Pipeline Builder에서 LLM 노드 사용하기
Pipeline Builder에서 LLM 노드를 사용하면 대규모 언어 모델 (LLMs)을 대규모로 데이터에 실행하는 편리한 방법을 제공합니다. 이 노드가 Pipeline Builder에 통합되면 다양한 데이터 변환 사이에 LLM 처리 로직을 매끄럽게 통합할 수 있어 코드 작성 없이 LLM을 파이프라인에 통합하는 것이 간편해집니다.
LLM 노드는 다섯 가지 사전 엔지니어링 프롬프트 템플릿을 포함하고 있습니다. 이 템플릿들은 경험이 많은 프롬프트 엔지니어의 전문성을 활용하여 LLM 사용을 처음 시작하는 사용자에게 친숙한 시작을 제공합니다. 또한, 전체 데이터셋에서 모델을 실행하기 전에 프롬프트를 반복적으로 수정하기 위해 입력 데이터셋의 몇 줄에 대해 trial runs을 실행할 수도 있습니다. 이 미리보기 기능은 몇 초 안에 계산되어 피드백 반복을 가속화하고 전체 개발 과정을 향상시킵니다.
데이터셋 선택하기
LLM을 데이터셋에 적용하려면 작업 공간에서 데이터셋 노드를 선택하고 LLM 사용하기를 선택합니다.
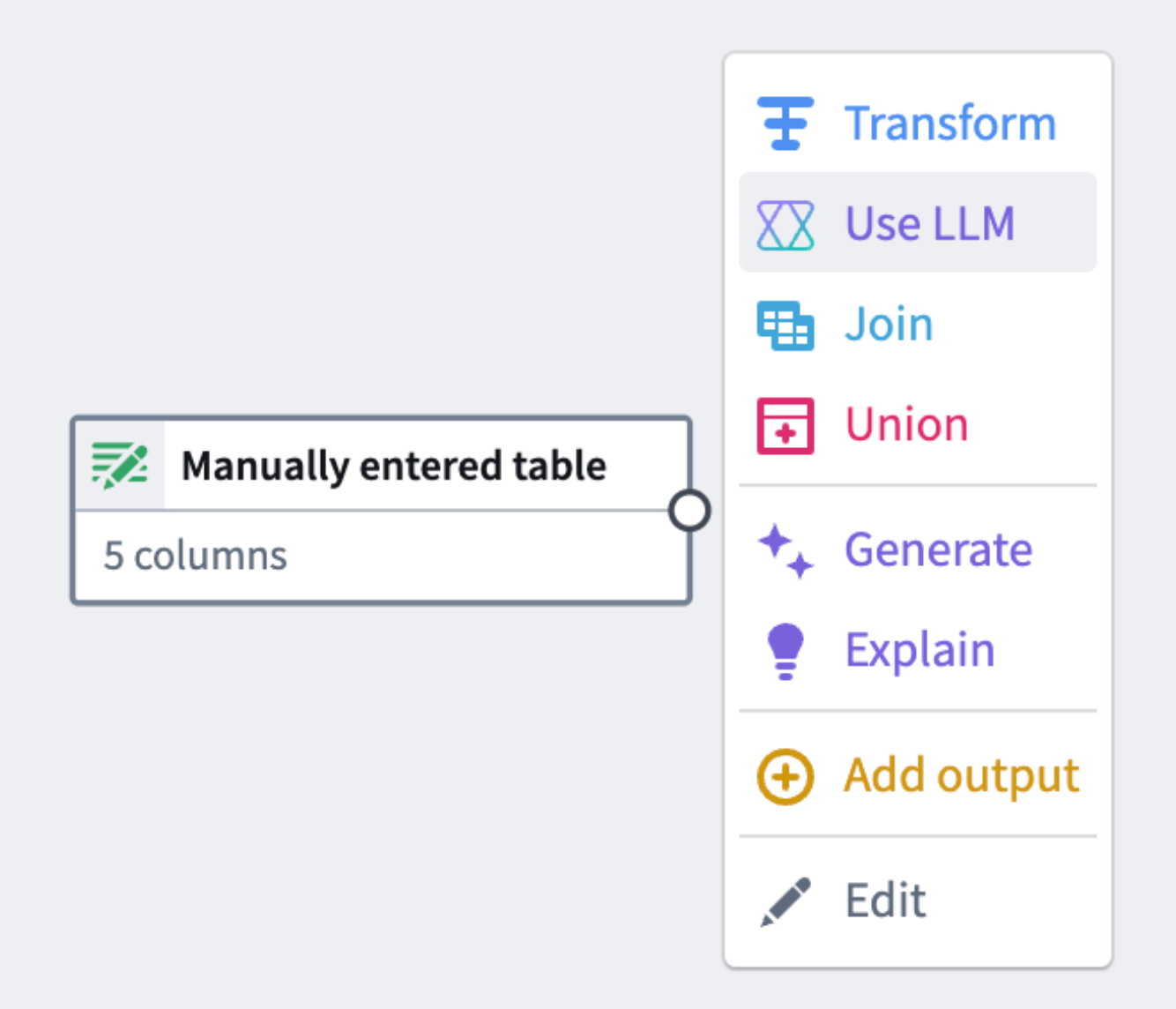
프롬프트 선택하기
아래에는 다섯 가지 템플릿 프롬프트 각각에 대한 다른 예시들이 있습니다. 직접 만들려면 빈 프롬프트를 선택하십시오.
