파이프라인 미리보기
미리보기 패널은 파이프라인의 단일 선택된 노드에 대한 로직과 열 통계를 미리 볼 수 있게 해줍니다. 노드를 선택하고 미리보기를 클릭하여 파이프라인을 실행하세요. 이렇게 하면 미리보기 패널이 열리고 원시 데이터셋에서 선택한 노드까지의 로직을 실행합니다.
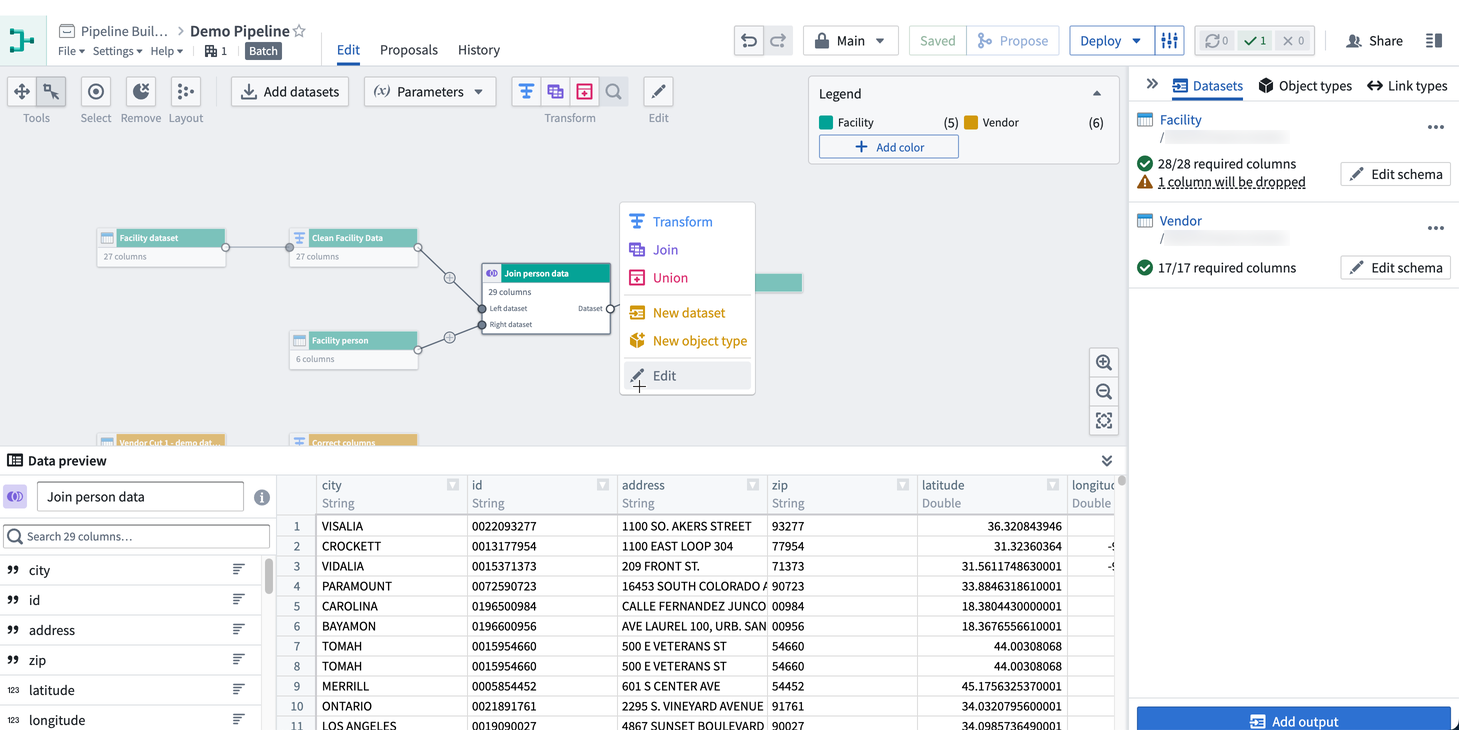
또한 그래프 오른쪽 하단의 아이콘을 클릭하여 미리보기 패널을 확장할 수 있습니다. 그런 다음 노드를 클릭하여 데이터를 미리 봅니다.
