Spark 사이드카 변환
Spark 사이드카 변환을 사용하면, 컨테이너화된 코드를 배포하면서 Spark와 변환에서 제공하는 기존 인프라를 활용할 수 있습니다.
코드를 컨테이너화하면 Foundry에서 실행할 수 있는 모든 코드와 모든 의존성을 패키지화할 수 있습니다. 컨테이너화 워크플로는 변환과 통합되어 있어, 스케줄링, 브랜칭, 데이터 건강 등이 모두 원활하게 통합됩니다. 컨테이너화된 로직은 Spark executors와 함께 실행되므로, 입력 데이터와 함께 컨테이너화된 로직을 확장할 수 있습니다.
간단히 말해, 컨테이너에서 실행할 수 있는 모든 로직은 Foundry에서 데이터를 처리, 생성, 또는 소비하는 데 사용할 수 있습니다.
컨테이너화 개념에 익숙하다면, 아래 섹션을 사용하여 Spark 사이드카 변환 사용에 대해 더 알아보세요:
아키텍처
Foundry의 변환은 다음 다이어그램에 보여진 것처럼, Spark 드라이버를 사용하여 여러 실행자들에게 처리를 분배하여 데이터셋으로부터 데이터를 보내고 받을 수 있습니다.
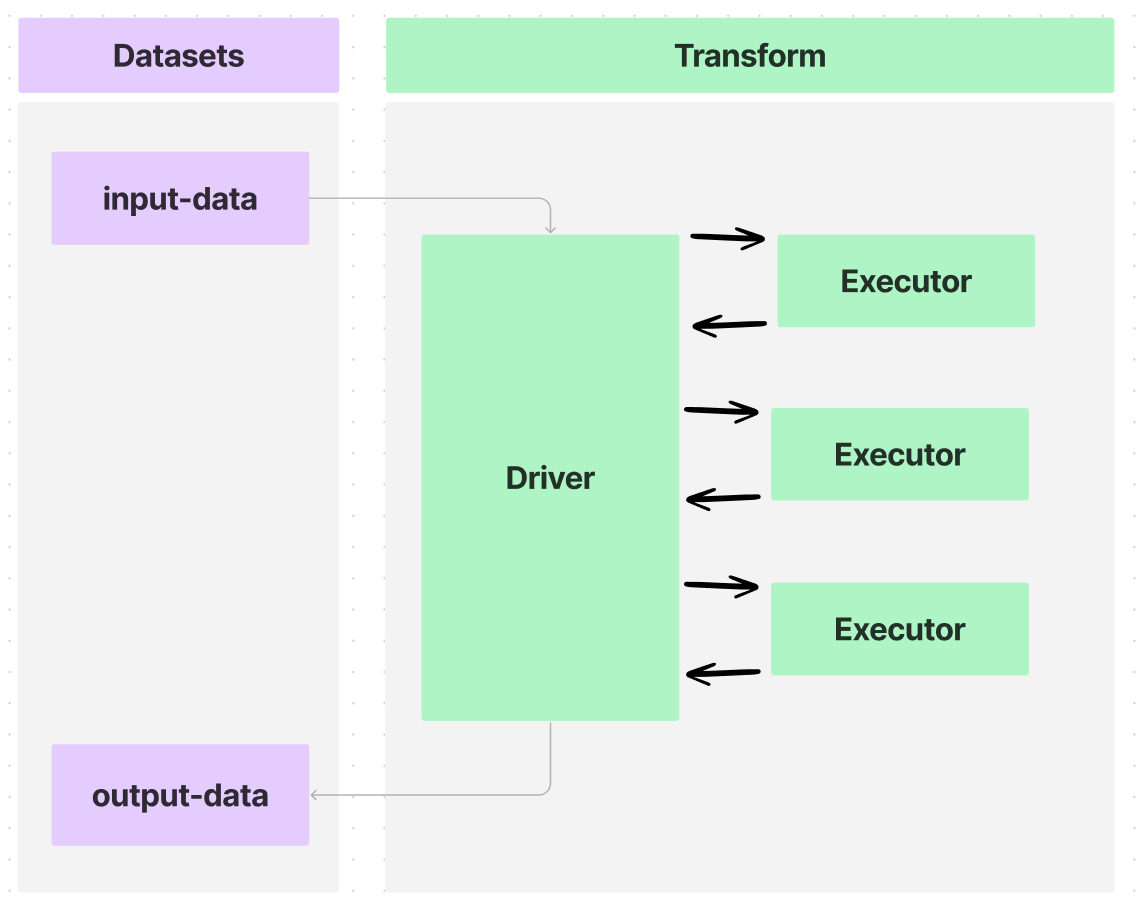
@sidecar 데코레이터(transforms-sidecar 라이브러리에서 제공)를 사용하여 변환을 주석 처리하면 PySpark 변환에서 각 실행자와 함께 시작하는 하나의 컨테이너를 정확히 지정할 수 있습니다. 사용자가 제공한 컨테이너는 맞춤형 로직을 가지고 각 실행자와 함께 실행되는데, 이를 사이드카 컨테이너라고 합니다.
