스냅샷에서 역사적 데이터셋 생성
가능하다면, 이 유형의 데이터셋은 처음부터 APPEND 트랜잭션으로 삽입되는 것이 모범사례입니다. 추가 세부사항은 아래의 경고를 참조하세요.
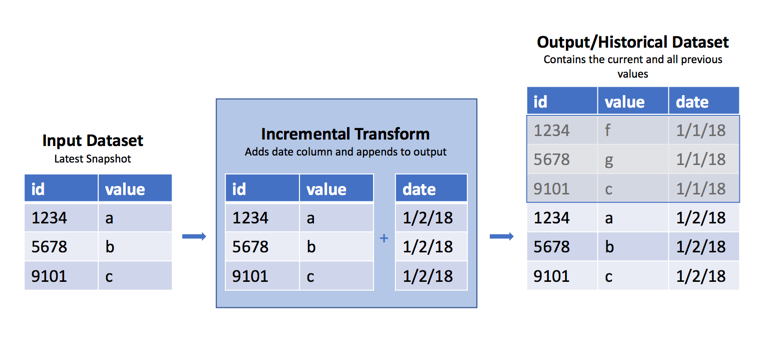
워크플로 전체보기
가끔 원시 데이터셋이 있을 때 매일/매주/매시간 새로운 SNAPSHOT import가 이전의 보기를 데이터셋의 현재 데이터로 대체합니다. 그러나 이전 데이터를 유지하는 것이 종종 유용하며, 이전 뷰에서 무엇이 변경되었는지 파악할 수 있습니다. 위에서 언급했듯이, 이 경우의 모범 사례는 APPEND 트랜잭션을 사용하여 삽입을 처리하고 임포트 날짜를 추가하는 열을 추가하는 것입니다. 그러나 이것이 불가능한 경우에는 Python 변환에서 incremental() 데코레이터를 사용하여 이러한 정기적인 SNAPSHOT을 해당 데이터셋의 역사적인 버전에 추가할 수 있습니다. 이 접근법의 취약성에 대한 주의사항은 아래 경고를 참조하세요.
샘플 코드
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13@incremental(snapshot_inputs=['input_data']) @transform( input_data=Input("/path/to/snapshot/input"), # 스냅샷 입력에 대한 경로를 설정합니다. history=Output("/path/to/historical/dataset"), # 과거 데이터셋에 대한 경로를 설정합니다. ) def my_compute_function(input_data, history): # my_compute_function 이라는 함수를 정의합니다. input_df = input_data.dataframe() # 입력 데이터를 데이터프레임으로 변환합니다. # 아래에서 current_timestamp()도 사용할 수 있습니다. # 입력이 하루에 1회 이상 바뀔 경우에 사용 가능합니다. input_df = input_df.withColumn('date', current_date()) # 'date'라는 새로운 열을 추가하고, 그 값으로 현재 날짜를 설정합니다. history.write_dataframe(input_df) # 변환된 데이터프레임을 과거 데이터셋에 쓰기합니다.
왜 이 방법이 작동하는가
incremental 데코레이터는 입력값과 결과물에 대한 읽기/쓰기 모드에 추가 로직을 적용합니다. 위의 예시에서는 입력값과 결과물에 대해 기본값 읽기/쓰기 모드를 사용합니다.
읽기 모드
SNAPSHOT 입력값을 사용할 때, 기본 읽기 모드는 current이며, 이는 마지막 트랜잭션 이후에 추가된 행들만이 아니라 전체 입력 데이터프레임을 가져온다는 것을 의미합니다. 만약 입력 데이터셋이 APPEND 트랜잭션에서 생성되었다면, incremental() 데코레이터를 사용하여 마지막 빌드 이후에 추가된 행들만 접근할 수 있는 added 읽기 모드를 사용할 수 있습니다.
변환은 current 결과물에서 스키마 정보를 얻으므로, 데이터프레임의 previous 버젼을 읽을 때처럼 스키마 정보를 전달할 필요가 없습니다 (예: dataframe('previous', schema=input.schema)).
쓰기 모드
변환을 점진적으로 실행한다는 것은, 결과물에 대한 기본 쓰기 모드가 modify로 설정된다는 것을 의미합니다. 이 모드는 빌드 중에 작성된 데이터로 기존 결과물을 수정합니다. 예를 들어, 결과물이 modify 모드에 있을 때 write_dataframe()를 호출하면, 작성된 데이터프레임이 기존 결과물에 추가됩니다. 이것이 바로 이 경우에 일어나는 것입니다.
