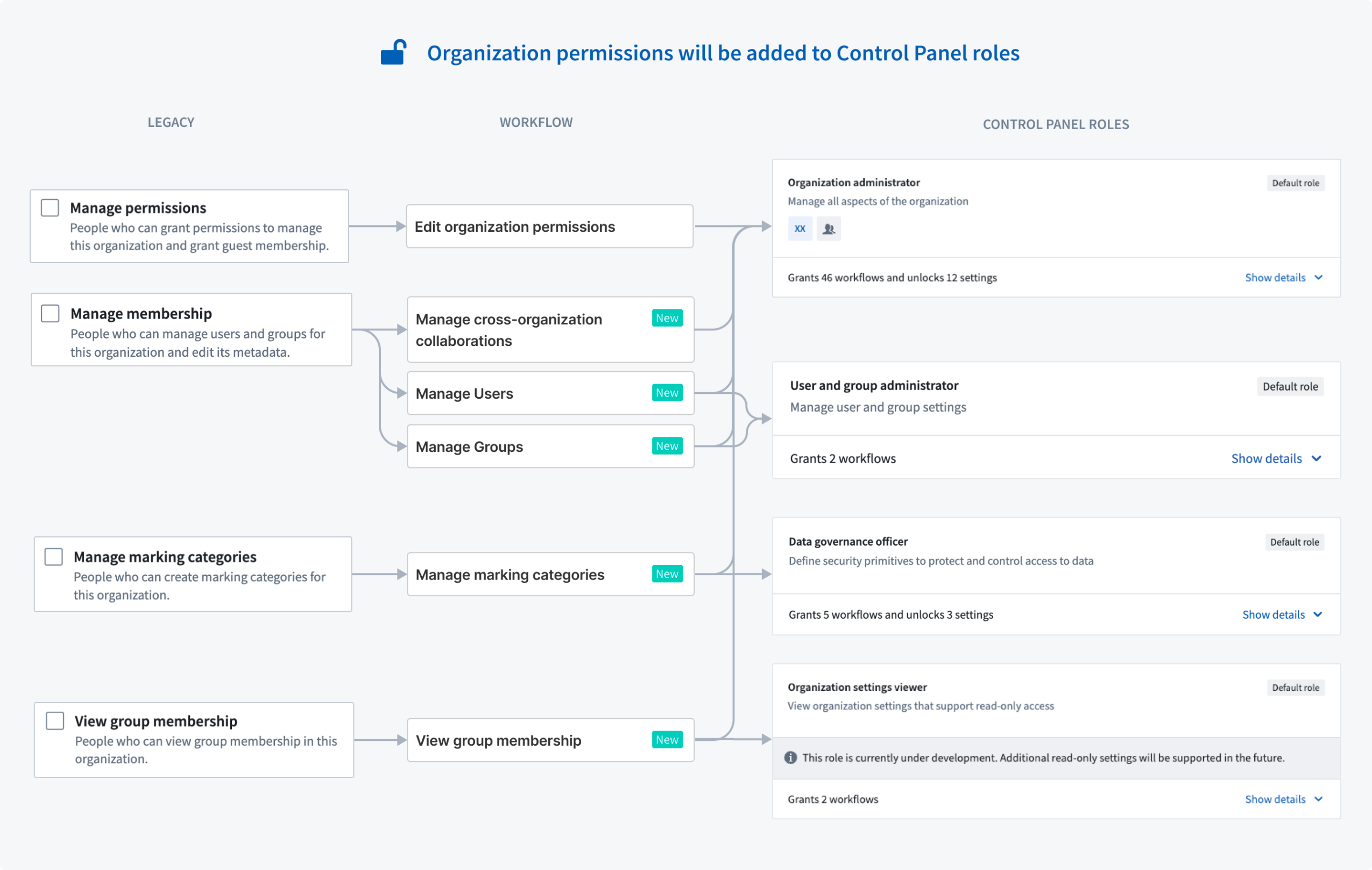
Graphical chart representing role mappings to Control Panel roles in phase 1 changes
Organization administrator acquires Manage permissions and other permissions granted in Platform Settings
Organization administrator acquires Manage permissions, membership, marking categories and control Expand Access/Apply Organization.
Users with the Organization administrator default role will gain the ability to perform workflows previously granted via Platform Settings (Manage permissions, Manage membership, Manage marking categories, and View group membership). The change maintains our philosophy that Organization administrator is a highly privileged role and should have the ability to manage all aspects of the Organization.
Expand access will remain separate and not be automatically granted to Organization administrators. Organization administrators will however be able to manage the users and groups who have this capability by navigating to Control Panel > Organization Permissions tab.
Organization settings viewer acquires View group membership
Users with the Organization settings viewer default role will gain the ability to View group membership for the Organization. Currently, this Control Panel role grants read-only access to Organization permissions in Control Panel, but more read-only workflows will be added in the coming months.
Data Governance Officer acquires Manage marking categories
Users with the Data governance officer default role will gain the ability to Manage marking categories for the organization.
[NEW] Users and groups administrator default role
A new default role is being added to Control Panel called Users and groups administrator. Users added to this role will gain the ability to Manage membership for the Organization.
[NEW] Organization Marking permissions tab
A new Marking Permissions tab will be added to the Organization Permissions section in Control Panel. This is a one-to-one replacement for the Apply Organization and Expand access sections in Platform Settings.
