Spark 세부 사항 이해하기
Apache Spark는 Foundry의 데이터 통합 계층에서 가장 일반적으로 사용되는 실행 엔진입니다. 파이프라인의 성능 특성을 이해하고 파이프라인을 최적화할 수 있는 방법을 찾으려면 Spark에서 코드가 어떻게 실행되는지에 대한 세부 사항을 이해해야 합니다. Foundry는 Spark에서 작업 성능을 보고 이해하는 데 도움이 되는 통합 도구를 제공합니다. 이 페이지에서는 사용 가능한 Spark 세부 사항을 설명하고 이러한 세부 사항이 무엇을 의미하는지에 대한 가이드를 제공합니다.
Spark 세부 사항으로 이동하기
Foundry에서 생성된 모든 데이터셋에 대해 Spark 세부 사항을 보려면 다음 단계를 따르십시오.
- 빌드 보고서 보기.
- 작업 선택. 빌드는 하나 이상의 작업으로 구성되며, 간트 차트 아래 목록에 표시됩니다. 목록에서 작업을 선택한 다음 Spark 세부 사항 버튼을 선택합니다:

Spark 세부 사항 페이지는 Spark에서 작업 실행과 관련된 정보를 제공합니다. 각 작업에 대해 Spark 세부 사항 페이지는 아래에 표시된 것처럼 다양한 카테고리의 정보를 표시합니다:

개요 탭
개요 탭에서는 작업에 대한 다음 정보를 제공합니다:
하이레벨 작업 지표
- 모든 작업에 걸친 전체 런타임: 모든 단계의 모든 작업의 런타임 합계
- 작업 지속 시간: Spark 계산의 지속 시간(첫 번째 단계 시작과 마지막 단계 완료 사이의 시간)
이 두 가지 지표를 사용하여 병렬 비율을 다음과 같이 계산할 수 있습니다.
모든 작업의 전체 런타임 / 작업 지속 시간
비율이 1에 가까울수록 병렬성이 떨어집니다.
-
디스크 스피릴: 모든 단계에 걸친 실행자의 RAM에서 디스크로 이동한 데이터 크기입니다.
- 이는 데이터가 실행자의 메모리에 맞지 않을 때 발생합니다. 디스크 쓰기 및 읽기는 느린 작업이므로 작업이 스피릴되면 상당히 느려집니다. 때때로, 계산 유형에 따라 스피릴링이 실행자가 메모리 부족으로 작업이 실패하는 원인이 될 수 있습니다.
- 큰 데이터셋의 경우 디스크 스피릴이 예상됩니다.
-
셔플 쓰기: 작업 중에 모든 단계에서 셔플된 데이터 양입니다.
- 셔플링은 데이터가 Spark 단계와 파티션 간에 이동되는 과정입니다. 예를 들어, 조인을 계산할 때(테이블이 브로드캐스트되지 않은 경우), 집계를 수행하거나 재분할을 적용합니다.
- 셔플링은 네트워크 IO와 디스크 IO를 모두 이끌어내므로 작업 런타임의 큰 부분을 차지할 수 있습니다.
- 따라서 성능이 뛰어난 Spark 작업을 작성하는 주요 목표는 셔플링을 최소화하는 것입니다. 예를 들어, 브로드캐스트 될 수 있는 조인이 실제로 브로드캐스트되도록 보장하거나, 종속 작업에서 동일한 키로 자주 조인되거나 집계되는 데이터셋에 대해 버킷을 활용합니다(이 데이터셋에 대한 종속 셔플링을 방지하기 위해) 또는 불필요한 재분할 단계를 피합니다.
단계 실행 타임라인 및 단계 간 종속성
작업 시작 시, Spark는 변환 코드를 해석하여 실행 계획을 생성하며, 이는 종속성이 있는 일련의 단계로 표현할 수 있습니다. 다음 그래프는 단계의 실행 타임라인을 보여줍니다.
