29 - 추가적인 백킹 데이터셋 변경: Part 1
이 내용은 learn.palantir.com ↗에서도 확인할 수 있으며, 접근성을 위해 여기에 제공됩니다.
📖 작업 소개
이 연습에서는 백킹 데이터셋과 온톨로지 설정에 관한 두 가지 주요 시나리오를 다루는 연습을 진행합니다.
- 백킹 데이터셋에 추가적인 변경이 발생한 경우
- 백킹 데이터셋에 파괴적인 변경이 발생한 경우
승객 오브젝트 유형에 대한 제목 키는 단순히 승객의 성입니다. 백킹 데이터셋에 full_name이라는 새로운 열을 생성하고, 이를 제목 키로 바꿔보겠습니다. 이 과정을 통해 백킹 데이터셋이 새로운 열을 받게 될 때 온톨로지 동기화 과정에서 어떤 일이 발생하는지 확인할 수 있습니다.
🔨 작업 지시사항
-
ontology_flight_alerts_logic저장소에서passengers.py변환 파일을 엽니다.- ⚠️ *이런 변경을 할 때는 일반적으로
master에서 브랜치를 만들고 싶을 것입니다. 하지만 편의상 이번에는master에 직접 변경 사항을 반영하게 됩니다.
- ⚠️ *이런 변경을 할 때는 일반적으로
-
1행의 주석을 해제하여 pyspark.sql 함수를 가져올 수 있게 합니다.
-
반환 문을 다음과 같이 업데이트합니다:
return source_df.withColumn('full_name', F.concat(source_df.first_name, F.lit(' '), source_df.last_name)) -
가장 좋은 방법을 사용하여 코드를 미리보기, 커밋, 빌드합니다.
-
데이터셋 빌드가 완료되면, 출력
passengers데이터셋을 열고 아래 이미지에 보이는 것처럼 Details 탭의 Syncs 섹션으로 이동합니다. 여기서는 데이터셋과 오브젝트 저장 서비스(즉, "Phonograph")간의 동기화가 스키마 변경에도 불구하고 성공적이었음을 확인할 수 있습니다.
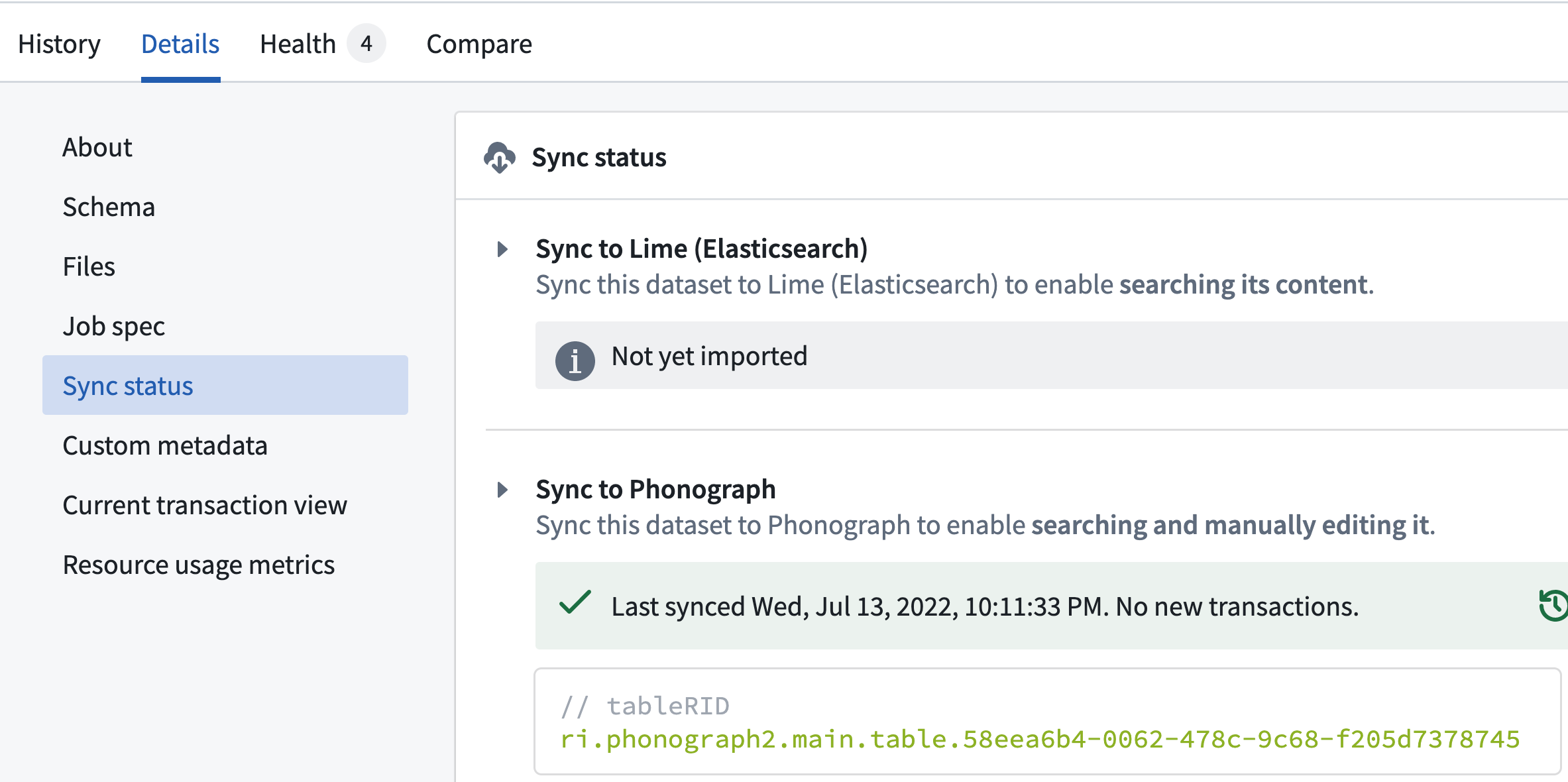
- 여기에서 Health 탭에 접근하면 이전에 설정한 Schema Check가 통과했음을 확인할 수 있습니다. 우리가 체크를
COLUMN_ADDITIONS_ALLOWED_STRICT로 설정했기 때문에, 체크는 새 열을 추가했습니다.