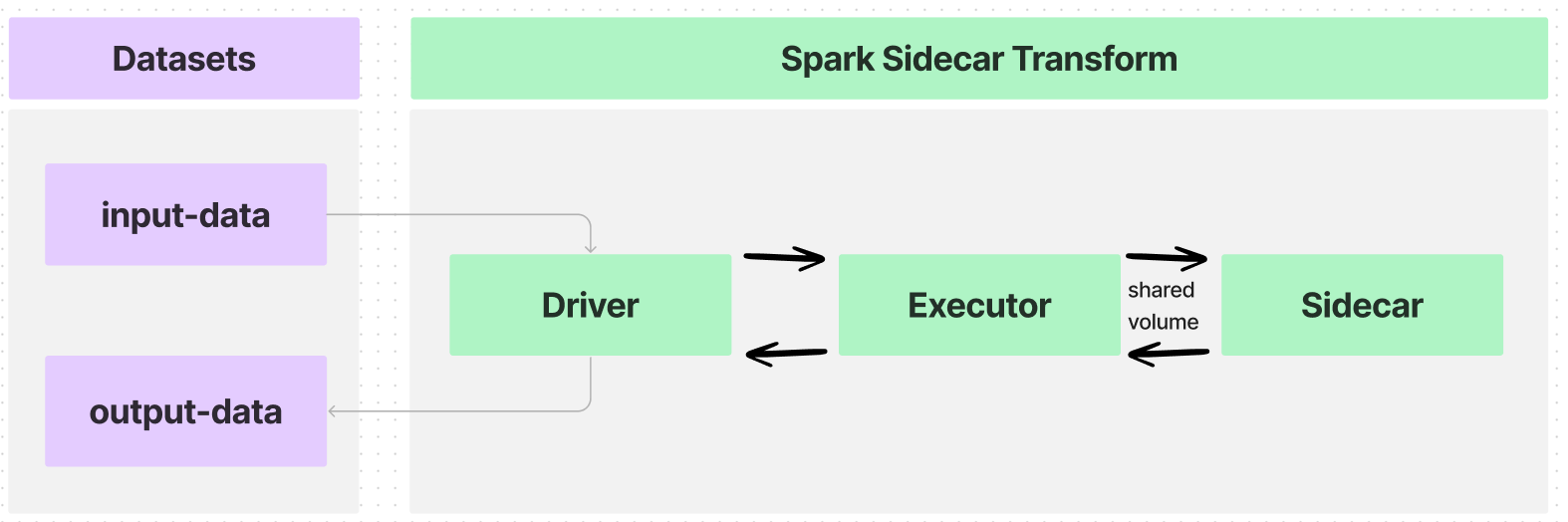
실행자가 하나만 있는 간단한 유즈케이스에서 데이터 흐름은 다음과 같습니다:
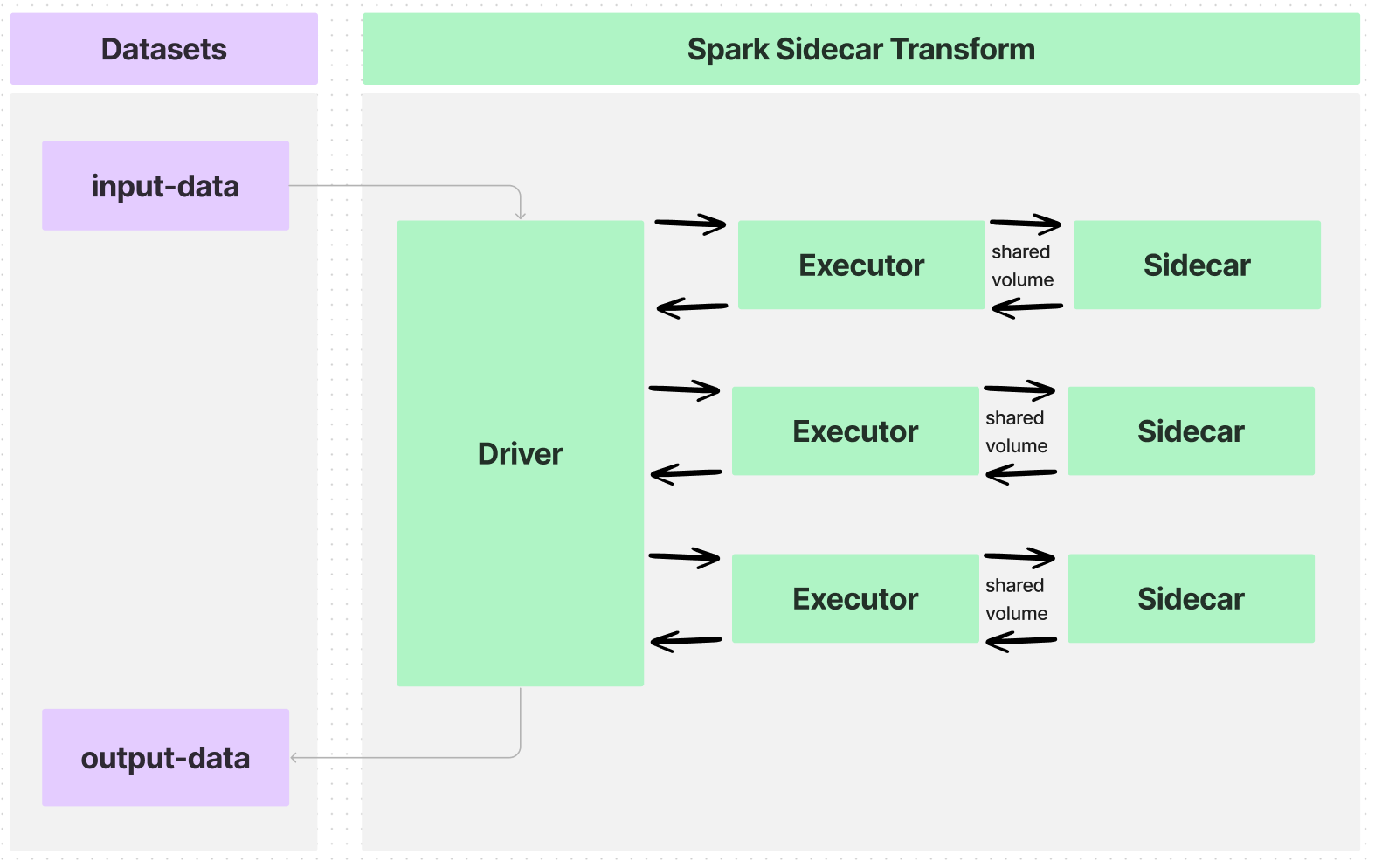
입력 데이터셋을 여러 실행자에게 파티션하는 변환을 작성하면, 데이터 흐름은 다음과 같습니다:
각 실행자와 사이드카 컨테이너 사이의 인터페이스는 공유 볼륨, 또는 다음과 같은 정보를 전달하는 디렉토리입니다:
- 컨테이너화된 로직의 실행을 언제 시작할지.