분류
데이터를 다른 카테고리로 분류하고자 할 때 분류 프롬프트를 사용해야 합니다. 아래 예에서는 식당 리뷰를 서비스, 음식, 분위기라는 세 가지 카테고리로 분류하려고 합니다.
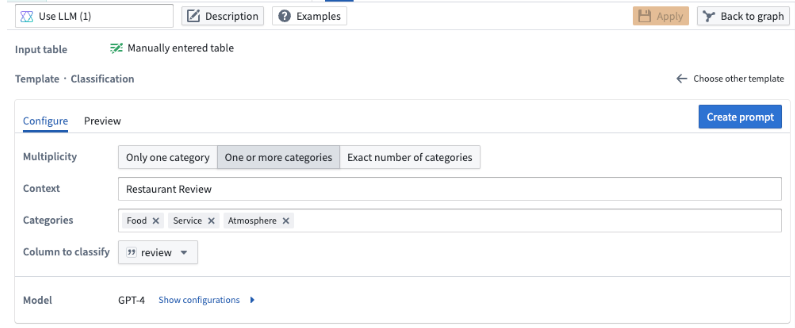
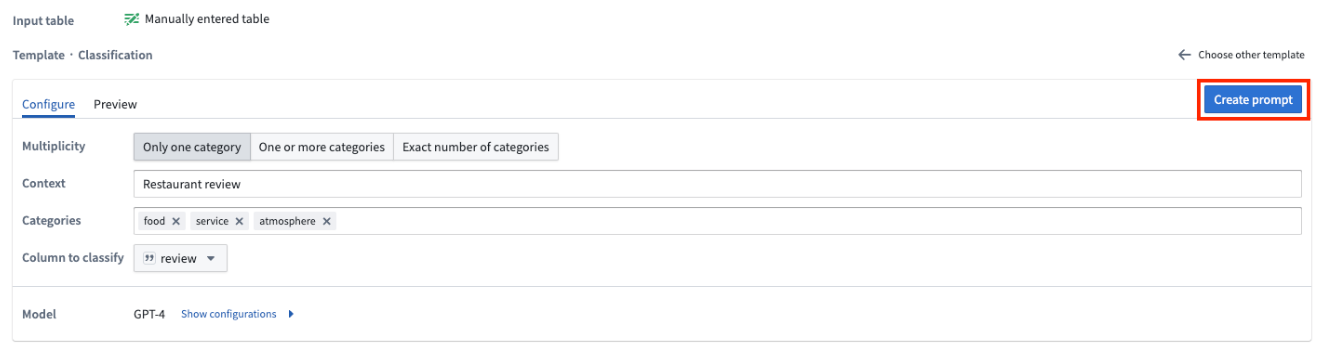
Multiplicity 필드를 사용하면 결과물 열에 한 개의 카테고리, 여러 개의 카테고리 또는 정확한 수의 카테고리를 포함시킬지 선택할 수 있습니다. 예시에서는 리뷰가 해당될 수 있는 모든 카테고리를 포함시키고자 하므로 하나 이상의 카테고리 옵션을 선택합니다.
Context 필드에 데이터에 대한 설명을 입력합니다. 예시에서는 식당 리뷰를 입력할 수 있습니다.
