Pipeline 전달
Pipeline Builder에서 Pipeline을 설명하고 스키마 오류를 해결하면, Pipeline을 전달할 준비가 끝납니다.
배포 vs. 빌드
배포는 Pipeline 결과물의 로직을 업데이트하고, 빌드는 해당 로직을 실행하여 로직 변경사항을 구체화합니다.
빌드는 시간과 리소스가 많이 소모되는 작업이며, 데이터 규모가 크거나 Pipeline 입력의 전체를 재처리하는 경우 특히 그렇습니다. 이러한 이유와 기타 이유로 인해, 빌드 없이 Pipeline을 배포하기로 선택할 수 있습니다. 배포만 선택하면, 빌드가 필요할 때까지 빌드 비용을 연기할 수 있습니다.
변경사항 전달
첫 번째 end-to-end Pipeline을 전달하고 모든 정의된 로직을 포함하려면, 상단 도구 모음 오른쪽에 있는 Deploy를 선택합니다.

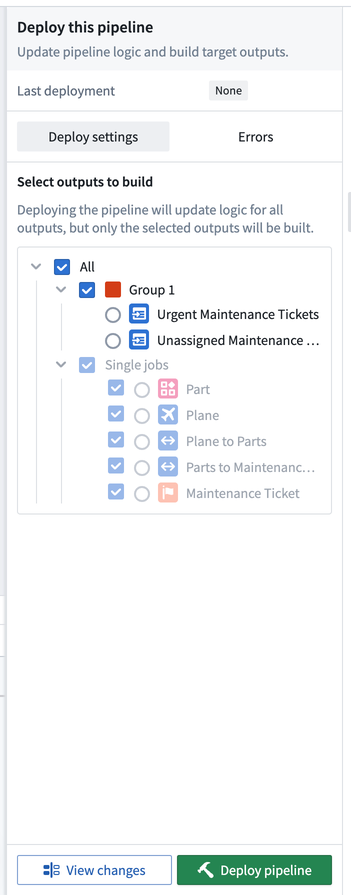
로직 변경사항이 배포된 후 어떤 결과물을 빌드할지 선택할 수 있습니다. 빌드는 작업 그룹 당 수행되며, 따라서 주어진 작업 그룹 내에서 모든 결과물을 빌드하거나 그룹화되지 않은 개별 결과물을 빌드할 수 있습니다. 온톨로지 유형의 결과물은 항상 빌드해야 하며, 즉 온톨로지 유형의 결과물이 있는 모든 작업 그룹은 빌드해야 합니다.
