- Capabilities
- Getting started
- Architecture center
- Platform updates
Announcements
Pipeline Builder: Features for rapid development
Date published: 2023-04-28
Earlier this year we announced Pipeline Builder ↗ as the next-generation approach to fast, flexible, and scalable data transformation. Since then, we've been hard at work to deliver powerful new features based on user feedback. Pipeline Builder has also added over 70 new transforms in the past 3 months, including Geometry functions, improved timestamp parsing, and complex join conditions. Continue reading to learn about some new Builder features you might have missed!
Custom functions centralize reusable logic
Re-use shared logic throughout a pipeline without copy/pasting. Select one or more boards and covert them into a custom transform with defined arguments, then re-use it as needed. Update the logic once and have it applied everywhere the function is used in the pipeline. Updated documentation coming soon!
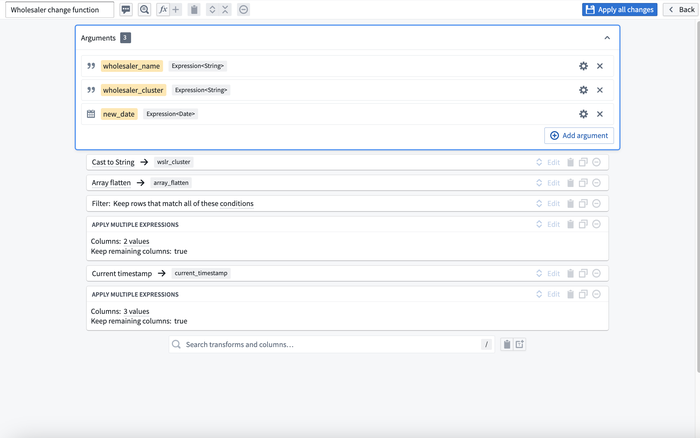
For-loop-style functions shortcut repeated logic
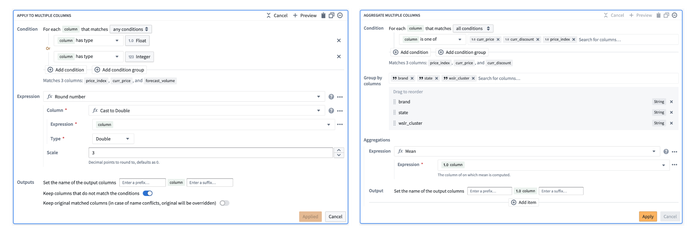
Continuing the theme of reducing duplicative logic, Pipeline Builder now supports wrapping up set of operations or aggregations and applying them dynamically across multiple columns. This flexibility massively reduces the need for tedious, duplicative configuration for standard data cleaning and normalization logic and, when combined with the reusable functions described above, makes Pipeline Builder a fast, efficient, and maintainable tool for managing the often repetitive logic associated with preparing raw data for analysis and operations use.
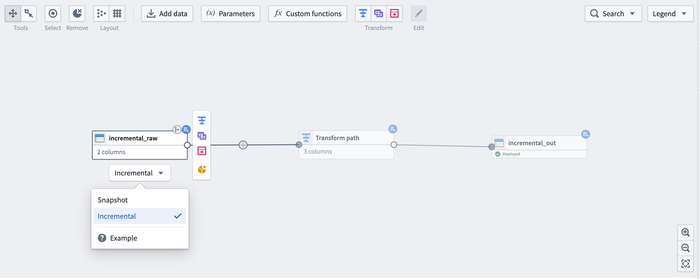
Support incremental logic for faster, cheaper data pipelines
Incremental pipelines are the faster, cheaper, and more elegant solution when data transformations are only needed on top of the newest available data. However, managing the logic and complexity of these pipelines in code has been a barrier to reaping these benefits. Now, you can configure a pipeline as incremental in a single click in Pipeline Builder. In-app guidance clearly lays out the core concepts, and no additional configuration is required. Many of the previous challenges are addressed: Pipeline Builder will limit the logical transforms to only those applicable to incremental pipelines, as well as detect breaking changes and prompt the user to replay or revise their logic, eliminating surprise snapshots. These additions increase the accessibility of this powerful set of features. For more information, see an example of incremental computation in Pipeline Builder.