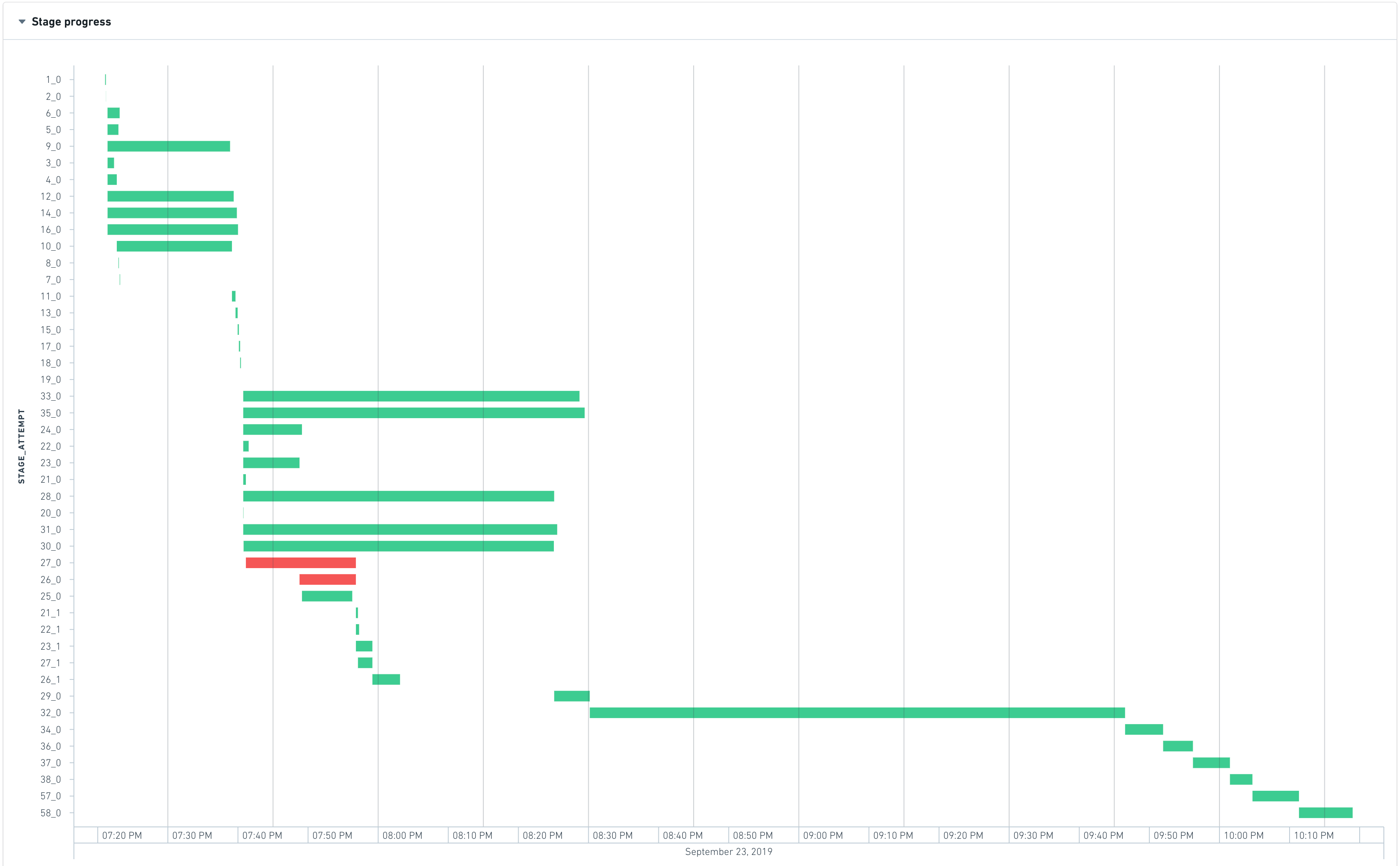
가장 왼쪽의 단계는 일반적으로 입력값을 불러오는 것을 나타내며, 가장 오른쪽의 단계는 일반적으로 결과물을 작성하는 것을 나타냅니다. 위의 예에서 단계 28, 30, 31, 32, 33, 35는 실행하는 데 오랜 시간이 걸리므로 이 작업의 런타임을 최적화하기 위한 좋은 후보입니다.