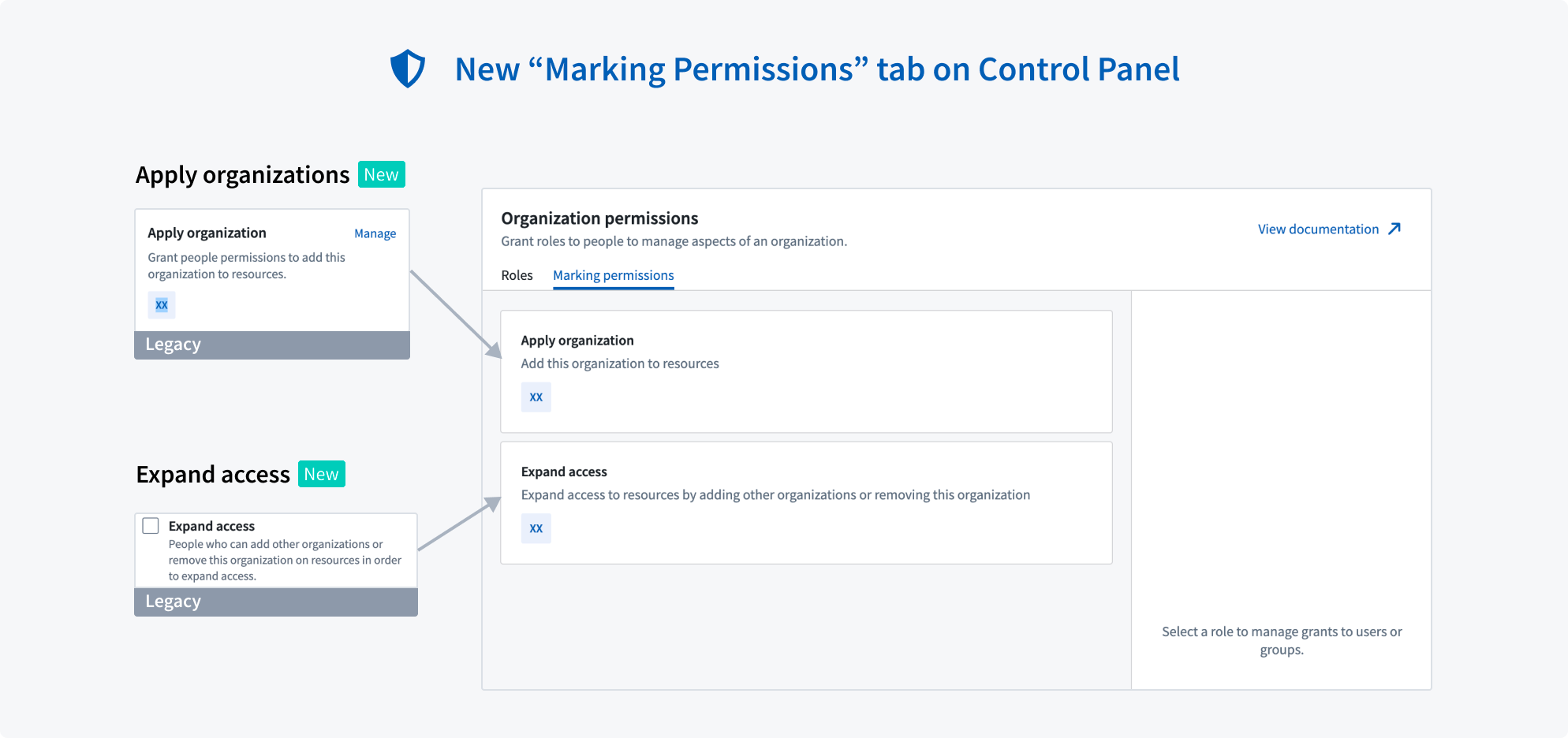
New Marking permissions tab on Control Panel for Organization administrators to review Organization permissions and existing permissions
Phase 2 changes (Scheduled for Q1 2024)
In Phase 2, existing permission grants will be automatically migrated over to Control Panel roles and the interface on Platform Settings will be fully deprecated and removed. Additional communication about phase 2 details will be provided once phase 1 is underway. At the start of Phase 1, we encourage administrators to:
- No longer rely on Platform Settings to manage these permissions, but to instead grant them through the appropriate Control Panel role; and,
- Manually audit and move over existing permission grants in Platform Settings to target Control Panel roles.
For more information on how permissions and its primitives work in Foundry, review the documentation on Enrollments and Organizations in Foundry.
Ontology SDK for Python [GA]
Date published: 2023-11-02
The Python language version of the Ontology SDK is now generally available. Developers can use Developer Console to generate a Python package with object types, link types, and action types from their Ontology, and install the package using either Conda or pip.
The Ontology SDK can be used to load data, perform aggregations, and apply actions. The following is a code snippet example:

Where can I learn about the Python Ontology SDK?
The Python Ontology SDK is generated using Developer Console. Refer to the Ontology SDK documentation for more details, or follow our walkthrough on how to use the Python SDK with Jupyter notebook.
Developer Console also includes dynamic documentation customized to the content of your application. In-platform API documentation is also available for TypeScript and cURL.
Developer Console includes documentation for each object type included in the SDK
How can I try this out?
Open Developer Console from your Foundry workspace navigation bar and create an application or open one you have already created. On the Application SDK page, you will find a list of all the generated versions of the SDK. Start by selecting Getting started docs located on the top right.
