단위 테스트
이 페이지에서 설명하는 Python 저장소 단위 테스트는 배치 파이프라인에만 적용되며 스트리밍 파이프라인에서는 지원되지 않습니다.
Python 저장소에는 검사의 일부로 테스트를 실행하는 옵션이 있습니다. 이러한 테스트는 널리 사용되는 Python 테스트 프레임워크인 PyTest를 사용하여 실행됩니다.
CI 작업: condaPackRun
모든 CI 검사에는 다른 작업 중 condaPackRun이 포함되어 있습니다.
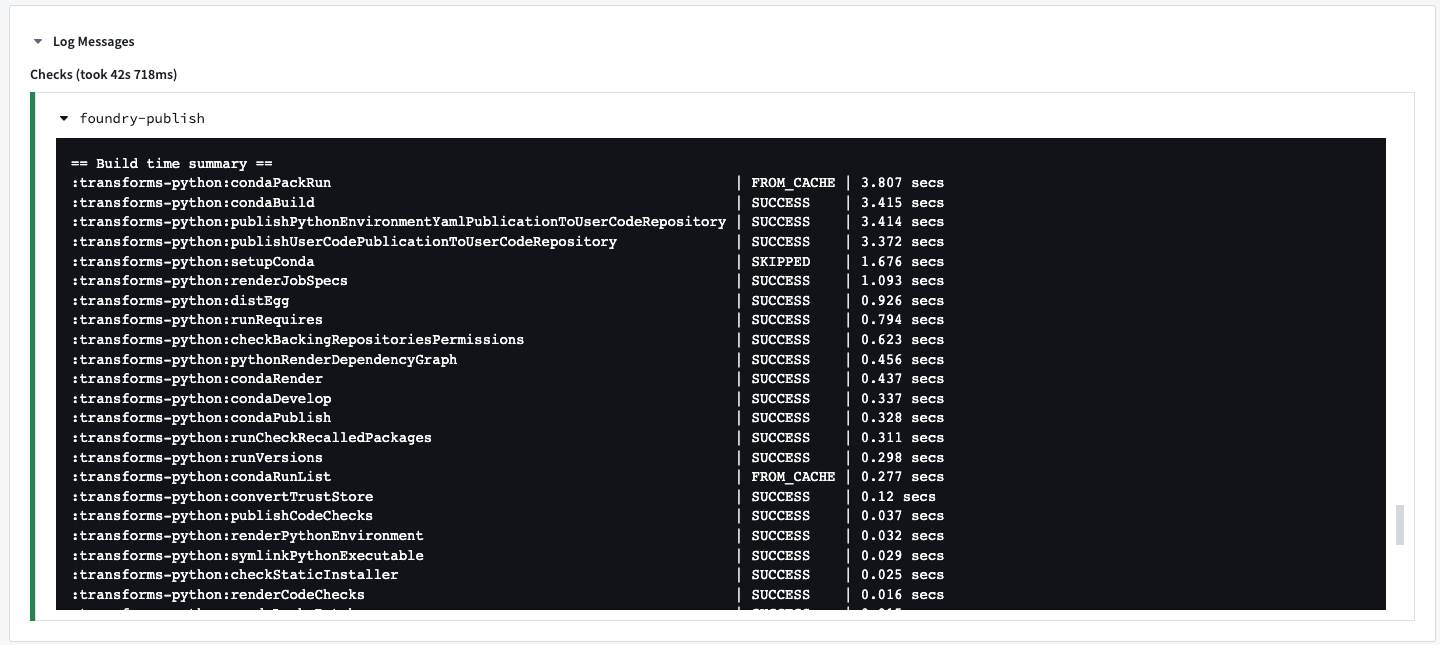
condaPackRun은 환경을 설치하는 데 책임이 있습니다. 각 아티팩트는 적절한 채널에서 검색되고, Conda는 이러한 아티팩트를 사용하여 환경을 구성합니다. 이 작업에는 세 단계가 포함됩니다:
- 해결된 환경에서 모든 패키지 다운로드 및 추출.