단계 28, 30, 31, 33, 35는 병렬로 실행할 수 있으므로 서로 종속성이 없습니다. 그러나 단계 32는 이전 단계가 모두 완료될 때만 시작되므로:
- 단계 35의 런타임을 줄이는 것은 대기 시간이 max_runtime(28, 30, 31, 33, 35)에 의해 지배되기 때문에 큰 개선을 이루지 못합니다. 눈에 띄게 개선하려면 이러한 모든 단계가 가속화되어야 합니다.
- 단계 32는 작업의 병목 구간이며 전체 작업 지속 시간의 약 35%를 차지합니다.
작업 동시성 차트
작업 동시성 차트는 리소스 사용이 얼마나 잘 이루어지는지 이해하는 데 도움이 됩니다. 시간에 따른 단계 동시성을 플롯합니다. 작업 동시성과 유사하게, 단계 동시성은 다음과 같이 계산할 수 있습니다.
단계 내 작업의 총 런타임 / 단계 지속 시간
작업 동시성 차트의 시간 축은 위의 간트 차트와 공유되어 상관 관계를 쉽게 식별할 수 있습니다.

위 차트에서 단계 32는 거의 1의 동시성을 가지고 있습니다. 이는 이 단계에서 수행되는 작업이 거의 한 개(매우 긴) 작업에서 일어난다는 것을 의미하며, 이는 계산이 분산되지 않았음을 나타냅니다.
완벽하게 분산된 작업은 다음과 같습니다:

단계 세부 사항
특정 단계가 실패하거나 느린 이유를 이해하려면 더 많은 정보가 필요할 수 있습니다. 불행히도 원본 코드 또는 실제 계획으로 돌아가 단계가 수행하는 작업을 자동으로 추적하는 것은 현재 불가능합니다. 왜냐하면 Spark는 코드를 단계로 변환할 때 이 리니지를 노출하지 않기 때문입니다.
단계 개요는 실패하거나 오래 실행되는 단계에 대한 조사를 계속할 수 있습니다:

작업의 절반은 2초 미만이지만, 더 흥미로운 것은 최대 런타임입니다. 한 작업은 전체 단계 런타임의 약 63%를 차지하는 데 걸립니다. 이는 이전 차트에서 이 단계가 병목 구간이며 거의 모든 작업이 한 작업에서 발생한다는 관찰과 일치합니다.