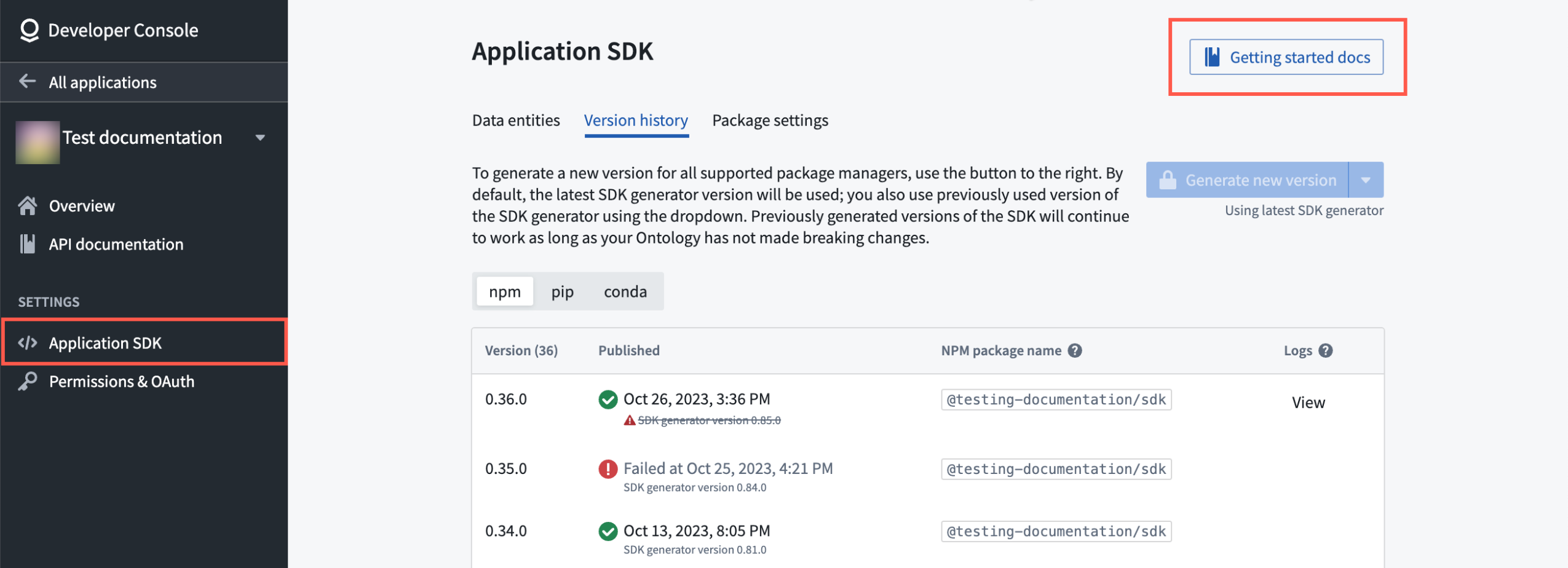
Developer Console includes documentation for each object type included in the SDK
Access the Application SDK from under the Settings menu of the Developer Console navigation bar and begin with Getting started docs
For more information, review Ontology SDK documentation.
Objects Monitoring becomes Automate [GA]
Date published: 2023-11-02
Automate, generally available the week of November 20th, is the new, fully backwards-compatible product that replaces Objects Monitoring to become the single entry point for all business automation in Foundry. All existing object monitors will automatically be migrated to the new application and continue to function without change.
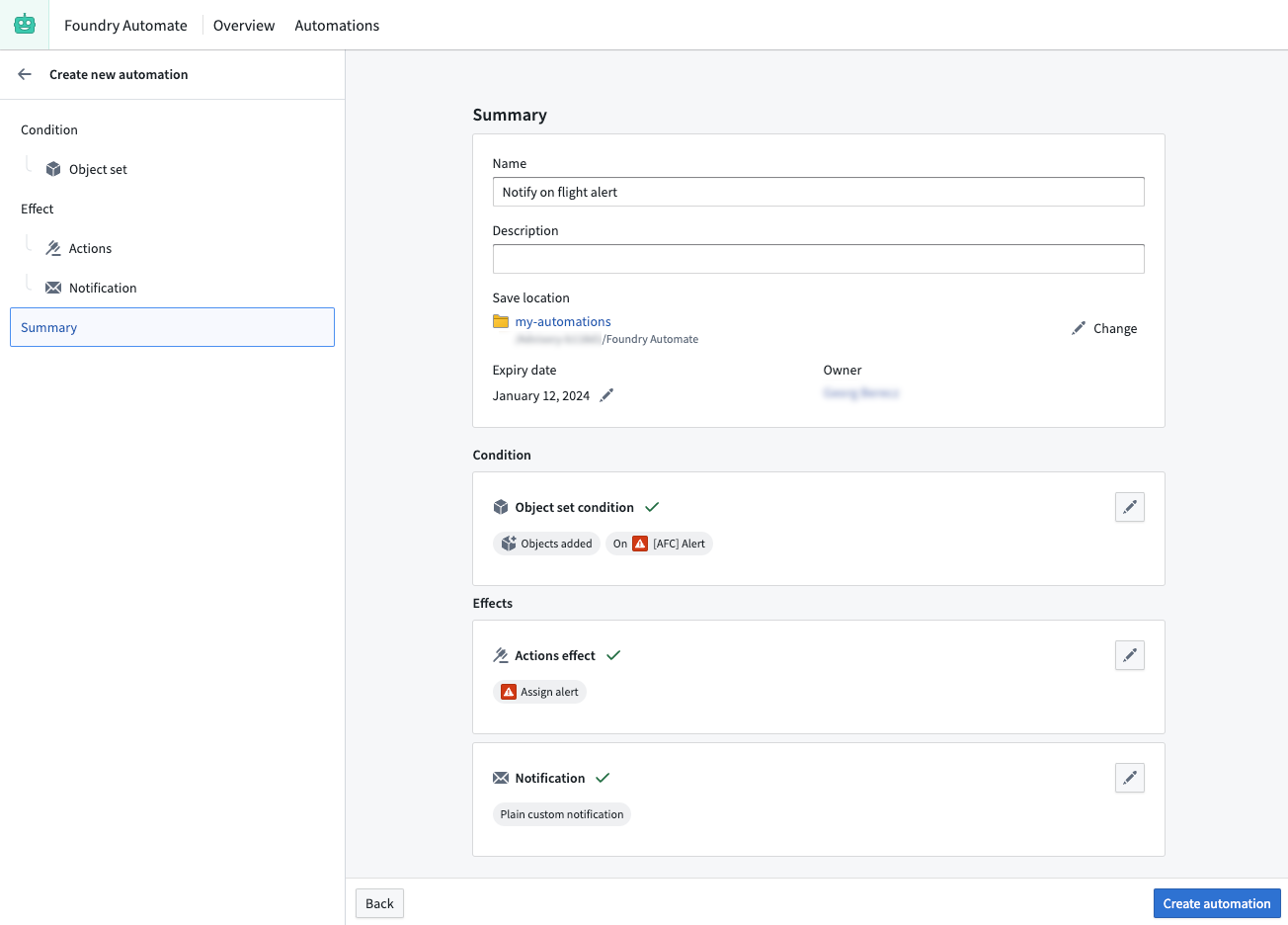
Automate's summary page at a glance
Automate allows users to newly set time conditions in addition to object conditions, and link them to actions or notifications that automatically execute when conditions are met. With many improvements and extensions over Object Monitoring, Automate offers a fully redesigned user interface for creating automations, more options to configure conditions and effects, and native integrations with other applications in the platform.
New conditions and effects for robust configuration
In addition to Automate's ability to create automations that never expire, you can now configure a variety of new conditions, effects, and native integrations to provide you more automation flexibility.
Conditions
- Time condition: Configure a schedule and execute effects at a pre-defined time (For example, "every Monday at 9 AM").
- Object set conditions
- Objects modified condition: Trigger effects when any or specific properties of objects change
- Allow specifying the monitored object set inline (no saved Hubble exploration required anymore)
- New execution modes (in addition to the existing batched mode)
- Per-object execution: Allow triggering effects for each object that triggered the automation separately
- Per-group execution: Allow triggering effects for a pre-defined group
- Live Patch support: Object sets that can be live-monitored now immediately pick up changes coming from Actions
- Combined time and object set condition: Check an object set condition at a pre-defined time (For example, "every Monday at 9 AM and for any new alerts objects".)
Effects