- 컨테이너에서 어떤 입력 데이터를 처리할지.
- 컨테이너에서 어떤 출력 데이터를 추출할지.
- 컨테이너화된 로직의 실행을 언제 종료할지.
이러한 공유 볼륨은 @sidecar 데코레이터의 Volume 인수를 사용하여 지정되며, 경로 /opt/palantir/sidecars/shared-volumes/ 내의 하위폴더가 될 것입니다.
다음 섹션들은 Spark 사이드카 변환을 준비하고 작성하는 방법을 안내할 것입니다.
이미지 빌드
Spark 사이드카 변환과 호환되는 이미지를 빌드하려면, 이미지는 이미지 요구사항을 충족해야 합니다. 또한 이미지는 아래에 설명된 핵심 컴포넌트를 포함해야 하며, 예제 Docker 이미지에 포함되어 있습니다. 이 예제 이미지를 빌드하려면, Python 스크립트 entrypoint.py가 필요합니다.
로컬 컴퓨터에 Docker가 설치되어 있어야 하며, docker CLI 명령(공식 문서)에 접근할 수 있어야 합니다.
Dockerfile
로컬 컴퓨터의 폴더에 Dockerfile이라는 파일을 생성하고, 다음 내용을 입력합니다:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21# Fedora 38 버전을 기반으로 한 새 Docker 이미지를 생성합니다. FROM fedora:38 # 현재 디렉토리에 있는 entrypoint.py 파일을 Docker 이미지 내 /usr/bin/entrypoint에 복사합니다. ADD entrypoint.py /usr/bin/entrypoint # /usr/bin/entrypoint 파일에 실행 권한을 추가합니다. RUN chmod +x /usr/bin/entrypoint # /opt/palantir/sidecars/shared-volumes/shared/ 디렉토리를 생성합니다. RUN mkdir -p /opt/palantir/sidecars/shared-volumes/shared/ # 생성된 디렉토리의 소유권을 사용자 ID 5001로 변경합니다. RUN chown 5001 /opt/palantir/sidecars/shared-volumes/shared/ # 환경 변수 SHARED_DIR를 /opt/palantir/sidecars/shared-volumes/shared로 설정합니다. ENV SHARED_DIR=/opt/palantir/sidecars/shared-volumes/shared # Docker 컨테이너가 실행될 때의 사용자를 ID 5001로 설정합니다. USER 5001 # Docker 컨테이너가 실행될 때 실행되는 명령을 설정합니다. 여기서는 entrypoint 스크립트에 -c 옵션으로 dd 명령을 전달하고 있습니다. # 이 dd 명령은 $SHARED_DIR/infile.csv를 읽어서 $SHARED_DIR/outfile.csv에 쓰는 역할을 합니다. ENTRYPOINT entrypoint -c "dd if=$SHARED_DIR/infile.csv of=$SHARED_DIR/outfile.csv"
사용자 정의 Dockerfile
위와 같이 직접 Dockerfile을 작성할 수 있지만, 다음 사항을 반드시 포함해야 합니다:
-
10번 줄에 숫자로 된 비루트 사용자를 지정합니다. 이는 이미지 요구사항 중 하나로, 컨테이너에 특권 실행을 부여하지 않고 적절한 보안 자세를 유지하는데 도움이 됩니다.
-
다음으로, 6-8줄에 공유 볼륨 생성을 배치합니다. 위의 아키텍처 섹션에서 논의한 바와 같이
/opt/palantir/sidecars/shared-volumes/내의 하위 디렉토리인 공유 볼륨은 PySpark 변환에서 사이드카 컨테이너로 입력 데이터와 결과 데이터를 공유하는 주요 방법입니다.- 6번 줄에서 디렉토리를 생성합니다.