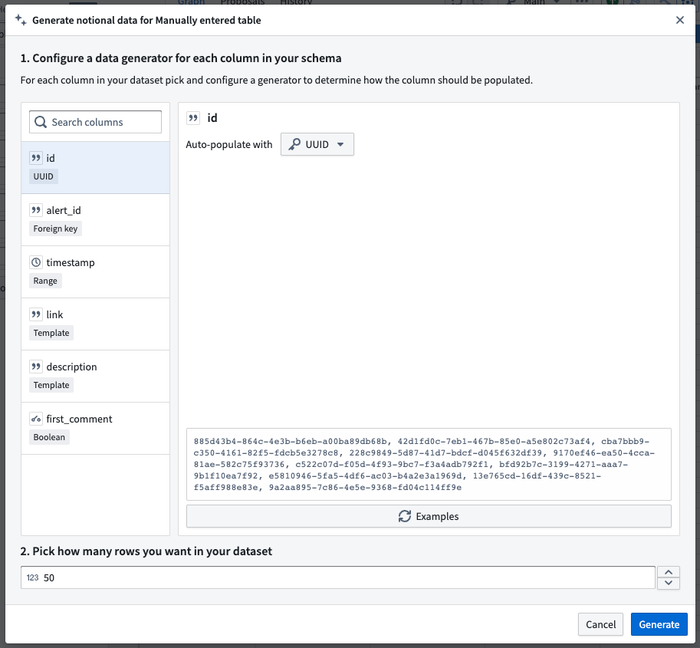
Start building fast with notional data in manual entry tables
It can take weeks or months to get the data required to start a pipeline. And even once the pipeline is built, ad-hoc changes may come in at any point. The pipeline development process needs to be flexible to account for your updated business requirements at any time. Now, you can add manual entry tables and flexibly generate notional data as temporary inputs to batch pipelines. Once production data is available, simply switch out the node with in the pipeline with a single click. Level up and use the notional data and associated pipeline to back a v0 of an ontology with multiple object types, and you can rapidly prototype operational applications and iterate on the schemas and data model without blocking on data access.
Object Monitors: Subscribe users and groups
Date Published: 2023-04-24
Object monitors run on top of your data and are designed to help users track individual searches and objects. Object monitors also serve as a tool for application builders to include monitoring and alerting functionality as part of applications built in Foundry.
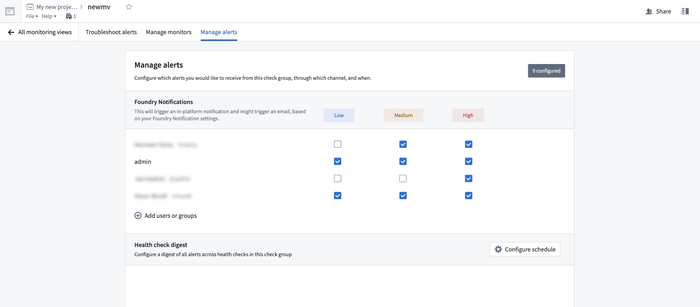
When users set up health checks and monitors, they’re not always the only ones who care about getting alerted on failures. Especially in larger organizations where there is a support rotation or team dedicated to specific workflows. Now, builders configuring an operational don’t have to manually ask users to manually subscribe to alerts. Instead, individual users as well as groups can be added to an alert. This opens up a wealth of operational workflow possibilities, including the long-awaited ability to configure a shared inbox application and subscribe a group to receive alerts when a new object enters the object set populating the inbox.
Note that a user who doesn’t have access to the resource will still not see alerts even if a permissioned user subscribes them.
Configuration
In the manage subscriptions tab, you can add users and users groups and configure the level of criticality of alerts they can subscribe to. Depending on their Notifcations settings users will receive in-platform notifications as well as email notifications when a monitor triggers. Coming soon notifications will support a direct PagerDuty integration.
Workshop: Save and attach Maps and Graphs
Date Published: 2023-04-24
In the Vertex Workshop Widget, after generating a Graph from a template, a user can now save this graph directly from Workshop, without having to open up the full Vertex application. Likewise, using the Map application template widget, you can save a map generated from a template directly from Workshop.
In the widget configuration, the new resource identifier (RID) of the saved resource is captured as a string variable and can be added as a parameter to an Action configured to run whenever the user saves a new map or graph. With this pattern, you can represent maps and graphs within the ontology by saving the RID as a property and then show it to users of the application by using the new Override resource RID configuration in the Vertex and Map widgets in Workshop.
This general pattern of:
- Configure a template resource
- Configure a Workshop app where the workflow prompts users to duplicate the template, embeds the resulting resource in a widget, and allows the user to make modifications
- Capture the RID of the new resource as a property of an object type with an Action
fits into many operational workflows that involve a standard process. In addition to Vertex graphs and Map templates, Notepad templates work well for this pattern when users need to duplicate and then fill out a standard document. These features are available under the "Saving" heading of the "Capabilities" section of each widgets configuration. For more details, see the Vertex documentation and the Map application documentation respectively.
Quiver: More easily find and analyze data
Date published: 2023-04-18
Quiver is a powerful data analysis, reporting, and dashboard building application with a rich set of tools and capabilities. To make it more intuitive for experienced and new Foundry users alike, we are excited to announce a set of user interface changes that simplifies searching for data, improves the discoverability of interactions like transformations, joins, filters, and visualizations, and clarifies data type changes resulting from data transformations.