경고
이 변환은 SNAPSHOT 데이터셋을 입력값으로 사용하기 때문에, 빌드 실패나 다른 이유로 인해 놓친 스냅샷을 복구할 방법이 없습니다. 이것이 문제라면, 이 방법을 사용하지 마십시오. 대신 입력 데이터셋의 소유자에게 연락하여 이것을 APPEND 데이터셋으로 변환할 수 있는지 확인해 보세요. 그래야 데이터셋의 이전 트랜잭션을 접근할 수 있습니다. 이것이 점진적 계산이 설계된 방법입니다.
다음 경우에 실패할 수 있습니다:
- 입력 데이터셋에 열이 추가될 경우
- 기존 표의 열 번호가 [입력] 데이터 스키마와 일치하지 않는 경우
- 입력 데이터셋의 열이 데이터타입을 변경할 경우 (예:
integer에서decimal로) - 입력 데이터셋을 변경하는 경우, 심지어 그 데이터셋이 동일한 스키마를 가지고 있더라도. 이 경우, 입력을 결과물에 추가하는 대신 완전히 대체합니다.
리소스 사용량 증가
이 패턴을 사용하면, 역사적 데이터셋에서 작은 파일들이 누적될 수 있습니다. 파일 누적은 바람직하지 않은 결과며, 이 역사적 데이터셋을 사용하는 하위 변환 또는 분석에서 빌드 시간과 리소스 사용량이 증가하게 됩니다. 배치 및 인터랙티브 계산 시간이 증가할 수 있습니다. 왜냐하면 각 파일을 읽는 데 오버헤드가 있기 때문입니다. 디스크 사용량도 증가할 수 있습니다. 왜냐하면 압축은 데이터셋 내의 파일 간이 아니라 파일별로 수행되기 때문입니다. 이러한 행동이 발생하는 것을 방지하기 위해 데이터의 재스냅샷을 주기적으로 유발하는 로직을 구축하는 것이 가능합니다.
결과물 파일의 수를 검사함으로써, 최적의 incremental write mode를 결정할 수 있습니다. 이 모드를 사용하면, 이전 트랜잭션의 결과물을 데이터프레임으로 읽어 들이고, 들어오는 데이터에 연합하고, 데이터 파일들을 함께 병합하여, 많은 작은 파일들을 하나의 큰 파일로 변환하는 것이 가능합니다.
결과물 데이터셋의 파일 시스템에서 파일의 수를 검사하고, 다음 예시처럼 if 문을 사용하여 write_mode를 설정합니다:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44from transforms.api import transform, Input, Output, configure, incremental from pyspark.sql import types as T FILE_COUNT_LIMIT = 100 # 여기에 원하는 출력 스키마를 입력하세요 schema = T.StructType([ T.StructField('Value', T.DoubleType()), # 'Value' 필드는 Double 형식입니다. T.StructField('Time', T.TimestampType()), # 'Time' 필드는 Timestamp 형식입니다. T.StructField('DataGroup', T.StringType()) # 'DataGroup' 필드는 String 형식입니다. ]) def compute_logic(df): """ 이것은 변환 로직입니다 """ return df.filter(True) # 모든 조건이 참인 행을 필터링합니다. @configure(profile=["KUBERNETES_NO_EXECUTORS"]) # 프로필 설정: "KUBERNETES_NO_EXECUTORS" @incremental(semantic_version=1) # 증분 업데이트 버전: 1 @transform( output=Output("/Org/Project/Folder1/Output_dataset_incremental"), # 출력 경로 설정 input_df=Input("/Org/Project/Folder1/Input_dataset_incremental"), # 입력 경로 설정 ) def compute(input_df, output): df = input_df.dataframe('added') # 추가된 데이터 프레임을 가져옵니다. df = compute_logic(df) # 위에서 정의한 로직에 따라 데이터 프레임을 처리합니다. # 데이터셋에 있는 파일 목록을 가져옵니다. files = list(output.filesystem(mode='previous').ls()) if (len(files) > FILE_COUNT_LIMIT): # 파일 개수가 설정된 제한보다 많으면 # 증분 병합 및 대체 previous_df = output.dataframe('previous', schema) # 이전 데이터 프레임을 가져옵니다. df = df.unionByName(previous_df) # 가져온 데이터 프레임을 현재 데이터 프레임과 병합합니다. mode = 'replace' # 모드를 'replace'로 설정합니다. else: # 표준 증분 모드 mode = 'modify' # 모드를 'modify'로 설정합니다. output.set_mode(mode) # 설정된 모드를 적용합니다. output.write_dataframe(df.coalesce(1)) # 데이터 프레임을 출력합니다.