- 패키지 내용 확인. 구성에 따라, Conda는 체크섬을 사용하거나 파일 크기가 올바른지 확인합니다.
- 패키지를 환경에 연결.
환경 명세는 다음 빌드를 위한 캐시로 저장되며, 숨겨진 파일에 저장됩니다:
- conda-version-run.linux-64.lock
- conda-version-test.linux-64.lock
캐시는 7일 동안 저장됩니다. meta.yaml 파일에 변경 사항이 발생하면 다시 캐시됩니다.
이 작업은 저장소에 추가된 패키지 수에 크게 의존합니다. 패키지를 더 많이 추가할수록 작업이 느려집니다.
스타일 체크 활성화
PEP8 / PyLint 스타일 체크는 Python 프로젝트의 build.gradle 파일에 com.palantir.conda.pep8 및 com.palantir.conda.pylint Gradle 플러그인을 적용함으로써 활성화할 수 있습니다. 변환 저장소의 경우 이는 Python 하위 프로젝트에 위치해 있습니다. 라이브러리 저장소의 경우 이는 루트 폴더에 위치해 있습니다.
변환 build.gradle은 다음과 같이 보일 것입니다:
Copied!1 2 3 4 5 6 7 8 9 10// 'com.palantir.transforms.lang.python' 플러그인 적용 apply plugin: 'com.palantir.transforms.lang.python' // 'com.palantir.transforms.lang.python-defaults' 플러그인 적용 apply plugin: 'com.palantir.transforms.lang.python-defaults' // pep8 linting 플러그인 적용 // 'com.palantir.conda.pep8' 플러그인 적용 apply plugin: 'com.palantir.conda.pep8' // 'com.palantir.conda.pylint' 플러그인 적용 apply plugin: 'com.palantir.conda.pylint'
PyLint는 Python 프로젝트의 src/.pylintrc에서 설정할 수 있습니다. 예를 들어, 특정 메시지를 비활성화할 수 있습니다:
[메시지 제어]
disable =
# 모듈 설명문이 없음
missing-module-docstring,
# 함수 설명문이 없음
missing-function-docstring
Foundry에서 모든 PyLint 구성이 작동한다는 보장이 없습니다. src/.pylintrc의 기능이 검사에 표시되지 않으면 해당 기능이 지원되지 않음을 나타냅니다.
Spark 안티 패턴 플러그인 활성화
Spark 안티 패턴 린터는 Python 프로젝트의 build.gradle 파일에서 com.palantir.transforms.lang.antipattern-linter Gradle 플러그인을 적용함으로써 활성화할 수 있습니다.
Copied!1 2// 앤티패턴 린터 적용 apply plugin: 'com.palantir.transforms.lang.antipattern-linter'
Spark 안티패턴 플러그인은 Spark에서 일반적으로 발생하는 정확성 문제, Spark 성능 저하 및 보안 문제와 같은 안티패턴의 사용에 대해 경고합니다.
테스트 활성화
테스트는 Python 프로젝트의 build.gradle 파일에서 com.palantir.transforms.lang.pytest-defaults Gradle 플러그인을 적용함으로써 활성화할 수 있습니다. 변환 저장소의 경우, Python 서브프로젝트에 존재합니다. 라이브러리 저장소의 경우, 루트 폴더에 존재합니다.
변환용 build.gradle은 다음과 같이 보일 것입니다:
Copied!1 2 3 4 5apply plugin: 'com.palantir.transforms.lang.python' // 'com.palantir.transforms.lang.python' 플러그인 적용 apply plugin: 'com.palantir.transforms.lang.python-defaults' // 'com.palantir.transforms.lang.python-defaults' 플러그인 적용 // 테스팅 플러그인 적용 apply plugin: 'com.palantir.transforms.lang.pytest-defaults' // 'com.palantir.transforms.lang.pytest-defaults' 플러그인 적용
그리고 라이브러리 build.gradle은 다음과 같이 보일 것입니다:
Copied!1 2 3 4 5 6 7 8 9 10// 'com.palantir.transforms.lang.python-library' 플러그인 적용 apply plugin: 'com.palantir.transforms.lang.python-library' // 'com.palantir.transforms.lang.python-library-defaults' 플러그인 적용 apply plugin: 'com.palantir.transforms.lang.python-library-defaults' // 테스트 플러그인 적용 apply plugin: 'com.palantir.transforms.lang.pytest-defaults' // 태그가 붙은 릴리즈만을 위한 배포 (마지막 git 태그 이후 커밋이 없음) condaLibraryPublish.onlyIf { versionDetails().commitDistance == 0 }
meta.yaml에서 정의된 런타임 요구사항은 테스트에서 사용할 수 있습니다. 추가 요구사항은 conda test 섹션에서도 지정할 수 있습니다.