Next Actions menu improvements
We've reorganized the Next Actions menu - which now shows up when hovering over a card or time series plot - to make it easier to find what you're looking for. The new categories are grouped by what each card does rather than by its data type. All cards to interact with data are now accessible from the Next Actions menu or using the Search cards button at the top bar. Also, the Next Action bar is now searchable! Search for actions across all categories or within a specific category. Results will include matches from within the category and also highlight matches from other categories, so you don’t miss out any actions!

Transforming data is more intuitive
We’ve added a new category to the Next Action menu: the Transform category. This new category contains all the transformations applicable to Transform Tables that were previously only accessible after having added a Transform Table card to the Canvas or Graph. Adding a transformation from this category will automatically add a Transform Table and apply the selected transform, streamlining the analysis workflow.
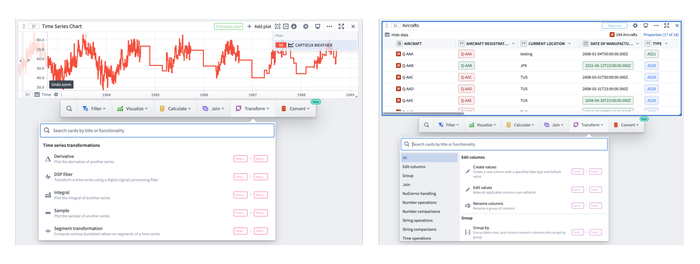
Streamlined top bar menu focuses on adding data
We've simplified the analysis menu, with an emphasis on adding data. You can still search over all available cards using the Search cards button. This redesign also consolidates the experience of adding data across Quiver, so there's a familiar and consistent experience every time you bring data into your analysis.

Clarified representation of data type changes between cards
While the inputs for an analysis comes from Objects and Timeseries data, Quiver's powerful transformation cards allow you to manipulate and derive data of all types. To improve legibility while configuring an analysis, all cards now clearly show the data type they interact with in full name without abbreviations. This makes it clear when a card operation changes the data type and, as a result, the available actions on the output card. In addition, when choosing cards in the Next Action or Search selectors, the input and output types are displayed alongside the card name and description.

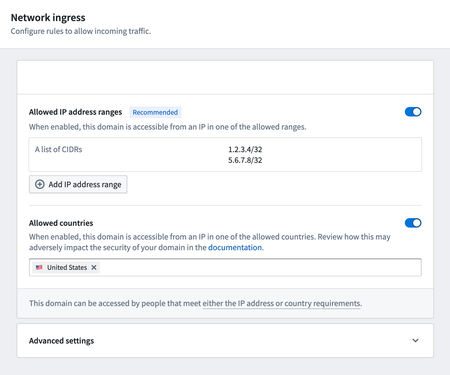
Control Panel: Configure network ingress
The ability to configure network ingress allowlists [1] is now available in the Network ingress tab of Control Panel, unblocking self-service configuration by Foundry administrators. Previously these allowlist configurations were managed in collaboration with a Palantir engineer; moving the configuration into Control Panel increases transparency and allows accounts with the Information Security Officer or Enrollment Administrator role manage the allowlist independent of Palantir support. The existing allowlist configuration has been automatically migrated for most Foundry enrollments.
If you have questions about this new capability, reach out to Palantir Support.
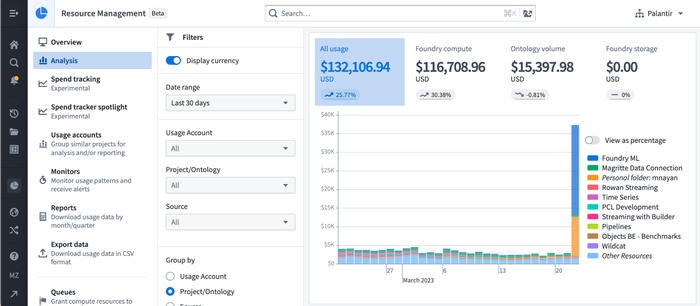
Resource Management: Currency
Date published: 2023-04-14
The Resource Management app app now displays resource usage across the platform as a currency value by default. This means that usage will be displayed as a local currency rather than technical dimensions, like GB-months or cpu-seconds. This simplifies the comparison of relative spend between different technical dimensions of the platform and makes it more intuitive to understand how resource usage translates into real-world cost.
Note that access to the Resource Management application is controlled with the Resource management viewer role, which can be managed in the Control Panel > Enrollment Permissions configuration. Currency-based views of resource usage may not be available to all Foundry enrollments - if you have any questions, contact a Palantir representative.