- Notifications
- Property-backed recipients: Use object properties to dynamically set recipients for a notification effect
- Attachments: Select Notepads or Notepad templates to automatically attach as PDF to email notifications
- Notepad
- Notepad templates
- Support for passing affected objects from the object condition
- Function-backed notifications
- Support for passing single affected object, object reference, object list, and object set parameters
- Actions
- Support for providing dynamic object set definitions as object set parameter
Native integrations
- Native Notepad integration
- Set up an automation directly from Notepad without switching to Automate
- Native Ontology Management Application (OMA) integration
- Set up automation from OMA and view all automations that are associated with a specific object type or Action type
What's on the development roadmap?
We plan on extending Automate's capabilities and embedding it even further with other Foundry applications, with a highlight on improving:
- Support for streaming object types
- Infrastructure improvements to raise execution limits
- Native integration with Machinery
- Native integration with Foundry Logic
For more information, review the Automate documentation or learn how to Get started with Automate.
Additional highlights
Data Integration | Code Repositories
Date published: 2023-11-30
New Repository Guidance | Foundry now provides helpful suggestions for files to edit when creating a new repository in Code Repositories. This feature aims to streamline the process of setting up a new repository by recommending relevant files to modify.
Foundry Developer Console
Date published: 2023-11-30
Enhanced SDK Generator Selection | Users can now choose from all available generator versions for each package manager, providing more flexibility and control over SDK generation. A new dialog has been introduced for selecting generator versions and specifying which packages to generate, improving the overall user experience.
Administration | Control Panel
Date published: 2023-11-30
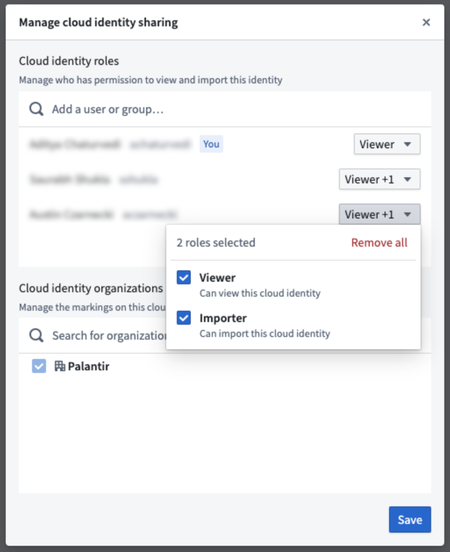
Cloud Identities Extension Now Generally Available | The Cloud Identities extension in Control Panel is now generally available. Cloud identities allow you to authenticate to cloud provider resources without the use of static credentials.