Categories 필드에 데이터를 할당하려는 고유 카테고리를 입력합니다. 예시에서는 식당 리뷰를 이 세 가지 카테고리 중 어느 것으로든 분류하려고 하므로 세 가지 카테고리인 음식, 서비스, 분위기를 지정합니다.
Column to classify 필드에서 분류하려는 데이터가 포함된 열을 선택합니다. 예시에서는 식당 리뷰가 포함된 열인 review 열을 선택합니다.
감정 분석
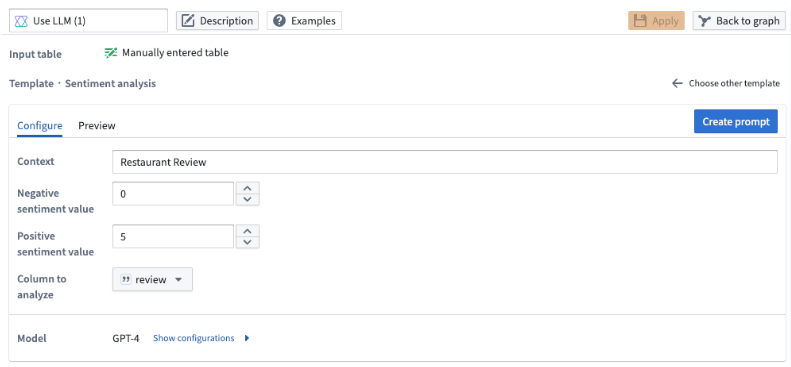
데이터에 긍정적이거나 부정적인 감정에 따라 숫자 점수를 할당하려는 경우 감정 분석 프롬프트를 사용합니다.
이 템플릿에서는 결과 점수의 범위를 설정할 수 있습니다. 아래 예시에서는 점수가 가장 긍정적인 리뷰를 5로, 가장 부정적인 리뷰를 0으로 나타내는 0에서 5까지의 숫자를 원합니다.
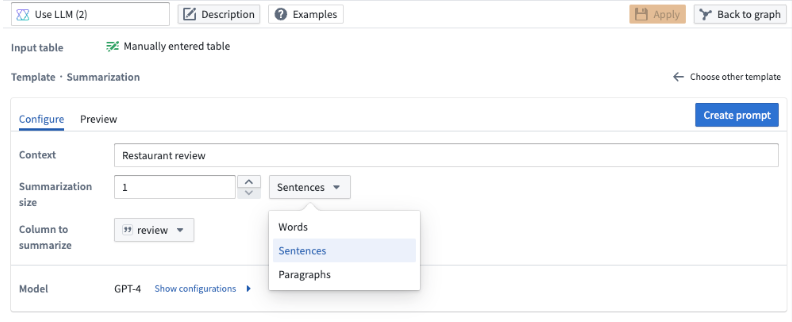
요약
데이터를 주어진 길이로 요약하려는 경우 요약 템플릿을 사용할 수 있습니다.
이 템플릿에서는 요약의 길이를 지정할 수 있습니다. 단어, 문장, 또는 문단의 수를 선택하고 Summarization size 필드에 크기를 지정할 수 있습니다.
예시에서는 식당 리뷰의 한 문장 요약을 원하므로 요약 크기로 1을 지정하고 드롭다운에서 Sentences를 선택합니다.
엔티티 추출
데이터에서 특정 요소를 추출하려는 경우 엔티티 추출 프롬프트를 사용합니다. 예시에서는 식당 리뷰에서 음식과 음료 관련 요소를 모두 추출하려고 합니다. 우리는 Entity types 필드에 음식과 음료를 모두 입력할 것입니다.