- 7번 줄에서 생성된 사용자에게 디렉토리 권한을 부여합니다.
- 8번 줄에서 이 공유 디렉토리의 경로를 환경 변수로 저장하여 다른 곳에서 참조할 수 있게 합니다.
-
마지막으로, 3번 줄에 간단한
entrypoint스크립트를 컨테이너에 추가하고 12번 줄에서ENTRYPOINT로 설정합니다. 이 단계는 중요합니다. 왜냐하면 Spark 사이드카 변환은 기본적으로 사이드카 컨테이너가 컨테이너 시작 전에 입력 데이터를 사용할 수 있는 상태로 대기하도록 지시하지 않기 때문입니다. 또한, 사이드카 변환은 결과 데이터를 복사하여 제거할 때까지 컨테이너가 계속 실행되도록 지시하지 않습니다. 제공된entrypoint스크립트는 Python을 사용하여 지정된 로직이 실행되기 전에 공유 볼륨에start_flag파일이 쓰여질 때까지 컨테이너가 대기하도록 지시합니다. 지정된 로직이 완료되면 같은 디렉토리에done_flag를 작성합니다. 컨테이너는 공유 볼륨에close_flag가 쓰여질 때까지 대기한 다음, 자체를 중지하고 자동으로 정리됩니다.
위의 예에서와 같이, 컨테이너화된 로직은 POSIX 디스크 덤프(dd) 유틸리티를 사용하여 공유 디렉토리에서 입력 CSV 파일을 동일한 디렉토리에 저장된 결과 파일로 복사합니다. 이 "명령"은 entrypoint 스크립트에 전달되며, 컨테이너에서 실행할 수 있는 모든 로직이 될 수 있습니다.
Entrypoint
Dockerfile과 같은 로컬 폴더에, 다음 코드 스니펫을 entrypoint.py라는 파일로 복사합니다.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46#!/usr/bin/env python3 import os import time import subprocess from datetime import datetime import argparse parser = argparse.ArgumentParser() parser.add_argument("-c", "--command", type=str, help="실행할 모델 명령어") args = parser.parse_args() the_command = args.command.split(" ") # 명령어를 실행하고 출력을 한 줄씩 캡쳐하는 함수 정의 def run_process(exe): p = subprocess.Popen(exe, stdout=subprocess.PIPE, stderr=subprocess.STDOUT) return iter(p.stdout.readline, b"") start_flag_fname = "/opt/palantir/sidecars/shared-volumes/shared/start_flag" done_flag_fname = "/opt/palantir/sidecars/shared-volumes/shared/done_flag" close_flag_fname = "/opt/palantir/sidecars/shared-volumes/shared/close_flag" # 시작 플래그 대기 print(f"{datetime.utcnow().isoformat()}: 시작 플래그 대기 중") while not os.path.exists(start_flag_fname): time.sleep(1) print(f"{datetime.utcnow().isoformat()}: 시작 플래그 감지됨") # 모델 실행, 출력 로그 파일에 기록 with open("/opt/palantir/sidecars/shared-volumes/shared/logfile", "w") as logfile: for item in run_process(the_command): my_string = f"{datetime.utcnow().isoformat()}: {item}" print(my_string) logfile.write(my_string) logfile.flush() print(f"{datetime.utcnow().isoformat()}: 실행 완료, 출력 파일 기록") # 완료 플래그 출력 open(done_flag_fname, "w") print(f"{datetime.utcnow().isoformat()}: 완료 플래그 파일 작성") # 스크립트 종료를 허용하기 전에 닫기 플래그 대기 while not os.path.exists(close_flag_fname): time.sleep(1) print(f"{datetime.utcnow().isoformat()}: 닫기 플래그 감지됨. 종료")
이미지 푸시하기
이미지를 푸시하려면, 새로운 아티팩트 저장소를 생성하고 해당 Docker 저장소에 이미지를 태그하고 푸시하는 방법에 따라 진행하십시오.