Slate: Introducing the Slate debugger
Date published: 2023-04-10
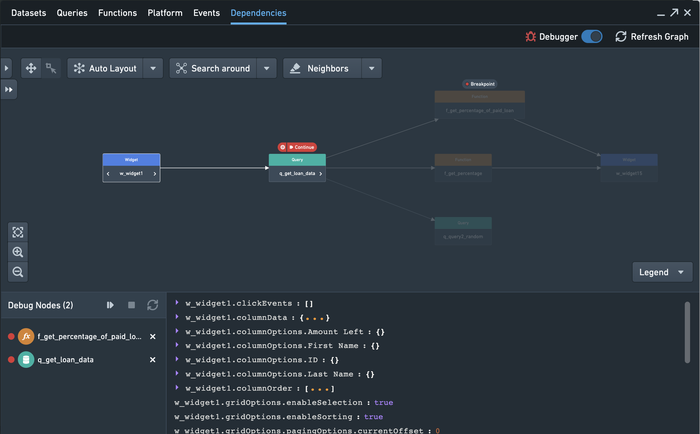
Building ambitious applications in Slate - made up of hundreds of widgets, queries, functions, and events - results in inevitable complexity. In these applications, if some unexpected behavior pops up, it's hard to trace through the web of dependencies and find the root cause in an edge case of a function or a some complex eventing logic.
With the new integrated debugger, the Dependency Graph is now a super-charged tool for investigating the inner workings of even the most complex Slate applications. It's now possible to set breakpoints in the execution of the dependency graph and understand intermediate stages as it resolves.
Read more about breakpoints and the debugger and best practices for investigating Slate apps in the docs.
Modeling Objectives: Model operations 2.0
Date published: 2023-04-04
End-to-end management for AI/ML models
Modeling Objectives is the Palantir Foundry application for managing ML/AI models as they progress through the ModelOps ↗ lifecycle in Foundry. Modeling Objectives has been updated to simplify the experience of managing, evaluating, and releasing models in Foundry to better help teams focus on prototyping, training, and integrating the best models for a problem.
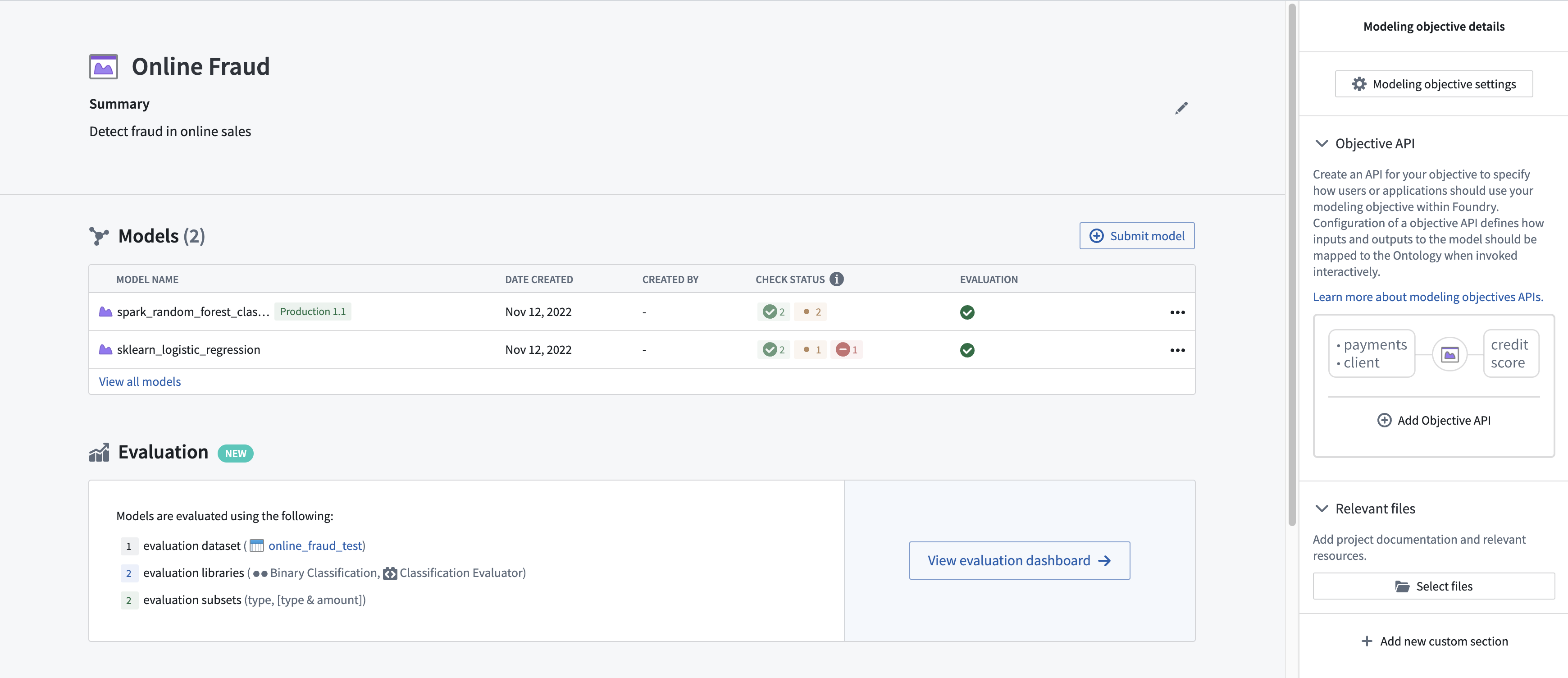
The Modeling Objectives application enables data science and engineering teams to:
- Collaborate on a modeling project
- Define and automate model evaluation pipelines
- Submit and track all candidate models, their performance metrics, and model reviews
- Easily deploy models into live interactive or batch deployment environments with first-class change control for model upgrades
No-code model evaluation or low-code evaluation libraries
The Modeling Objectives application can now be configured to automatically produce and build inference and metric pipelines for all model submissions without code. This is enabled using default evaluation libraries for common modeling problems including regression and binary classification.