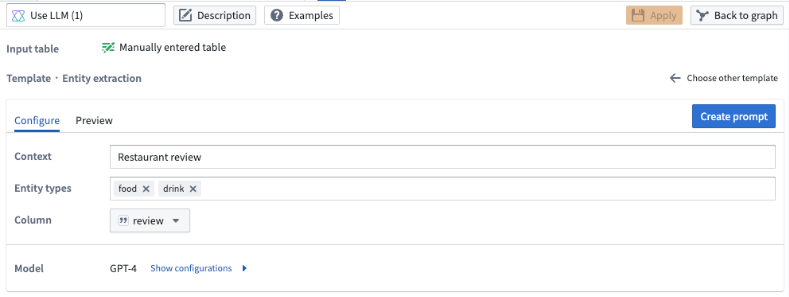
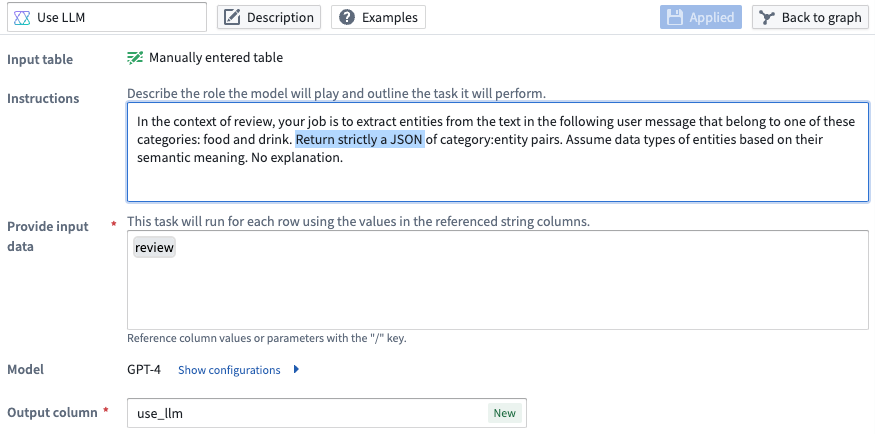
엔티티 추출의 결과물은 기본적으로 JSON으로 설정됩니다. 엔티티 일치가 없는 경우 결과물은 빈 JSON이 됩니다. 하지만 프롬프트를 생성한 후 Instructions 텍스트 상자를 편집함으로써 이를 재구성할 수 있습니다.
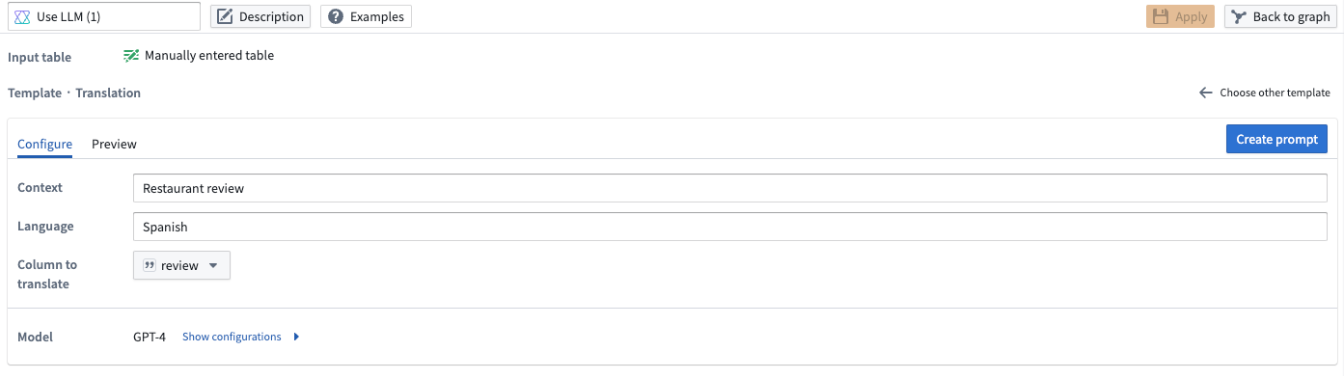
번역
데이터를 다른 언어로 번역하려면 번역 프롬프트를 사용합니다. Language 필드에서 데이터를 번역하려는 언어를 지정합니다. 아래 예시에서는 식당 리뷰를 스페인어로 번역하려고 하므로 Language 필드에 스페인어를 지정합니다.
빈 프롬프트
프롬프트 템플릿 중 어느 것도 유즈케이스에 맞지 않는 경우 빈 프롬프트를 선택하여 직접 생성할 수 있습니다.