- 유형을
Docker로 변경합니다.
- 화면의 안내에 따라 토큰을 생성합니다.
- 다음 명령 패턴으로 예제 이미지를 빌드합니다
docker build . --tag <container_registry>/<image_name>:<image_tag> --platform linux/amd64, 여기서:
container_registry는 Foundry 인스턴스 컨테이너 레지스트리 주소를 나타내며, Docker 이미지를 아티팩트 저장소로 푸시하는 방법에 대한 마지막 명령어의 일부로 찾을 수 있습니다.image_name과image_tag는 사용자 재량에 따라 설정하십시오. 이 예제에서는simple_example:0.0.1을 사용합니다.
- 아티팩트 저장소에서 지시사항을 복사하여 붙여넣어 로컬에 빌드된 이미지를 푸시합니다; 마지막 명령어에서
<image_name>:<image_version>를 위의 이미지 빌드 단계에서 사용한image_name과image_version으로 교체합니다.
Spark 사이드카 변환 작성하기
- Code Repositories 애플리케이션에서 Python 데이터 변환 저장소 생성하기
- 왼쪽의 라이브러리 탭에서
transforms-sidecar를 추가하고 변경 사항을 커밋합니다. - 설정 > 라이브러리에서 아티팩트 저장소를 추가합니다.
- 변환을 작성합니다.
다음 예제들은 사이드카 변환을 시작하는 데 필요한 주요 정보를 검토합니다. 두 예제 모두 여기에서 찾을 수 있는 동일한 유틸리티 파일을 사용하며, 아래에 표시된 대로 Code Repositories에 추가하고 가져올 수 있습니다.
예제 1: 단일 실행
아래의 변환은 transforms-sidecar 라이브러리에서 @sidecar 데코레이터와 Volume 원시를 가져옵니다.
변환은 어노테이션을 위해 두 항목을 모두 사용하며, simple-example:0.0.1 컨테이너의 인스턴스가 각 실행기와 함께 시작됩니다. 각 실행기/사이드카 쌍은 /opt/palantir/sidecars/shared-volumes/shared에서 공유 볼륨을 가집니다.
이 첫 번째 예제는 하나의 컨테이너 인스턴스를 하나의 실행기와 함께 시작하고, 아래 이미지에 표시된 아키텍처를 따릅니다:
그런 다음 변환은 유틸리티 함수 lanch_udf_once를 사용하여 user_defined_function의 인스턴스 하나를 시작합니다. 이 사용자 정의 함수는 하나의 실행기에서 실행되며 하나의 사이드카 컨테이너 인스턴스와 통신합니다. 사용자 정의 함수는 가져온 유틸리티 함수를 호출하여 다음을 수행합니다:
- 입력 파일을 공유 디렉토리로 복사하여 사이드카 컨테이너가 접근할 수 있게 합니다.
- 시작 플래그를 복사하여 사이드카 컨테이너가 실행을 시작하도록 합니다.
- 컨테이너화된 로직이 완료될 때까지 기다립니다.
- 컨테이너화된 로직에 의해 생성된 파일을 복사합니다.