더 자세히 알아보려면 단계 세부 사항으로 이동할 수 있습니다:
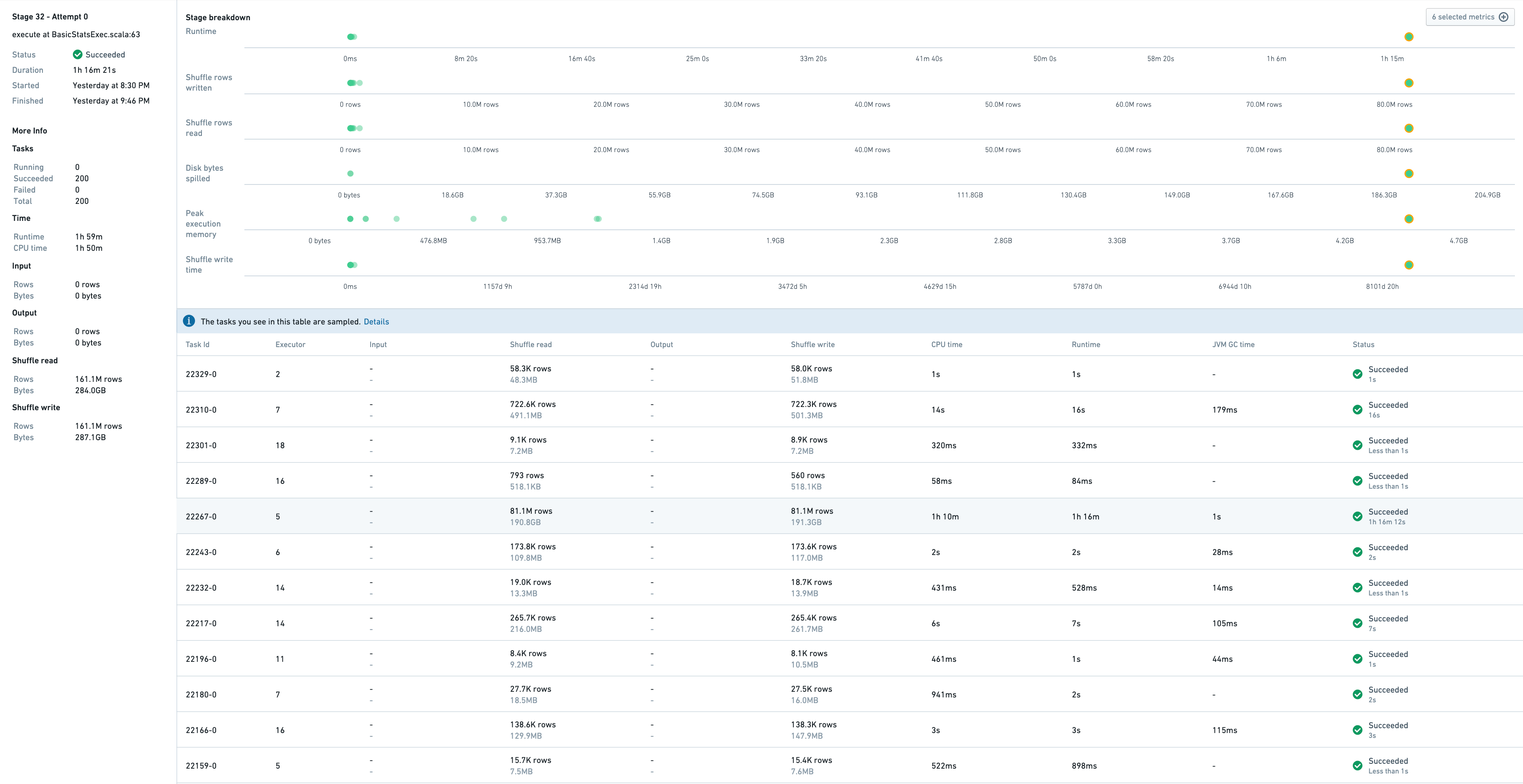
이는 이 단계에서 실행된 작업 샘플과 단계 자체와 관련된 지표를 보여줍니다.
작업 22267-0은 1시간 16분이 걸려 가장 느립니다. 실제로 이 작업은 81M 행을 처리하는 반면 다른 작업은 10K-700K 행을 처리합니다. 이 왜곡의 증상은 다음과 같습니다.
- 높은 디스크 스피릴: 190GB vs 다른 작업의 0
- 높은 실행자 최대 메모리: 4.5GB vs 다른 작업의 1GB
Executors 탭

Executors 탭은 Spark 작업의 드라이버 또는 실행자에서 특정 지표를 캡처하며, 스택 추적 및 메모리 히스토그램을 포함합니다. 이러한 지표는 Spark 작업의 성능 문제를 디버깅할 때 유용합니다.
스냅샷 버튼을 선택하면 실행 중인 작업에서 Java 스택 추적 또는 드라이버 전용 메모리 히스토그램을 캡처합니다. 작업이 실행 상태에 있어야 합니다(작업이 완료된 경우 이러한 지표를 더 이상 수집할 수 없음).
스택 추적은 Spark 작업의 각 스레드가 해당 시점에 실행하는 내용을 확인하는 방법입니다. 예를 들어, 작업이 정체되어 있다고 생각되는 경우(즉, 예상할 때 진행되지 않음) 스택 추적을 취하면 해당 시간에 실행되는 내용을 알 수 있습니다.
메모리 히스토그램은 현재 힙에 있는 Java 객체의 수와 메모리 크기(바이트)를 보여줍니다. 메모리 사용 방식을 이해하고 메모리 관련 문제를 디버깅할 때 유용합니다.
지표를 취하는 것이 실행 중인 작업의 성능에 영향을 줄 수 있다는 점에 유의하십시오. 이러한 지표를 수집하는 것은 JVM이 수행해야 하는 추가 작업입니다. 예를 들어, 메모리 히스토그램을 취하면 가비지 수집이 발생합니다.