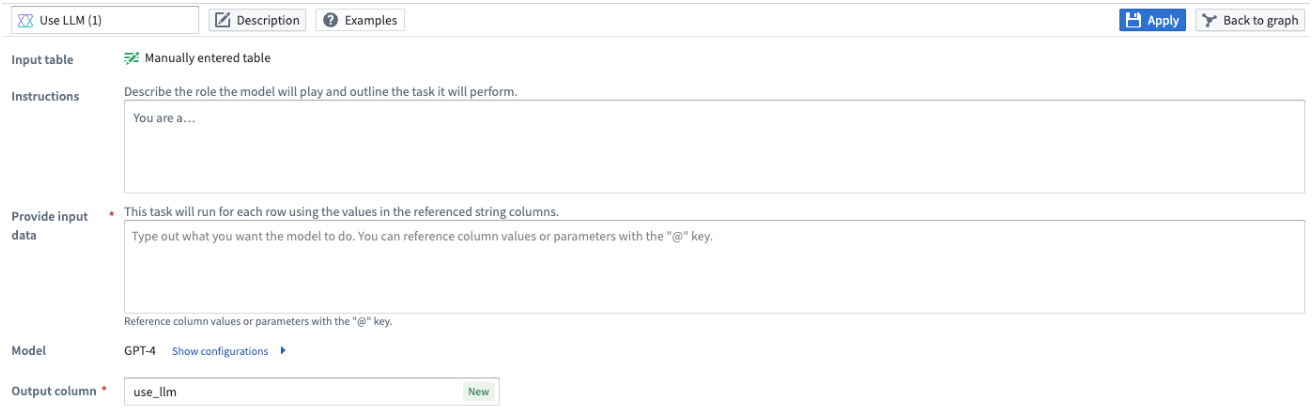
[고급] 모델에 대한 설정 표시하기
각 프롬프트에 대해 사용하는 LLM 노드의 모델을 설정할 수 있습니다. 설정 옵션은 다음과 같습니다:
- Model Type: GPT 인스턴스의 모델 유형, 예를 들어
3.5또는4. LLM 노드는 Mistral AI의 Mixtral 8x7b와 같은 오픈 소스 모델도 지원합니다. - Temperature: 더 높은 값의 온도는 결과물을 더 무작위로 만들며, 더 낮은 값은 그것을 더 집중적이고 결정론적으로 만듭니다.
- Max Tokens: 이것은 결과물의 토큰 수를 제한합니다. 토큰을 언어 모델이 쓰기 언어를 이해하고 처리하는 데 사용하는 작은 텍스트 조각으로 생각할 수 있습니다.
- Stop Sequence: 이것은 어떤 정지 시퀀스 값에 도달하면 LLM 생성을 중단하게 합니다. 최대 네 개의 정지 시퀀스를 설정할 수 있습니다.
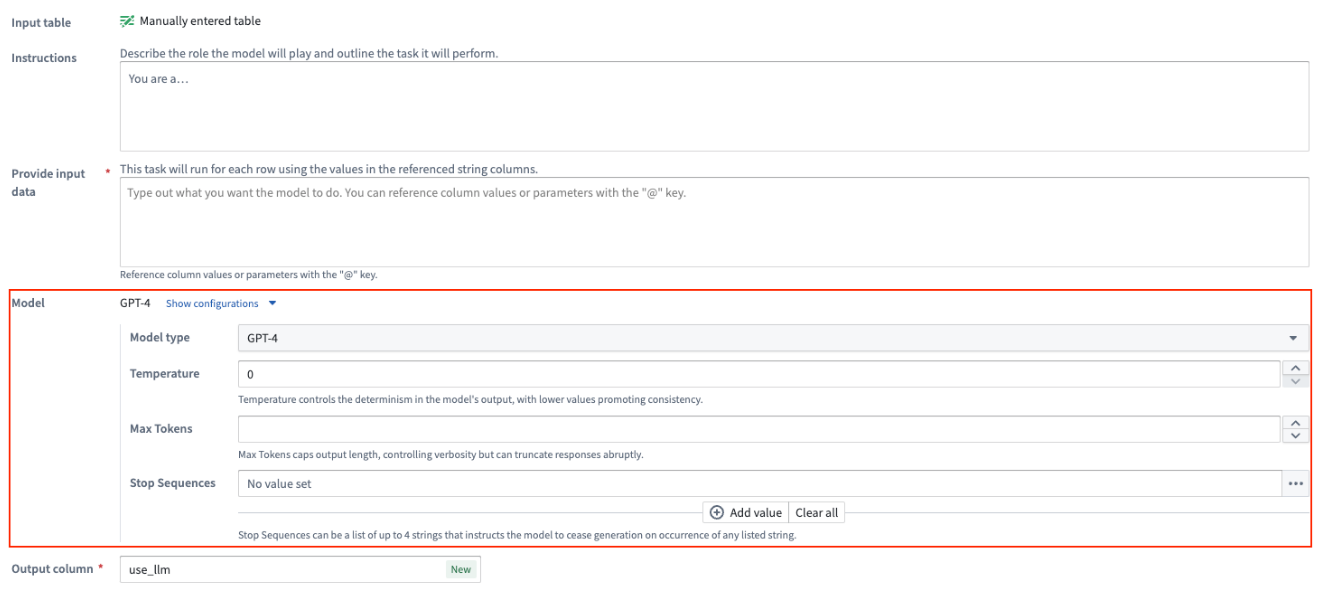
시험 실행
각 LLM 보드의 하단에는 특정 LLM을 예시로 테스트하는 옵션이 있습니다. Trial run 탭을 선택하고 왼쪽에 테스트하려는 값을 입력한 다음 Run을 선택합니다.