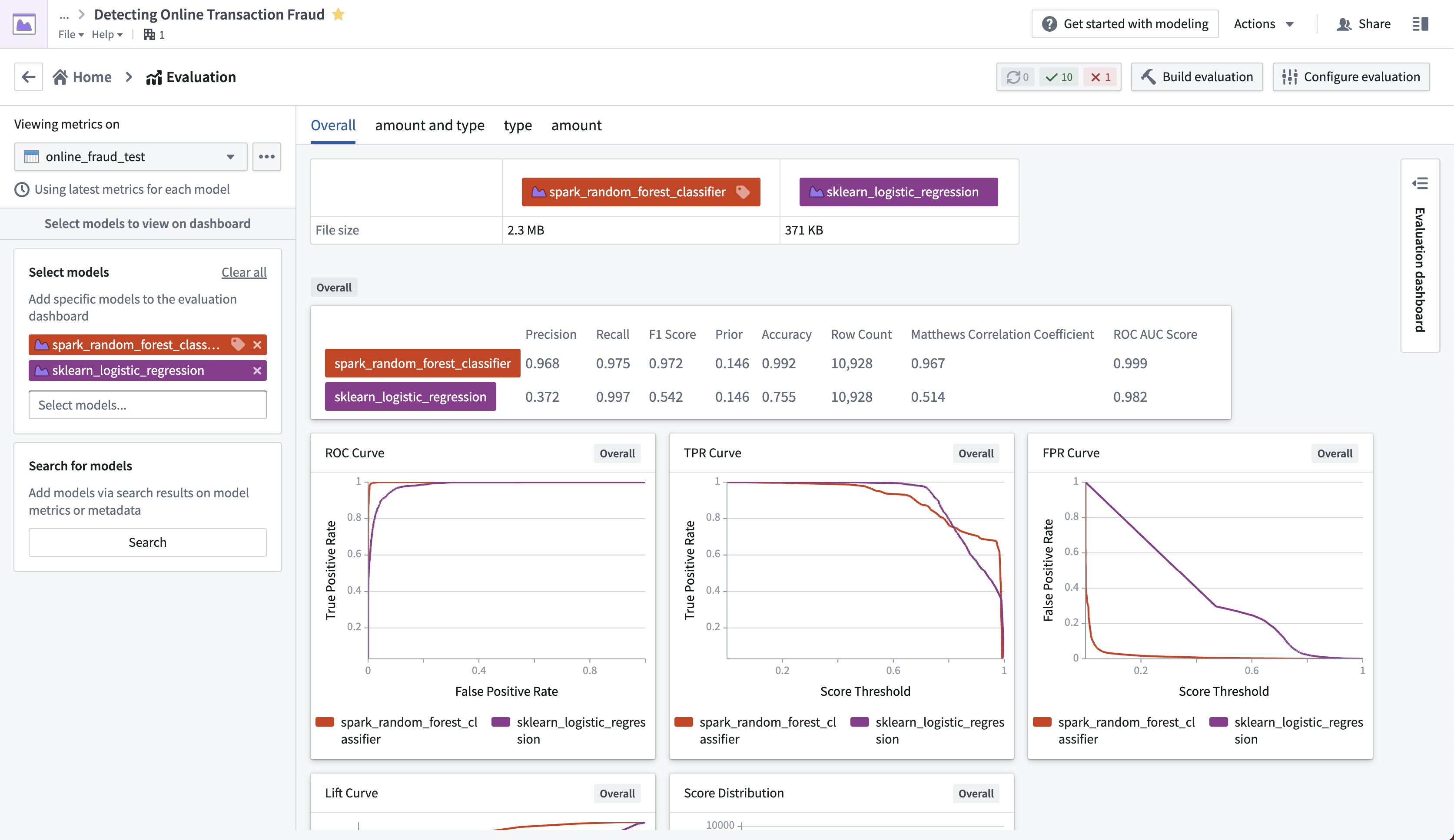
These libraries enable teams to define systematic model evaluation structures to ensure all models are evaluated and compared consistently, leading to accurate model comparisons and improved real-world results. With the introduction of model evaluation libraries, you can now create reusable and parametrizable evaluation libraries in Foundry. These libraries enable data science teams to leverage automatic model evaluation for other modeling domains or with custom metrics specific to the team, organization, or problem.