테스트 작성하기
전체 문서는 https://docs.pytest.org에서 찾을 수 있습니다.
PyTest는 test_로 시작하거나 _test.py로 끝나는 모든 파이썬 파일에서 테스트를 찾습니다. 프로젝트의 src 디렉토리 아래에 있는 test 패키지에 모든 테스트를 넣는 것이 좋습니다. 테스트는 test_ 접두사를 사용하여 명명된 파이썬 함수이며, 단언문은 파이썬의 assert 문을 사용하여 작성됩니다. PyTest는 파이썬의 내장 unittest 모듈을 사용하여 작성된 테스트도 실행합니다.
예를 들어, transforms-python/src/test/test_increment.py에서 간단한 테스트는 다음과 같이 작성할 수 있습니다:
Copied!1 2 3 4 5 6 7 8def increment(num): # 주어진 숫자에 1을 더한 값을 반환합니다. return num + 1 def test_increment(): # increment 함수를 테스트합니다. # increment(3)의 결과가 5와 같아야 합니다. assert increment(3) == 5
이 테스트를 실행하면 다음과 같은 메시지와 함께 체크가 실패합니다:
============================= 테스트 세션 시작 =============================
수집된 1개 아이템
test_increment.py F [100%]
================================== 실패 ===================================
_______________________________ test_increment ________________________________
def test_increment():
> assert increment(3) == 5
E assert 4 == 5
E + 여기서 4 = increment(3) # 여기서 함수 increment(3)의 결과는 4
test_increment.py:5: AssertionError
========================== 1개 실패, 0.08초 소요 ===========================
본 코드는 테스트 세션에서 increment 함수의 동작을 테스트하는 부분입니다. increment(3)의 예상되는 결과는 5지만 실제로는 4를 반환하여 테스트가 실패하였습니다.
PySpark으로 테스트하기
PyTest fixtures는 동일한 이름의 파라미터를 추가함으로써 테스트 함수에 값을 주입하는 강력한 기능입니다.
이 기능은 테스트 함수에서 사용하기 위한 spark_session fixture를 제공하는 데 사용됩니다. 예를 들면:
Copied!1 2 3 4 5 6 7def test_dataframe(spark_session): # 스파크 세션을 이용하여 DataFrame을 생성합니다. # 이 DataFrame은 두 개의 컬럼 'letter'와 'number'를 가지며, 각각 ['a', 1], ['b', 2]의 값을 가집니다. df = spark_session.createDataFrame([['a', 1], ['b', 2]], ['letter', 'number']) # 생성된 DataFrame의 스키마 이름이 'letter'와 'number'인지 확인합니다. assert df.schema.names == ['letter', 'number']
CSV에서 테스트 입력 생성하기
CSV 파일을 Code Repositories에 저장하여 데이터 변환을 테스트하는 데 사용할 수 있습니다.
다음 섹션은 transforms-python/src/myproject/datasets/에 작성된 다음 데이터 변환을 예시로 보여줍니다.