통계를 보려면 열 위에서 마우스 오른쪽 버튼을 클릭하고 통계 보기를 클릭합니다.
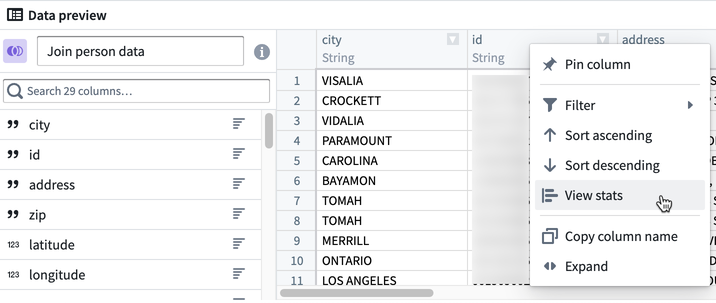
스트링 열의 경우 통계 보기에 값과 값 길이의 히스토그램, 스트링 케이싱, 공백 및 널 인스턴스의 개수가 포함됩니다. 숫자 열의 경우 값의 분포가 표시되며 최소값, 최대값, 평균, 표준 편차 및 고유한 값 개수와 같은 기본 통계가 표시됩니다.
행 개수를 보려면 미리보기 패널 오른쪽 하단에서 행 개수 계산을 선택합니다.
미리보기 행 개수
기본적으로 Pipeline Builder는 미리보기 테이블에서 최대 500행까지 처리합니다. 이 구현은 데이터셋에서 500개의 입력 행만 필요할 수 있지만, 필터, 조인 및 중복 제거와 같은 많은 작업은 500행의 미리보기를 생성하는 데 추가 행이 필요할 수 있습니다.
미리보기를 빠르게 하려면 입력 샘플링 전략 추가를 사용하여 미리보기 계산에 사용 가능한 입력 행 수를 제한합니다. 입력 샘플링 전략은 미리보기에만 영향을 주고 빌드에는 영향을 주지 않습니다.
행 개수와 통계 계산은 샘플링된 입력을 통해 실행됩니다. 이는 전체 데이터셋이 사용되면 행 개수와 통계가 전체 빌드와 일치하게 되지만, 샘플링 전략이 입력 데이터셋의 일부만 사용하도록 설정된 경우 행 개수와 통계는 이 샘플에 대해서만 계산됩니다.
예를 들어 입력 데이터셋에 600행이 있다고 가정해 봅시다.
| id | value |
|---|---|
| 1 | row_1 |
| 2 | row_2 |
| ... | ... |
| 600 | row_600 |
미리보기는 500행으로 제한됩니다. 이들은 반드시 입력의 처음 500행일 필요는 없습니다.
| id | value |
|---|---|
| 1 | row_1 |
| 2 | row_2 |
| ... | ... |
| 500 | row_500 |
입력 전략을 작은 백분율로 설정한 후 입력이 작은 샘플로 제한되어 미리보기 계산이 빨라집니다. 미리보기에 단지 여섯 행이 남았다고 가정해 봅시다.
| id | value |
|---|---|
| 1 | row_1 |
| 12 | row_12 |
| 33 | row_33 |
| 62 | row_62 |
| 126 | row_126 |
| 527 | row_527 |
그런 다음 상수 열 hello에 값 world를 추가하는 변환을 사용하면 미리보기에 샘플링된 여섯 행에 대해 계산된 변환을 표시합니다.
| id | value | hello |
|---|---|---|
| 1 | row_1 | world |
| 12 | row_12 | world |
| 33 | row_33 | world |
| 62 | row_62 | world |
| 126 | row_126 | world |
| 527 | row_527 | world |
행 개수를 계산하면 여섯 행이 반환되며, 통계는 이 여섯 행에 대해서만 계산됩니다.
최종적으로 파이프라인을 빌드할 때 샘플링 전략은 영향을 주지 않고 전체 600개의 입력 행에 대해 변환을 계산합니다.