더 많은 예를 테스트하려면 시험 실행 추가를 선택할 수 있습니다.
입력 데이터에서 직접 예를 추가하려면 Input table 탭으로 이동하고 시험 실행에 사용하려는 행을 선택합니다. 시험 실행을 위한 행 사용을 선택하면 선택한 행이 시험 실행으로 채워진 상태로 Trial run tab으로 자동으로 돌아갑니다.
미리보기 및 생성
다섯 가지 템플릿 중 하나를 사용하는 경우 프롬프트를 생성하기 전에 Preview 탭을 선택하여 LLM 프롬프트 지침을 미리 볼 수 있습니다. Preview 탭에서는 지침을 보기만 할 수 있고 편집할 수는 없습니다. 템플릿을 편집하려면 Configure 탭으로 돌아가야 합니다.
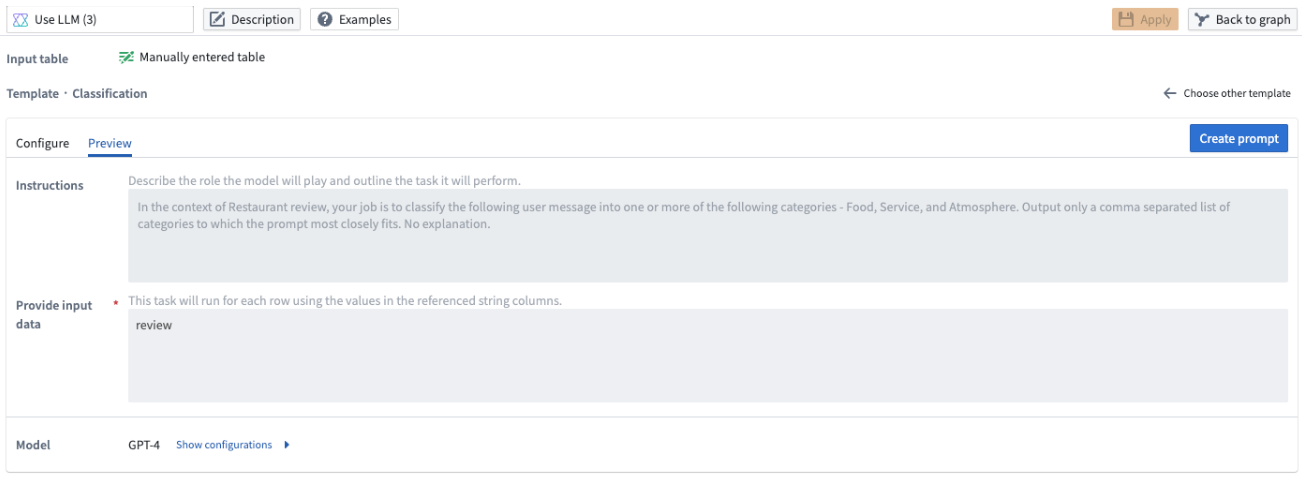
새로운 결과 열의 이름을 편집하고 Output column에서 결과를 미리 보려면 프롬프트 생성을 선택해야 합니다.
프롬프트 생성을 선택하면 해당 보드의 템플릿으로 돌아갈 수 없게 됩니다.