find_aircraft.py
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15# pyspark.sql 모듈에서 functions를 F로 임포트합니다. from pyspark.sql import functions as F # transforms.api 모듈에서 transform_df, Input, Output을 임포트합니다. from transforms.api import transform_df, Input, Output # transform_df 데코레이터를 사용하여 데이터 변환 함수를 정의합니다. # 입력 데이터 셋은 aircraft_df이며, 출력 데이터 셋의 ID는 "<output_dataset_rid>"입니다. @transform_df( Output("<output_dataset_rid>"), aircraft_df=Input("<input_dataset_rid>"), ) def compute(aircraft_df): # aircraft_df에서 "number_of_seats"가 300보다 크고, "operating_status"가 "Yes"인 행만 필터링하여 반환합니다. return aircraft_df.filter((F.col("number_of_seats") > F.lit(300)) & (F.col("operating_status") == F.lit("Yes")))
그리고 다음의 2개의 CSV 파일과 그것들의 각각의 내용을 폴더에 넣습니다:
transforms-python/src/test/resources/:
aircraft_mock.csv
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17# tail_number : 비행기의 고유 번호 # serial_number : 제조사 시리얼 번호 # manufacture_year : 제조 연도 # manufacturer : 제조사 이름 # model : 비행기 모델 # number_of_seats : 좌석 수 # capacity_in_pounds : 비행기의 수용 능력(파운드 단위) # operating_status : 운용 상태 (예, 아니오) # aircraft_status : 비행기 상태 (소유, 임대) # acquisition_date : 획득 날짜 # model_type : 모델 타입 tail_number,serial_number,manufacture_year,manufacturer,model,number_of_seats,capacity_in_pounds,operating_status,aircraft_status,acquisition_date,model_type AAA1,20809,1990,Manufacturer_1,M1-100,1,3500,Yes,Owned,13/8/90,208 BBB1,46970,2013,Manufacturer_2,M2-300,310,108500,No,Owned,10/15/14,777 CCC1,44662,2013,Manufacturer_2,M2-300,310,108500,Yes,Owned,6/23/13,777 DDD1,58340,2014,Manufacturer_3,M3-200,294,100000,Yes,Leased,11/21/13,330 EEE1,58600,2013,Manufacturer_2,M2-300,300,47200,Yes,Leased,12/2/13,777
expected_filtered_aircraft.csv