Administration | Control Panel
Date published: 2023-11-30
Custom Base Layers Support in Workshop Map Widget and Foundry Maps | This update enables custom base layers in the Workshop Map Widget and Foundry Maps, providing users with more flexibility in map visualization. The "enable mapbox base layer" toggle in the Map section of the Control Panel now applies to all maps, and when disabled, maps will use the first custom base layer configured. Additionally, Workshop now offers a "custom" base style option.
Analytics | Quiver
Date published: 2023-11-30
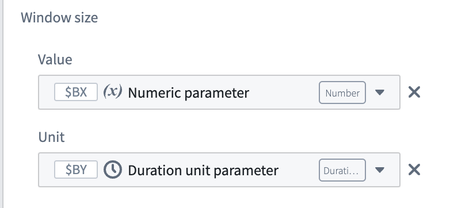
Enhanced Time Series Transforms | Quiver now offers improved time series transforms with parameterizable inputs, units support, unit override, and unit conversion. These features apply to time series transforms used both natively and in the transform table, providing a more flexible and efficient user experience.
Ontology | Ontology Management
Date published: 2023-11-30
Enhanced object storage filter for Ontology cleanup | The Ontology Manager application now includes an improved object storage filter to streamline the ontology cleanup process. Users can more efficiently identify and remove unnecessary objects, resulting in a cleaner and more organized ontology.
Administration | Control Panel
Date published: 2023-11-30
Cloud Identity Permissions Management | Introducing a new permissions manager for cloud identities in the Control Panel, allowing users to easily manage access and permissions for their cloud resources.
App Building | Slate
Date published: 2023-11-28
Improved widget navigation in Slate | Users can now easily navigate to widgets on a long canvas in Slate by selecting the widget in the widget list. The canvas will automatically scroll to the selected widget, providing a more efficient and user-friendly experience.
App Building | Slate
Date published: 2023-11-28
Full-width editor panels now available | The Slate application now features full-width editor panels, enabled by default on all stacks. This update provides users with a more spacious and comfortable editing experience.
Data Integration | Code Repositories
Date published: 2023-11-28
Enhanced dataset preview for local development | Users can now preview datasets with files during local development, providing a more efficient way to test and validate their work. This update includes improved file preview capabilities and supports multiple input and output files.
App Building | Slate
Date published: 2023-11-28
Cross-window messaging in Slate | Slate now supports cross-window messaging, allowing users to send and receive messages between browser windows using the slate.sendMessage action and slate.getMessage event. This feature provides a more flexible and generic way to communicate between windows.
Data Integration | Code Repositories
Date published: 2023-11-28
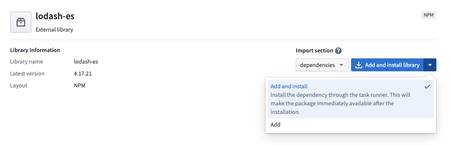
Installing TypeScript Packages via Task Runner | Installation through the Task Runner is now enabled for TypeScript Functions repositories with functions-typescript template versions of at least 0.523.0.
To use this feature, search for a package using the Libraries tab of your code repository. After selecting a package, the new Add and install library option can be selected to automatically install the package using the task runner. This will automatically update both the package.json and package-lock.json files in your repository.
For more information, read the documentation.
Artifact Repositories
Date published: 2023-11-28
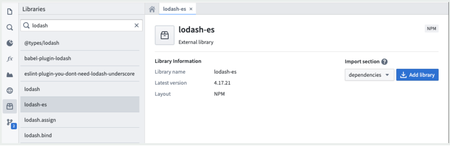
Enhanced npm package search and installation | The search and installation workflow for npm packages in TypeScript Functions for Code Repositories now benefits from enhanced functionality. Previously, the only place to find npm packages was in the external public registry. Now, an enhanced Typescript developer experience allows users to search for any published npm package from Artifacts Repositories or directly from https://npmjs.com within their Typescript Functions Code Repositories, and subsequently import them to their Code Repositories. Additionally, users can now publish their custom typescript packages directly to Artifacts Repositories, enabling developers to import any library's functionality directly to Foundry! To learn more, read the documentation.
App Building | Workshop
Date published: 2023-11-28
Updated Workshop home page | Workshop now features a newly revamped home page, offering enhanced features that enable users to effortlessly create ready-to-use applications from a variety of templates. Users can conveniently input their own data and choose properties that will be smoothly integrated into the module. The current collection of templates features an inbox, map, and metrics dashboard, with more exciting options coming soon!
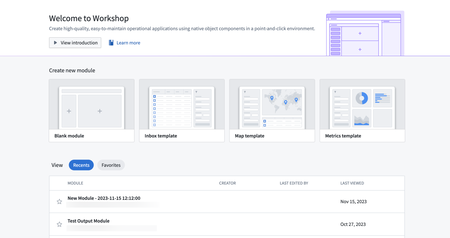
Ontology | Vertex
Date published: 2023-11-28
Improved large graph performance in Vertex | Users will experience a significant performance improvement when drag-selecting on large graphs with approximately 1000 nodes in the Vertex application. This enhancement provides a smoother and more responsive experience for users working with large datasets.