배포를 성공적으로 시작하면, 그래프 상단에 파란색 배너가 나타납니다. Build details 화면에 접근하려면 View를 선택합니다.

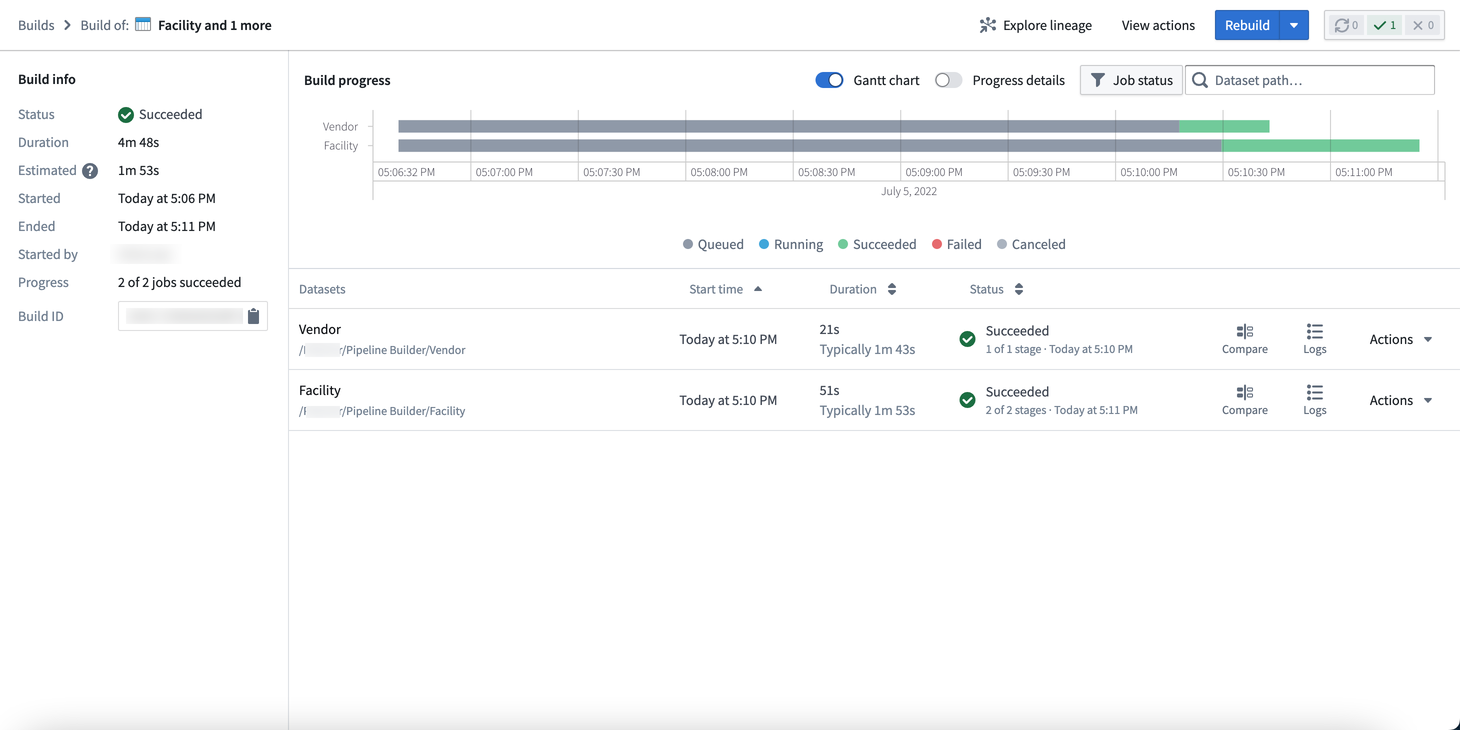
Build details 화면에서는 빌드 정보, 진행 측정치, 빌드 일정 상세를 찾을 수 있습니다.
-
빌드 정보: Pipeline의 상태, 총 시간, 예상 시간을 보여줍니다. 또한 시작 및 종료 시간, 시작 사용자, 작업 목록 내 진행 상태, 빌드 ID 등 다양한 메타데이터를 볼 수 있습니다.
-
빌드 진행: Gantt 차트로 Pipeline 빌드의 시간 경과에 따른 상세를 표시합니다.
-
빌드 일정: Pipeline 빌드 일정의 이름, 빈도, 상태 기록, 마지막 수정 날짜를 표시합니다.
- 빌드 일정 생성에 대해 더 알아보기.
-
진행 상세: 빌드 시작, 프로젝트의 리소스 대기열에서 대기, Spark 애플리케이션 초기화, 실행, 또는 완료 여부를 확인할 수 있습니다.
빌드 설정
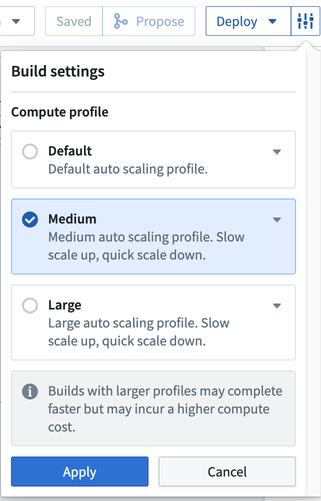
Pipeline의 빌드 설정을 편집하려면 Deploy 옆에 있는 설정 아이콘을 클릭하여 선택할 수 있습니다. 다음 컴퓨팅 설정 중에서 선택합니다:
- 기본: 기본 자동 스케일링 프로필. 실행기 코어와 메모리를 가장 적게 사용합니다.