Copied!1 2 3 4 5 6 7 8 9 10 11 12# 각 열의 의미는 다음과 같습니다. # tail_number : 비행기의 꼬리 번호 # serial_number : 제조사에서 부여한 일련번호 # manufacture_year : 제조 연도 # manufacturer : 제조사 # model : 비행기 모델명 # number_of_seats : 좌석 수 # capacity_in_pounds : 화물 운송 능력(파운드 단위) # operating_status : 운용 상태 (운용 중이면 'Yes') # aircraft_status : 비행기 소유 상태 (소유하고 있다면 'Owned') # acquisition_date : 비행기를 획득한 날짜 # model_type : 비행기 모델 타입
다음 테스트는 transforms-python/src/test/ 경로에 작성될 수 있습니다:
test_find_aircraft.py
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34import os from pathlib import Path from myproject.datasets.find_aircraft import compute # 테스트 리소스 디렉터리 경로를 설정합니다. TEST_RESOURCES_DIRECTORY_PATH = Path(os.path.dirname(__file__)).joinpath('resources') def test_find_aircrafts(spark_session): # 'aircraft_mock.csv' 파일을 읽어서 DataFrame을 생성합니다. aircraft_mock_df = spark_session.read.csv( str(TEST_RESOURCES_DIRECTORY_PATH.joinpath('aircraft_mock.csv')), inferSchema=True, # 스키마를 자동으로 추론합니다. header=True # 첫 번째 행을 헤더로 사용합니다. ) # 'expected_filtered_aircraft.csv' 파일을 읽어서 예상되는 필터링된 항공기 DataFrame을 생성합니다. expected_filtered_aircraft_df = spark_session.read.csv( str(TEST_RESOURCES_DIRECTORY_PATH.joinpath('expected_filtered_aircraft.csv')), inferSchema=True, # 스키마를 자동으로 추론합니다. header=True # 첫 번째 행을 헤더로 사용합니다. ) # 'aircraft_mock_df'에 대하여 계산을 수행합니다. result_df = compute(aircraft_mock_df) # 결과 DataFrame의 열이 예상 DataFrame의 열과 일치하는지 검사합니다. assert result_df.columns == expected_filtered_aircraft_df.columns # 결과 DataFrame의 행 수가 예상 DataFrame의 행 수와 일치하는지 검사합니다. assert result_df.count() == expected_filtered_aircraft_df.count() # 결과 DataFrame이 예상 DataFrame에 없는 행이 없어야 합니다. assert result_df.exceptAll(expected_filtered_aircraft_df).count() == 0 # 예상 DataFrame이 결과 DataFrame에 없는 행이 없어야 합니다. assert expected_filtered_aircraft_df.exceptAll(result_df).count() == 0
최종 저장소 구조는 다음 이미지와 같습니다:
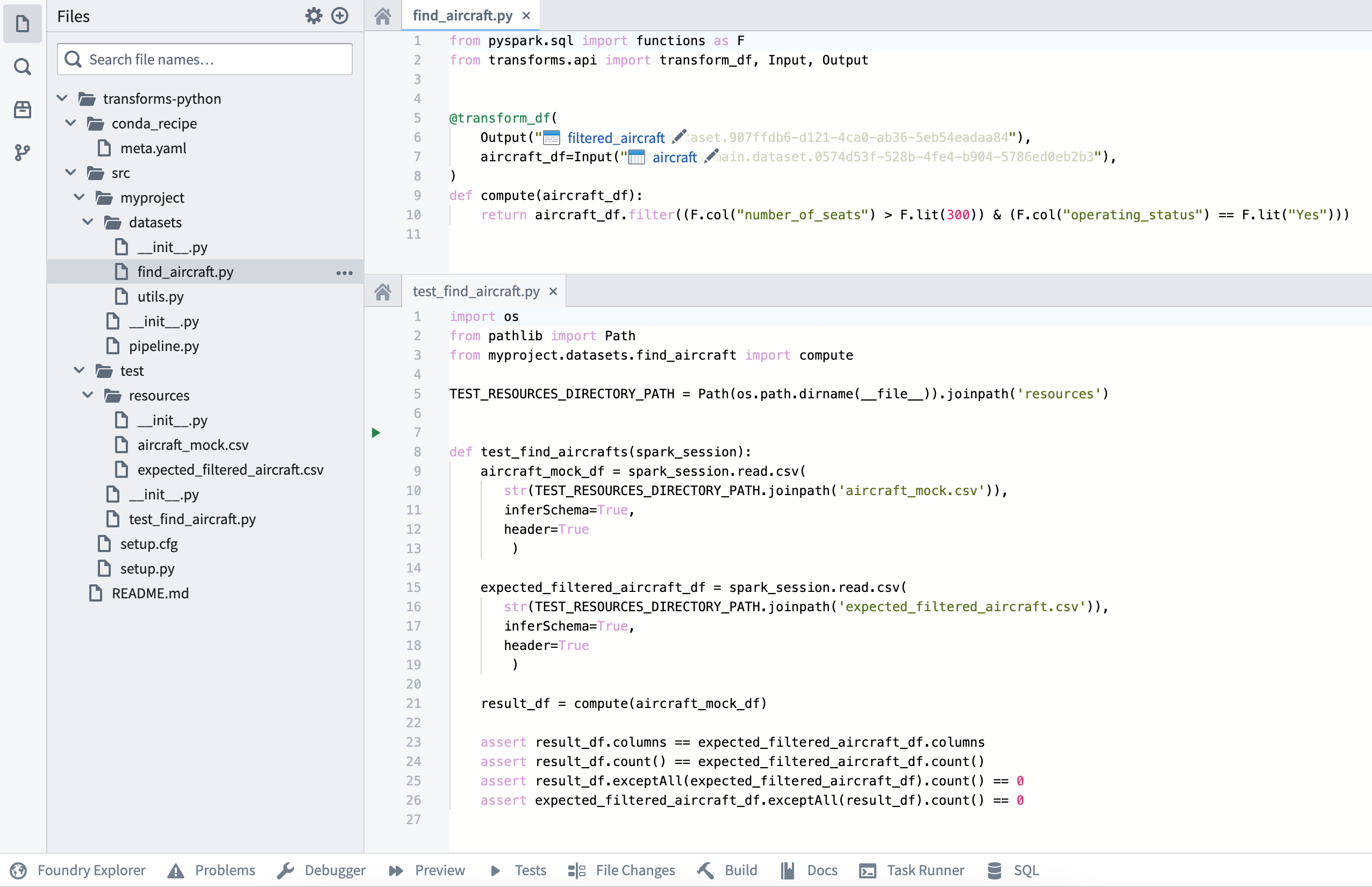
테스트는 transforms-python/src/test/test_find_aircraft.py에 위치합니다.