Ontology | Ontology Management
Date published: 2023-11-28
Enhanced safety for deleting edits in Ontology Manager | The Ontology Manager now provides additional safeguards by preventing users from deleting all edits on an Object type with an "Active" status in Object Storage V2. This ensures data integrity and reduces the risk of accidental data loss.
Analytics | Contour
Date published: 2023-11-28
Board collapse | Visualization boards can now be collapsed to free up path space and improve performance for large paths. To collapse a board, select the Hide board contents option in the top right of the board. All transforms that the board applies to the path will be kept but any visualizations will be hidden.

Security | Projects
Date published: 2023-11-28
Enhanced security for data transformations | We have improved the security posture within Foundry's data transformation architecture by implementing an updated job spec restriction policy. This update provides tighter controls for input datasets referenced in code authoring and code workbooks transforms. If a transform is affected by this update, it will fail, and the user will receive a detailed message explaining the root cause. For more information, refer to the documentation on Project references and permissions.
App Building | Workshop
Date published: 2023-11-28
New page templates available | New layout templates for pages are now available in Workshop! On creation of a new page, five new pre-styled layout options will be available for selection including a details, grid, inbox, overview, and settings view. Layout options may be previewed prior to selection by hovering over their respective icons.
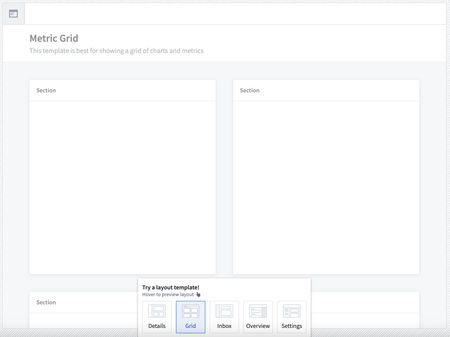
Administration | Resource Management
Date published: 2023-11-15
Business metrics are visible in the overview page of the Resource Management app | Users can now highlight key business metrics, including data scale and average daily users. Metrics can be configured per enrollment or usage account and are visible at the top of the Overview tab or in the Usage accounts tab, respectively.
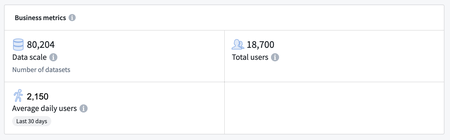
Ontology | Ontology Management
Date published: 2023-11-13
Enhanced Resource Selection in Actions | Action parameter configurations now support a Foundry Resource Selector display option for String type parameters, allowing users to easily select resources within their workflows. This makes it much simpler to build workflows that use both objects and resources in creative ways.
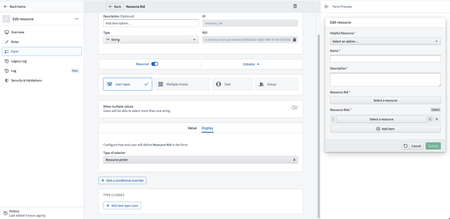
Ontology | Ontology Management
Date published: 2023-11-13
Restriction on Primary Key Changes for Object Storage V2 | Ontology Management now restricts users from changing the primary key of an OSv2-backed object type that has received edits, as this is not supported in Object Storage V2. This change ensures data consistency and prevents potential issues.
Ontology | Ontology Management
Date published: 2023-11-13
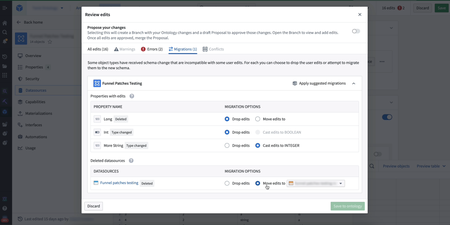
Enhanced Schema Migrations Interface in Ontology Manager | The Ontology Manager application now features a redesigned schema migrations UI when making breaking schema changes in OSV2. Users can easily apply a set of suggested migrations, streamlining the process and improving the user experience.
Foundry Developer Console
Date published: 2023-11-13
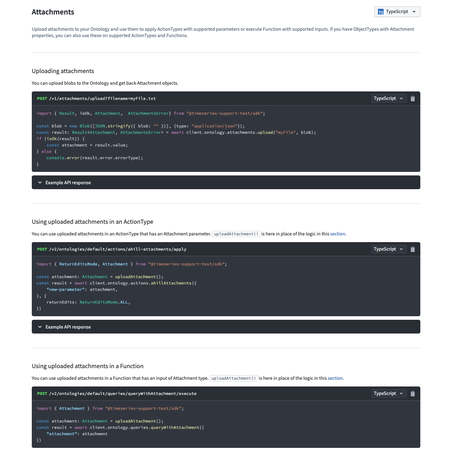
Include Attachments documentation in developer console | When generating documentation for the Typescript OSDK, there is now a section on working with Attachments if the relevant ontology object types, actions, and functions include any attachment properties.
Foundry Developer Console
Date published: 2023-11-13
Enhanced Developer Console Function Selection | The Developer Console now allows the selection of Functions with unsupported inputs/outputs, providing a more flexible experience. Unsupported types are documented, and failures are surfaced in the CLI logs.
Model Integration | Modeling
Date published: 2023-11-13
Model Inference History for Live Deployments | The Model Inference History is a dataset in Foundry that captures all inference requests (inputs) and inference results (outputs) sent to a Modeling Live Deployment. This feature enhances the user experience by providing a comprehensive record of all inferences made, allowing for better tracking and analysis of model performance.