Compare granular model performances
Model Evaluation Subsets are being introduced in Modeling Objectives to powerfully extend evaluation metrics by allowing comparison between granular subsets of evaluation data.
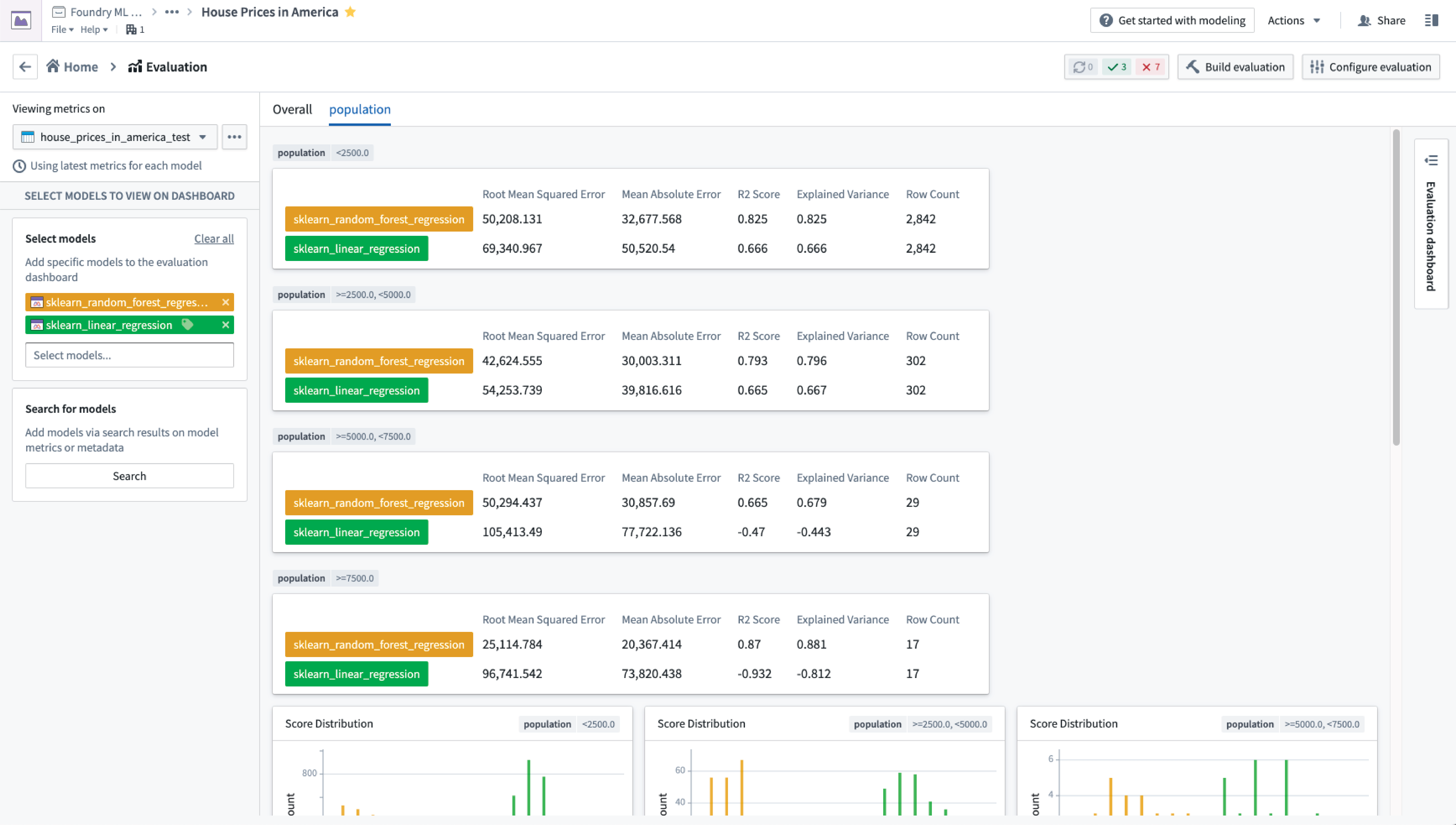
This enables a model developer to:
- Quickly determine where a model is performing poorly and focus development efforts
- Intelligently decide the operational or organizational settings where a model can be used
- Confirm and record that production models behave equitably on different classes of data
- Model Evaluation Subsets amplify model evaluation by providing a unique lens to the performance of models, while requiring no additional code
Modeling Objective Checks
In recognition that not all model testing and evaluation is quantitative, Modeling Objective Checks can now be used to facilitate an integrated review process for your subject-matter experts and allow them to approve or reject the models prior to production.