결과 열 이름을 변경하려면 Output column 섹션을 편집합니다. 출력 테이블 미리보기에 변경 사항을 적용하려면 Applied를 선택합니다. 출력 테이블을 미리 보려면 Output table 탭을 선택합니다. 이 미리보기는 처음 50행만 보여줍니다.
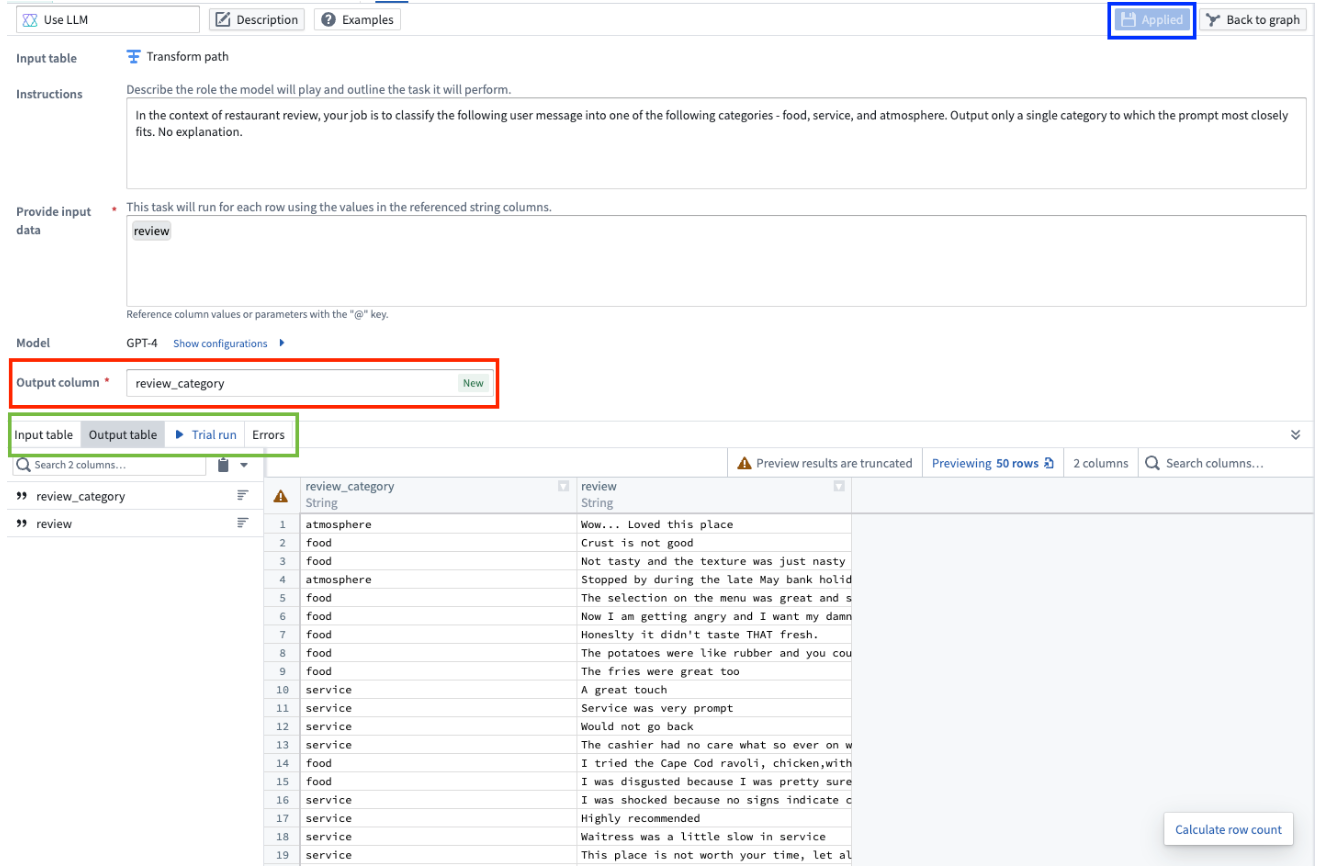
마지막으로, LLM 노드 설정을 마친 후에는 상단 오른쪽에 있는 Apply를 선택할 수 있습니다(아직 선택하지 않았다면). 이제 LLM 보드의 결과에 변환 로직을 추가할 수 있게 되며, 메인 Pipeline Builder 작업 공간에서 LLM 보드를 선택하면 처음 50행의 미리보기를 볼 수 있습니다.