입력과 예상 결과물에 대한 CSV 리소스는 transforms-python/src/test/resources에 있습니다.
transform() 데코레이터에서 작성된 데이터프레임 가로채기
변환 함수가 transform_df 대신 transform()으로 장식되었을 때, 변환 함수는 결과 데이터프레임을 반환하지 않고 대신 함수에 전달된 Output 오브젝트 중 하나를 사용하여 결과를 데이터셋에 구체화합니다. 로직을 테스트하려면 구체화되어 보내질 값들을 가로채기 위해 Output 인수에 대해 모의를 사용해야 합니다.
위의 데이터 변환이 transform() 데코레이터를 사용하도록 변경된 것을 가정합니다:
find_aircraft_transform_decorator.py
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15from pyspark.sql import functions as F from transforms.api import transform, Input, Output # 트랜스폼 함수를 사용하여 입력 데이터를 처리하고 결과를 출력합니다. @transform( results_output=Output("<output_dataset_rid>"), # 결과를 출력할 데이터 세트를 지정합니다. aircraft_input=Input("<input_dataset_rid>"), # 처리할 입력 데이터 세트를 지정합니다. ) def compute(results_output, aircraft_input): aircraft_df = aircraft_input.dataframe() # 입력 데이터 세트를 데이터 프레임 형태로 변경합니다. # "number_of_seats"가 300보다 크고 "operating_status"가 "Yes"인 행만 필터링하여 결과 데이터 프레임을 생성합니다. results_df = aircraft_df.filter((F.col("number_of_seats") > F.lit(300)) & (F.col("operating_status") == F.lit("Yes"))) results_output.write_dataframe(results_df) # 결과 데이터 프레임을 출력 데이터 세트에 씁니다.
검증을 위한 테스트 중, 변환 함수는 이제 aircraft_input 인자에 대해 Input()을 기대하고 있으며, result_df의 값을 results_output으로 전송하기 위해 필요합니다.
MagicMock (외부)는 두 인스턴스에 필요한 래퍼를 생성하는 데 사용할 수 있습니다.
test_find_aircraft_transform_decorator.py
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48import os from pathlib import Path from unittest.mock import MagicMock from myproject.datasets.find_aircraft_transform_decorator import compute from transforms.api import Input # 테스트 리소스 디렉토리 경로 설정 TEST_RESOURCES_DIRECTORY_PATH = Path(os.path.dirname(__file__)).joinpath('resources') def test_find_aircrafts(spark_session): # 'aircraft_mock.csv' 파일을 읽어서 스파크 데이터프레임을 생성합니다. aircraft_mock_df = spark_session.read.csv( str(TEST_RESOURCES_DIRECTORY_PATH.joinpath('aircraft_mock.csv')), inferSchema=True, header=True ) # 예상되는 필터링된 항공기 데이터프레임을 'expected_filtered_aircraft.csv' 파일로부터 생성합니다. expected_filtered_aircraft_df = spark_session.read.csv( str(TEST_RESOURCES_DIRECTORY_PATH.joinpath('expected_filtered_aircraft.csv')), inferSchema=True, header=True ) # 출력을 위한 mock 객체 생성 results_output_mock = MagicMock() # 입력을 위한 래퍼 생성 및 반환될 데이터셋 설정 aircraft_mock_input = Input() aircraft_mock_input.dataframe = MagicMock(return_value=aircraft_mock_df) # mock 출력 객체를 사용하여 변환 실행 compute( results_output=results_output_mock, aircraft_input=aircraft_mock_input ) # mock 객체에 call_args를 사용하여 write_dataframe가 호출되는 인자를 가로챕니다. # 그리고 기록될 데이터프레임을 추출합니다. args, kwargs = results_output_mock.write_dataframe.call_args result_df = args[0] # 결과 데이터프레임과 예상 데이터프레임이 동일한지 확인합니다. assert result_df.columns == expected_filtered_aircraft_df.columns assert result_df.count() == expected_filtered_aircraft_df.count() assert result_df.exceptAll(expected_filtered_aircraft_df).count() == 0 assert expected_filtered_aircraft_df.exceptAll(result_df).count() == 0
테스트 결과 확인하기
설정된 모든 테스트의 결과는 Checks 탭에 각 테스트별로 별도의 결과물로 표시됩니다. 기본적으로 테스트 결과는 PASSED, FAILED, SKIPPED의 상태로 접혀서 표시됩니다. 각 테스트를 펼치거나 (또는 모든 테스트를 펼치면) 테스트 결과물과 함께 StdOut 및 StdErr 로그가 표시됩니다.