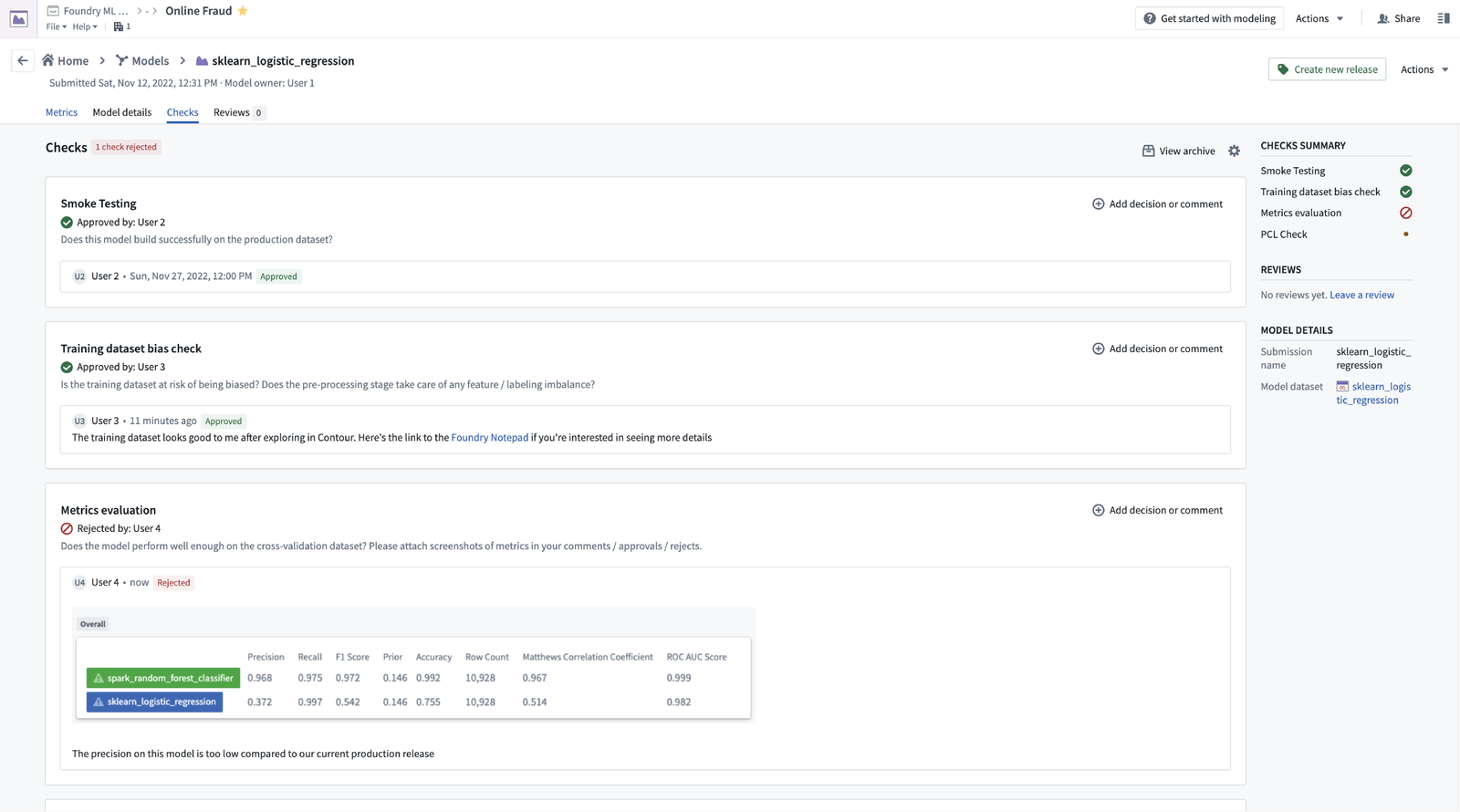
When do I use Modeling Objectives?
Modeling Objectives makes it simple for data scientists, engineers, and their teams to turn ad-hoc model development into a production-ready, governed, and operational workflow.
To set up a modeling objective and learn how to evaluate and compare models consistently against metrics relevant to specific domains and use cases, read the documentation on model integration and review models.
Additional highlights
Administration | Control Panel
Configure Organization-level consent to third party application | By default, before a third-party application can access Foundry data on a user's behalf, the user is prompted to provide consent to the third-party application to do so. An Organization administrator with permissions to manage OAuth 2.0 clients can now provide such consent on behalf of all Organization users. This may be appropriate for architectures in which users are not expected to interact with Foundry directly. Read more about Foundry and third party applications, including how to configure Organization level consent.