- 중간: 천천히 스케일 업하고 빠르게 스케일 다운하는 컴퓨팅을 제공합니다.
- 큰: 천천히 스케일 업하고 빠르게 스케일 다운하는 컴퓨팅을 제공합니다.
- 참고: 더 큰 프로필로 빌드하면 더 빨리 완료될 수 있지만 컴퓨팅 비용이 더 높을 수 있습니다.
저장하기
Pipeline Builder에서는 배포를 시작하지 않고도 Pipeline에 대한 변경사항을 저장할 수 있습니다. 이런 유연성으로 인해 워크플로를 편집하면서 생산 로직 변경사항을 커밋할 필요가 없습니다.
워크플로에 변경사항을 만든 후에는, 상단 도구 모음에서 저장하기를 선택합니다.

Propose를 먼저 클릭하면, 현재 상태가 자동으로 저장됩니다.
변경사항을 저장만 하고 배포하지 않으면, Pipeline 로직은 최신 변경사항으로 업데이트되지 않습니다. 변환 로직의 변경사항을 캡처하려면 Pipeline을 배포해야 합니다.
결과 노드에서 빌드하기
Pipeline 그래프 외부로 이동했을 때도 Pipeline 빌드를 시작할 수 있습니다. 예를 들어, 결과 노드를 마우스 오른쪽 버튼으로 클릭하고 Open을 선택하여 데이터셋 미리보기를 열 수 있습니다. 그런 다음, 인터페이스 오른쪽 상단에 있는 빌드를 클릭하여 빌드를 시작할 수 있습니다.
Pipeline 그래프 외부의 빌드 옵션은 마지막 배포 이후에 이루어진 변경사항을 사용하여 Pipeline 로직을 업데이트하지 않습니다. 로직을 업데이트하고 결과물에 푸시하려면, Pipeline 그래프로 돌아가서 Deploy를 사용해야 합니다.
스트리밍 Pipeline에 대한 추가 옵션
스트리밍 Pipeline을 실행하는 경우, 추가 옵션이 제공됩니다. 스트리밍 Pipeline은 일부 계정에서만 사용 가능합니다. 자세한 정보는 Palantir 담당자에게 문의하십시오.
필요한 경우 Replay on deploy를 사용하여 Pipeline이 특정 과거 시점부터 계산을 시작하도록 지시할 수 있습니다.
Deploy 창에서, Pipeline 전달에서 데이터 처리의 시작 시간을 선택합니다:
- Start of input data: 입력 스트림의 시작부터 모든 데이터가 처리됩니다.
- From a specified time: 데이터 처리를 시작할 시간 값을 선택합니다. 이 시간 이전의 데이터는 처리되지 않습니다. 예를 들어, 지난 두 달 동안의 데이터만 포함하려면
2 monthsago을 선택합니다.