테스트 커버리지
PyTest 커버리지를 사용하여 저장소에서 커버리지를 계산하고 최소 퍼센테이지를 적용할 수 있습니다.
저장소의 meta.yml에 다음을 추가하세요:
Copied!1 2 3test: requires: - pytest-cov # pytest-cov는 테스트 코드의 커버리지를 측정하는 라이브러리입니다.
다음 내용을 포함하는 pytest.ini 파일을 /transforms-python/src/pytest.ini 에 생성하십시오:
Copied!1 2 3 4 5 6[pytest] # addopts: pytest 실행 시 추가적으로 주어질 옵션들을 설정합니다. # --cov: 테스트 커버리지를 계산할 패키지 이름을 설정합니다. 예를 들어, 패키지 이름이 'myproject'라면 --cov=myproject로 설정합니다. # --cov-report term: 테스트 커버리지 보고서를 터미널에 출력합니다. # --cov-fail-under=100: 테스트 커버리지가 100% 미만일 경우 테스트 실패로 처리합니다. addopts = --cov=<<패키지 이름, 예: myproject>> --cov-report term --cov-fail-under=100
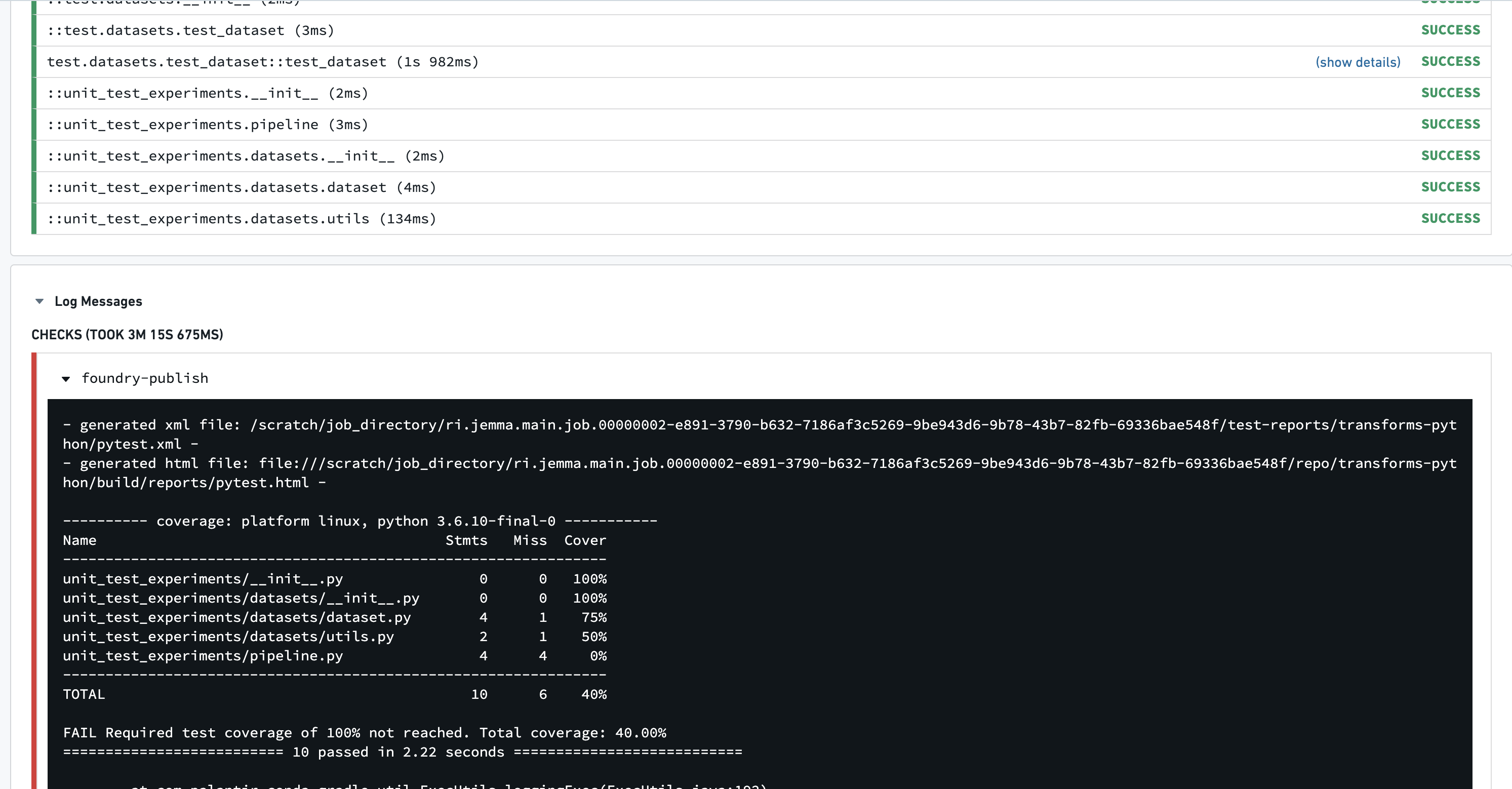
검사에 실패하는 데 필요한 커버리지는 사용자 정의 가능합니다. --cov-fail-under 인수에 대한 백분율을 선택하세요.
규정된 금액보다 적은 커버리지로 인해 테스트를 실행하면 이제 다음 출력으로 실패합니다:
테스트 병렬화
기본적으로 PyTest는 테스트를 순차적으로 실행합니다. 변환의 build.gradle을 조정하여 테스트를 여러 CPU로 보내어 테스트 실행 속도를 높일 수 있습니다. 여기에서 numProcesses 값을 사용할 프로세스 수를 반영하는 값으로 설정합니다.