- 컨테이너가 중지되어 정리될 수 있도록 종료 플래그를 복사합니다.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33from transforms.api import transform, Input, Output from transforms.sidecar import sidecar, Volume from myproject.datasets.utils import copy_files_to_shared_directory, copy_start_flag, wait_for_done_flag from myproject.datasets.utils import copy_output_files, copy_close_flag, launch_udf_once # 간단한 예시 이미지 사용하고 볼륨 공유 설정 @sidecar(image='simple-example', tag='0.0.1', volumes=[Volume("shared")]) @transform( output=Output("<output dataset rid>"), source=Input("<input dataset rid>"), ) def compute(output, source, ctx): def user_defined_function(row): # 소스로부터 공유된 디렉토리에 파일 복사 copy_files_to_shared_directory(source) # 컨테이너가 모든 입력 파일을 갖고 있다는 것을 알리기 위해 시작 플래그 전송 copy_start_flag() # 중지 플래그가 작성되거나 최대 시간 제한에 도달할 때까지 반복 wait_for_done_flag() # 컨테이너로부터 출력 파일 복사하여 출력 데이터셋에 저장 output_fnames = [ "start_flag", "outfile.csv", "logfile", "done_flag", ] copy_output_files(output, output_fnames) # 데이터를 추출했다는 것을 컨테이너에 알리기 위해 종료 플래그 작성 copy_close_flag() # 사용자 정의 함수는 반드시 어떤 값을 반환해야 함 return (row.ExecutionID, "success") # 이것은 하나의 작업을 생성하며, 하나의 실행기에 매핑되고, 하나의 "사이드카 컨테이너"를 실행합니다. launch_udf_once(ctx, user_defined_function)
예시 2: 병렬 실행
이 예시는 사이드카 컨테이너의 여러 인스턴스를 실행하여 입력 데이터의 하위 집합을 처리합니다. 그런 다음 정보를 수집하여 결과물 데이터셋에 저장합니다. 이 예제는 아래에 표시된 아키텍처와 더 밀접하게 관련되어 있습니다.
다음 변환은 입력 데이터를 분할하고 개별 파일을 각 컨테이너에 보내어 다른 입력 데이터 조각에 대해 동일한 실행을 수행하는 다양한 유틸리티 함수를 사용합니다. 유틸리티 함수는 결과물 파일을 개별 파일과 탭 형식의 결과물 데이터셋으로 저장하도록 작성되었습니다.
@sidecar 데코레이터와 Volume 명세에 대해 예시 1과 동일한 매개 변수가 구성되어 있음을 확인할 수 있습니다.
@configure 플래그가 설정되어 실행기 당 하나의 작업만 시작되고 정확히 네 개의 실행기가 시작될 수 있도록 합니다. 이 구성과 입력 데이터셋에 정확히 네 개의 데이터 행이 있고 입력 재분할이 4로 설정된 사실을 결합하면 사용자 지정 함수의 네 개 인스턴스가 네 개의 실행기에서 시작됩니다. 따라서 정확히 네 개의 사이드카 컨테이너가 시작되어 입력 데이터의 세그먼트를 처리합니다.
저장소에 설정 > 스파크에서 두 개의 스파크 프로필이 가져온 것을 확인하십시오.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49from transforms.api import transform, Input, Output, configure from transforms.sidecar import sidecar, Volume import uuid from myproject.datasets.utils import copy_start_flag, wait_for_done_flag, copy_close_flag from myproject.datasets.utils import write_this_row_as_a_csv_with_one_row from myproject.datasets.utils import copy_output_files_with_prefix, copy_out_a_row_from_the_output_csv # 설정: 작은 크기의 실행자 코어와 4개의 실행자 사용 @configure(["EXECUTOR_CORES_EXTRA_SMALL", "NUM_EXECUTORS_4"]) @sidecar(image='simple-example', tag='0.0.1', volumes=[Volume("shared")]) @transform( output=Output("<first output dataset rid>"), output_rows=Output("<second output dataset rid>"), source=Input("<input dataset rid>"), ) def compute(output, output_rows, source, ctx): def user_defined_function(row): # 입력 파일을 공유 디렉터리로 복사 write_this_row_as_a_csv_with_one_row(row) # 시작 플래그를 보내서 컨테이너가 입력 파일을 모두 가지고 있다는 것을 알림 copy_start_flag() # 중지 플래그가 쓰여지거나 최대 시간 제한에 도달할 때까지 반복 wait_for_done_flag() # 컨테이너에서 출력 데이터셋으로 출력 파일 복사 output_fnames = [ "start_flag", "infile.csv", "outfile.csv", "logfile", "done_flag", ] random_unique_prefix = f'{uuid.uuid4()}'[:8] copy_output_files_with_prefix(output, output_fnames, random_unique_prefix) outdata1, outdata2, outdata3 = copy_out_a_row_from_the_output_csv() # 데이터를 추출했다는 것을 컨테이너에 알리기 위해 종료 플래그 작성 copy_close_flag() # 사용자 정의 함수는 반드시 값을 반환해야 함 return (row.data1, row.data2, row.data3, "success", outdata1, outdata2, outdata3) results = source.dataframe().repartition(4).rdd.map(user_defined_function) columns = ["data1", "data2", "data3", "success", "outdata1", "outdata2", "outdata3"] output_rows.write_dataframe(results.toDF(columns))