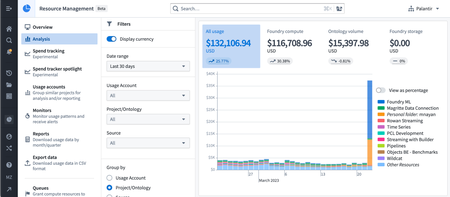
Administration | Resource Management
Release currency to the fleet | The Resource Management app will now default to display resource usage as a currency. This means that usage will be displayed as a currency (USD, GBP, etc.) rather than technical dimensions (GB-months, CPU-seconds, etc.). Displaying usage as a currency makes comparing relative spend between technical dimensions possible. Foundry enrollments can now understand the breakdown of spend across the platform using a familiar common unit - cost.
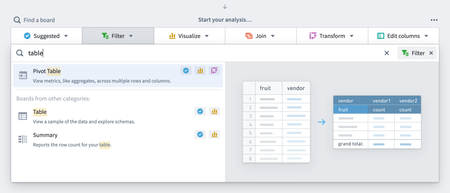
Analytics | Contour
Enable new board ribbon everywhere | Redesigned the board ribbon to make search and discoverability of boards more prominent. Now when opening any category of the board ribbon users can search for boards and discover boards from other categories as well.
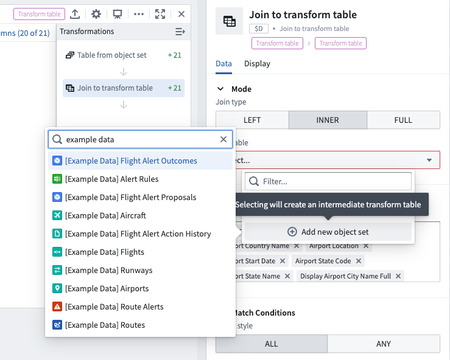
Analytics | Quiver
Improvements for Quiver transform tables | Introducing two improvements to dropdowns for selecting an input transform table: 1. Auto-Conversion: In addition to available transform tables in the analysis, we now also show all entities in the analysis contents that can be converted to transform tables. If any of these are selected, we auto-create a transform table from the selected entity and select that as the input. 2. Object Types: Also added an "Add object set" button that will allow users to inline-select an object type from the ontology to create an object set, and then also auto-create and select a transform table off of it. These changes are meant to help users who get stuck when transform tables are a required config input.
Update to Quiver Next Actions menu | We reorganized the Next Actions menu to make it easier to find cards. All cards that interact with data are now accessible from the Next Actions menu or using the "Search cards" button at the top bar. The new categories are grouped by what each card does rather than by its data type: Filter, Visualize, Calculate, Join, Transform, and Convert.

App Building | Slate
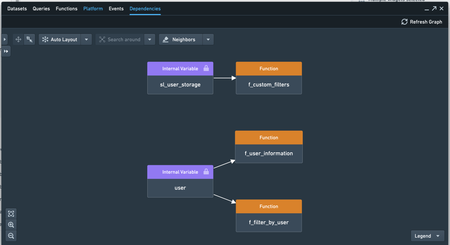
Discover Slate internal variables in the dependency graph | Internal Slate variables such as sl_user_storage and $global are now visible in the dependency graph.
Set custom window titles in Slate | You can now set a custom favicon by calling the slate.setFavicon action.

Add locale global variable | You can now access the language that the user set in their Foundry session by using the $global.locale variable.
Duplicate a Slate app with Viewer permissions | Duplicating Slate applications now only requires Viewer permissions. You can duplicate applications from the Actions dropdown in the top right corner.
Data Integration | Pipeline Builder
Markdown template can be added to proposals and branches settings rearranged | Pipeline owners can now add A markdown template for proposed changes. Once a template is set, each proposal request will include the template in the body field for users to fill out. Proposal templates can be viewed and edited in the new Proposal template tab in the Branches settings view.
Ontology | Foundry Rules
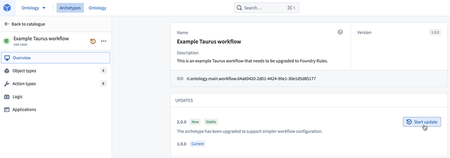
Wizard to assist the upgrade from Taurus to Foundry Rules | The V2 of the Rules archetype centralizes and simplifies configuration, making maintenance and updates to your Foundry Rules setup safer and quicker. This update introduces an upgrade assistant for migrating a V1 Rules, also known as Taurus, archetype deployment to the new V2 Rules archetype. Learn how to use it.
Foundry SQL Server: Connectors
MicroStrategy connector for Foundry datasets | Users of the MicroStrategy analytics platform can now use a MicroStrategy-certified connector for accessing Foundry datasets in reports and dossiers.