Copied!1 2 3 4 5 6 7 8 9 10 11 12apply plugin: 'com.palantir.transforms.lang.python' apply plugin: 'com.palantir.transforms.lang.python-defaults' // 파이썬 플러그인 적용 apply plugin: 'com.palantir.transforms.lang.pytest-defaults' // 테스트 플러그인 적용 tasks.pytest { numProcesses "3" } // 동시에 실행할 프로세스 수 설정
테스트 병렬화는 pytest-xdist 테스팅 플러그인을 사용하여 실행됩니다.
테스트를 병렬화하면 대기 중인 테스트가 이용 가능한 작업자들에게 순서를 보장하지 않고 전송됩니다. 전역/공유 상태를 필요로 하고 다른 선행 테스트에 의해 변경이 이루어질 것으로 예상되는 테스트는 그에 따라 조정되어야 합니다.
팁
- 이 테스트를 활성화하면 커밋할 때 CI 로그에서
:transforms-python:pytest작업이 실행되는 것을 확인할 수 있습니다. - 파일과 함수 이름 모두 앞에
test_가 기준으로 테스트가 발견됩니다. 이는 PyTest 규칙에 따른 것입니다. - 예시 레코드를 빠르게 얻는 방법은 데이터셋을 Code Workbook 콘솔에서 열고
.collect()를 호출하는 것입니다. - Python 형식의 스키마를 얻으려면 데이터셋 미리보기를 열고 Columns 탭을 열어 Copy를 클릭한 다음 Copy PySpark Schema를 클릭합니다.