Data Integration | Code Repositories
Date published: 2023-11-13
Improved Telemetry Service Stability | The Foundry Telemetry Service has been optimized, resulting in a significant decrease in QoS and Transaction Conflict exceptions. Users can expect a more stable and reliable experience with a 91% reduction in these exceptions.
App Building | Slate
Date published: 2023-11-13
Strict Mode Enabled in Slate | Slate now operates in "strict mode ↗" as all scripts run as ES6 modules, ensuring better code quality and error handling. This update may affect variable naming, as JavaScript keywords are now strictly reserved.
App Building | Slate
Date published: 2023-11-13
Enhanced Cross-Window Messaging in Slate | Slate now supports more flexible cross-window messaging. This new feature allows users to send messages between different browser windows, providing a more integrated and seamless user experience. This implementation is highly versatile, essentially serving as a wrapper around the window.postMessage function and a listener for incoming events. Users can now use the slate.sendMessage action to specify their messages and post anything they want and selectively trigger specific Slate actions when a message is received.
Ontology Management | Ontology
Date published: 2023-11-13
Pipeline Origin Indication for Object Types | Object types created in Pipeline Builder now display a banner indicating the pipeline they were created in, even when editing is enabled in Ontology Manager. The banner also shows whether editing in Ontology Manager has been enabled. For object types created in Pipeline Builder that are not targeting building a dataset but are populating the object type directly, the Pipeline Builder pipeline will be displayed instead of a backing dataset.
Data Integration | Pipeline Builder
Date published: 2023-11-08
Enhanced Ontology integration in Pipeline Builder | Pipeline Builder now supports Ontology output types, ensuring seamless integration with downstream production applications. Users can now add an object type or a link type output directly within Pipeline Builder, eliminating the need to link a dataset output to an object in Ontology Manager.


Data Integration | Code Repositories
Date published: 2023-11-08
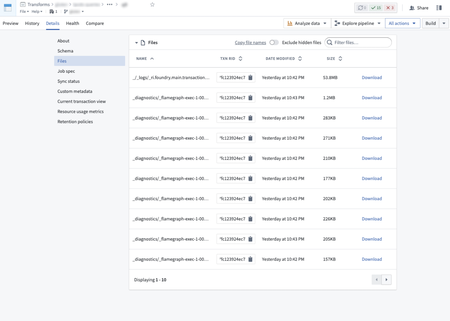
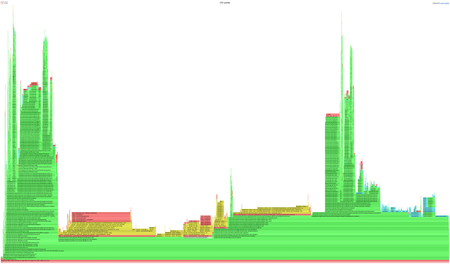
Enhanced executor profiling for debug jobs | Improved the profiling of executor-side performance for debug jobs with periodic executor profiling. By default, executors are profiled every 5 minutes for one minute, providing better visibility to identify and address performance regressions. You can download HTML files containing flame graphs for each executor and profiling interval from the files view in the output dataset's Details tab.
Model Integration | Modeling
Date published: 2023-11-08
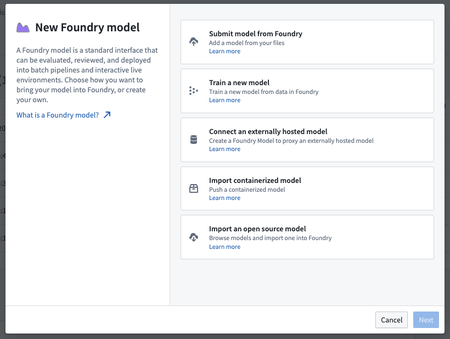
Enhanced model creation experience | The Model Assets creation process has been significantly improved, offering a variety of guided options for creating different model types. Additionally, the model submission dialog in the Modeling Objectives application now supports more source types and direct sandbox deployment for immediate testing of new model submissions.
Foundry Developer Console
Date published: 2023-11-08
Developer Console: Update groupby syntax | The Foundry Developer Console now uses the group_by syntax instead of groupby for improved consistency and readability.
Data Integration | Pipeline Builder
Date published: 2023-11-08
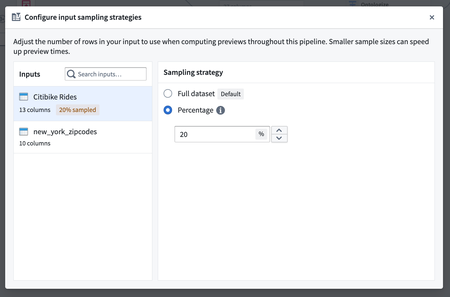
Enhanced preview speed with input sampling | Pipeline Builder now supports input sampling, allowing users to choose a percentage of their input data for faster previews. This feature significantly increases preview speed while maintaining full input computation upon building.
Data Integration | Pipeline Builder
Date published: 2023-11-08
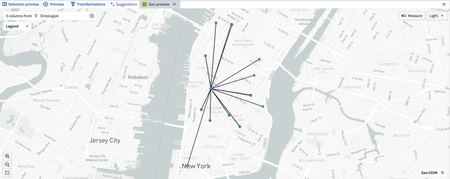
Enhanced geospatial data preview in Pipeline Builder | Users can now preview geospatial transformations on a map directly within Pipeline Builder using the geospatial preview board in the bottom left panel. To use this feature, select a series of geospatial datapoints in your preview table, then right-click and choose Open geo preview.