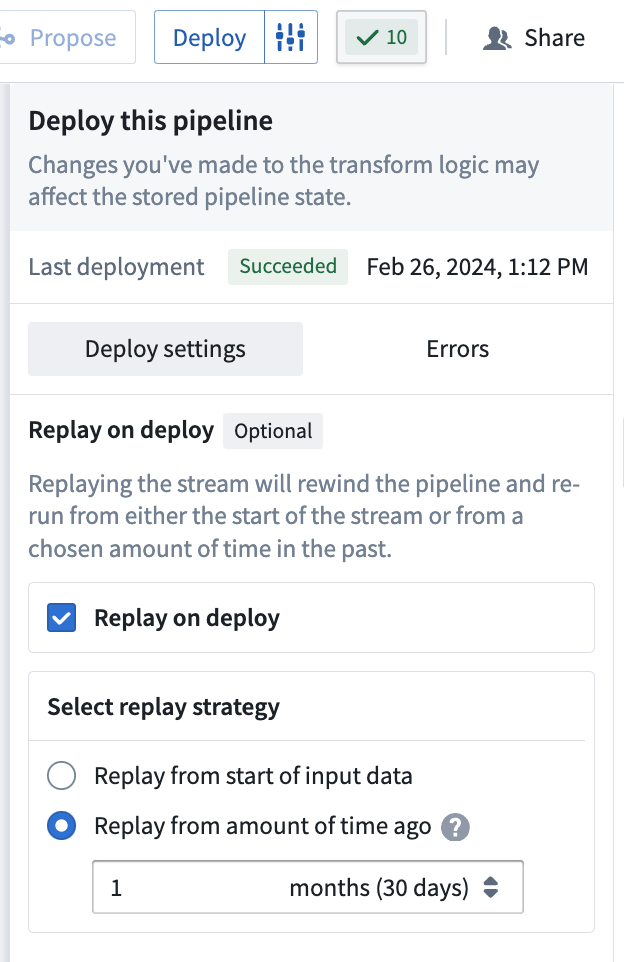
Pipeline을 다시 재생하면 여러 일 동안 길게 중단될 수 있습니다. Pipeline을 다시 재생하면 스트림 기록이 사라지고 모든 하위 Pipeline 사용자는 다시 재생해야 합니다.
재생에 대한 자세한 정보는 breaking changes 문서를 참조하십시오.
재배포 vs. 재생
스트림 재배포는 이전에 저장된 체크포인트에서 스트리밍 작업을 재개하는 과정을 가리킵니다. 스트리밍 작업이 일시 중지되거나 중지되면, 데이터 내에 북마크가 생성되어 읽은 레코드의 위치를 표시합니다. 북마크, 또는 체크포인트라고도 하는 이것은 스트림이 실행 중일 때도 주기적으로 생성됩니다. 이를 통해 스트림이 어떤 이유로 실패했을 경우 복구가 가능합니다.
이렇게 하면, 스트림이 다시 시작될 때 특정 체크포인트에서 처리를 재개할 수 있습니다. 재배포 중에는 기존 출력 스트림이 보존되고, 새로운 데이터가 추가됩니다.
반면에, 스트림 재생은 출력 스트림의 새로운 뷰를 생성하는 것을 의미합니다. 데이터셋에 대한 새로운 뷰를 설정하는 것은 새로운 데이터를 포함하는 새 스트림으로 간주되지만, 이전 뷰에서 데이터에 접근하는 것은 여전히 가능합니다. 다음과 같은 여러 상황에서 스트림 재생이 필요하거나 장점을 제공할 수 있습니다:
- Pipeline Builder의 Pipeline에서 로직을 수정하고 출력 데이터가 업데이트된 로직을 준수하도록 요구하는 경우, 스트림을 재생하여 이를 촉진할 수 있습니다. 이는 시작부터 또는 지정된 시점부터 처리를 다시 시작하여 출력 스트림의 데이터가 업데이트된 변환 규칙과 일치하도록 합니다.
- breaking changes의 경우, 재생이 강제됩니다. 자세한 내용은 breaking changes 문서에서 찾을 수 있습니다.
- Pipeline에서 입력 스트림이 재생된 경우, 출력 스트림의 데이터 일관성을 유지하기 위해 하위 스트림 Pipeline도 재생해야 합니다.
Pipeline을 재생하면 몇 일 동안 긴 다운타임이 발생할 수 있으며, 재생 시작점에 따라 이 시간이 더 길어질 수 있습니다. Pipeline을 재생하면 출력 스트림의 모든 데이터가 사라집니다. 이전 스트림의 데이터를 유지하려면 출력을 새로운 목적지로 지정할 수 있습니다. 그러나 앞으로 원래 출력 스트림에 레코드를 푸시하려면 Pipeline을 재생해야 합니다.
스트림을 재배포하려면, 초기 배포에 사용한 동일한 절차를 따르며, Pipeline Builder 인터페이스에서 Deploy를 선택합니다.
스트림을 재생하려면, Start of input data 또는 From a specified time에서 재생할 추가 설정을 추가합니다.