예제 유틸리티
utils.py
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91import os import shutil import time import csv import pyspark.sql.types as T VOLUME_PATH = "/opt/palantir/sidecars/shared-volumes/shared" # 공유 볼륨 경로 설정 MAX_RUN_MINUTES = 10 # 최대 실행 시간 설정 def write_this_row_as_a_csv_with_one_row(row): # 이 함수는 하나의 행을 CSV 파일로 작성합니다. in_path = "/opt/palantir/sidecars/shared-volumes/shared/infile.csv" with open(in_path, 'w', newline='') as csvfile: writer = csv.writer(csvfile, delimiter=',') writer.writerow(['data1', 'data2', 'data3']) writer.writerow([row.data1, row.data2, row.data3]) def copy_out_a_row_from_the_output_csv(): # 이 함수는 출력 CSV에서 행을 복사하여 불러옵니다. out_path = "/opt/palantir/sidecars/shared-volumes/shared/outfile.csv" with open(out_path, newline='') as csvfile: reader = csv.reader(csvfile, delimiter=',', quotechar='|') values = "", "", "" for myrow in reader: values = myrow[0], myrow[1], myrow[2] return values def copy_output_files_with_prefix(output, output_fnames, prefix): # 이 함수는 접두사가 있는 출력 파일을 복사합니다. for file_path in output_fnames: output_fs = output.filesystem() out_path = os.path.join(VOLUME_PATH, file_path) try: with open(out_path, "rb") as shared_file: with output_fs.open(f'{prefix}_{file_path}', "wb") as output_file: shutil.copyfileobj(shared_file, output_file) except FileNotFoundError as err: print(err) def copy_files_to_shared_directory(source): # 이 함수는 파일을 공유 디렉토리로 복사합니다. source_fs = source.filesystem() for item in source_fs.ls(): file_path = item.path with source_fs.open(file_path, "rb") as source_file: dest_path = os.path.join(VOLUME_PATH, file_path) with open(dest_path, "wb") as shared_file: shutil.copyfileobj(source_file, shared_file) def copy_start_flag(): # 이 함수는 'start_flag'를 복사합니다. open(os.path.join(VOLUME_PATH, 'start_flag'), 'w') time.sleep(1) def wait_for_done_flag(): # 이 함수는 'done_flag'가 나타날 때까지 기다립니다. i = 0 while i < 60 * MAX_RUN_MINUTES and not os.path.exists(os.path.join(VOLUME_PATH, 'done_flag')): i += 1 time.sleep(1) def copy_output_files(output, output_fnames): # 이 함수는 출력 파일을 복사합니다. for file_path in output_fnames: output_fs = output.filesystem() out_path = os.path.join(VOLUME_PATH, file_path) try: with open(out_path, "rb") as shared_file: with output_fs.open(file_path, "wb") as output_file: shutil.copyfileobj(shared_file, output_file) except FileNotFoundError as err: print(err) def copy_close_flag(): # 이 함수는 'close_flag'를 복사합니다. time.sleep(5) open(os.path.join(VOLUME_PATH, 'close_flag'), 'w') # 'close_flag'를 보냅니다. def launch_udf_once(ctx, user_defined_function): # 하나의 행을 가진 데이터프레임을 사용하여 사용자 정의 함수를 한 번 실행합니다. schema = T.StructType([T.StructField("ExecutionID", T.IntegerType())]) ctx.spark_session.createDataFrame([{"ExecutionID": 1}], schema=schema).rdd.foreach(user_defined_function)