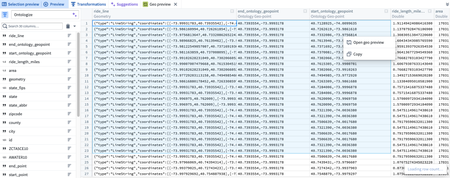
Foundry Developer Console
Date published: 2023-11-06
Opt-in to SDK Beta Features | Users can now opt-in to beta SDK features in the Foundry Developer Console. This allows users to test and experiment with new features, such as Time Series properties, before they are rolled out to everyone. To enable beta features, simply toggle the "Enable Beta Features" option in the package settings.
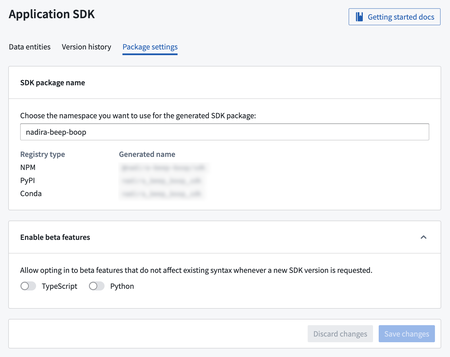
Analytics | Notepad
Date published: 2023-11-06
Conditional selection in Notepad templates | Conditional selection enables users to selectively include content in a generated document based on the value of a string template input. Configure a rule with an "if" section to set the condition, and a "then" section to determine the consequence, opting to either hide or show the contents of the conditional section.
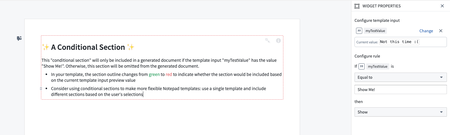
Data Integration | Pipeline Builder
Date published: 2023-11-02
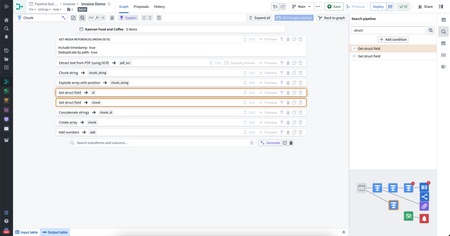
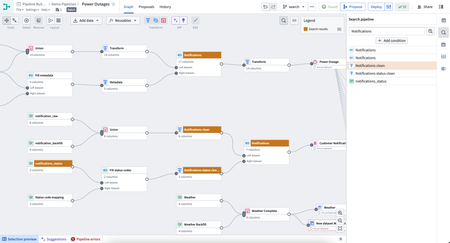
Pipeline Builder search panel | The search panel has been updated to provide a more user-friendly experience while searching the pipeline graph and transform paths. New features include more explicit tooltips and labels, the ability to use Enter and Shift + Enter to navigate between results, and the option to open the search panel via Ctrl + F (Windows) / cmd + f (MacOS).
Users can combine multiple conditions, and each condition can be toggled to search node name, description/text boards, column references, schema or property names, transform names, and parameter references.
Data Integration | Pipeline Builder
Date published: 2023-11-02
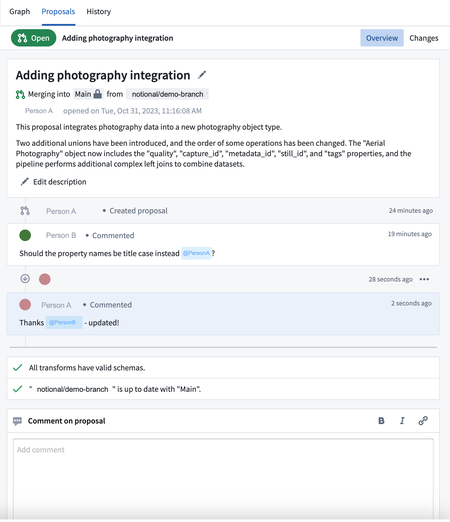
Pipeline Builder proposals now support comments | Comments can now be added to proposals to help facilitate discussion among users about the proposed changes.
Analytics | Quiver
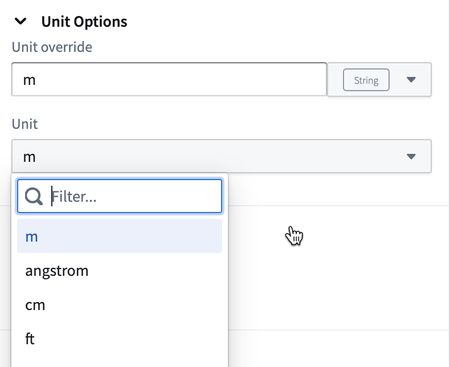
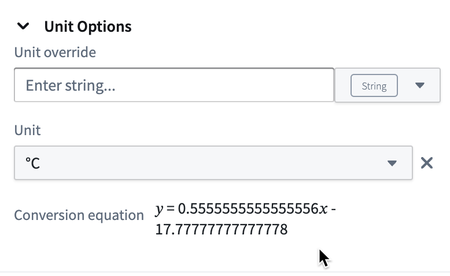
Date published: 2023-11-02
Time series unit overrides and conversions | Users can now manually override the unit of a time series using a transform table column or a string provider. When used together with the Time series unit transform, users can propagate the unit of one time series to multiple time series.
Additionally, users can now convert the values of a series data using available unit conversions. The available unit conversions are dependent on the base unit of the series, or the override unit if specified.