12 - 파이프라인 문서화 및 업데이트
이 내용은 learn.palantir.com ↗에서도 확인할 수 있으며, 접근성을 위해 여기에 제시되었습니다.
📖 작업 소개
왜 Ontology에 입력으로 사용하기 위해 수정하지 않은 데이터셋의 clean 버전을 그냥 사용하지 않았을까요?
Clean 데이터셋은 Foundry에서 많은 활동의 시작점이 되는 경향이 있습니다. 이에는 분석, 모델링, 그리고 기타 데이터 파이프라인이 포함됩니다. 일반적으로 raw 데이터에 가깝게 나타나므로 Ontology 오브젝트와 링크 유형에 필요한 것보다 훨씬 많은 열을 포함할 수 있지만, 이는 다른 워크플로에 있어서는 귀중한 자산입니다. 우리는 결국 Ontology를 지원하는 데이터셋에 새로 파생된 열을 추가하기로 결정할 수도 있고, 이러한 변경 사항을 clean 버전에 영향을 주지 않고 싶을 수 있습니다. 이 중간 변환 단계(clean → ontology)는 초기에 형식적으로 보일지라도 항상 권장됩니다.
지금까지 이 교육 트랙에서 배운 사항에 따라 파이프라인에 변환 단계를 추가하였으므로, 이를 문서화하고, 일정을 설정하고, 모니터링해야 합니다. 이러한 요약 추천사항을 따라가면서 지식을 테스트해 보세요.
🔨 작업 지시사항
- 빌드가 완료되면 저장소 상단 중앙에 있는 Explore lineage 버튼을 클릭합니다.
- 모든 조상 노드를 보여주고 논리적으로 배열하기 위해 데이터셋을 펼칩니다(힌트: 모든 노드를 선택하고 ctrl+l을 클릭해 보세요).
- 이 Data Lineage 그래프를
/Ontology Project: Flight Alerts/documentation/에 저장합니다.
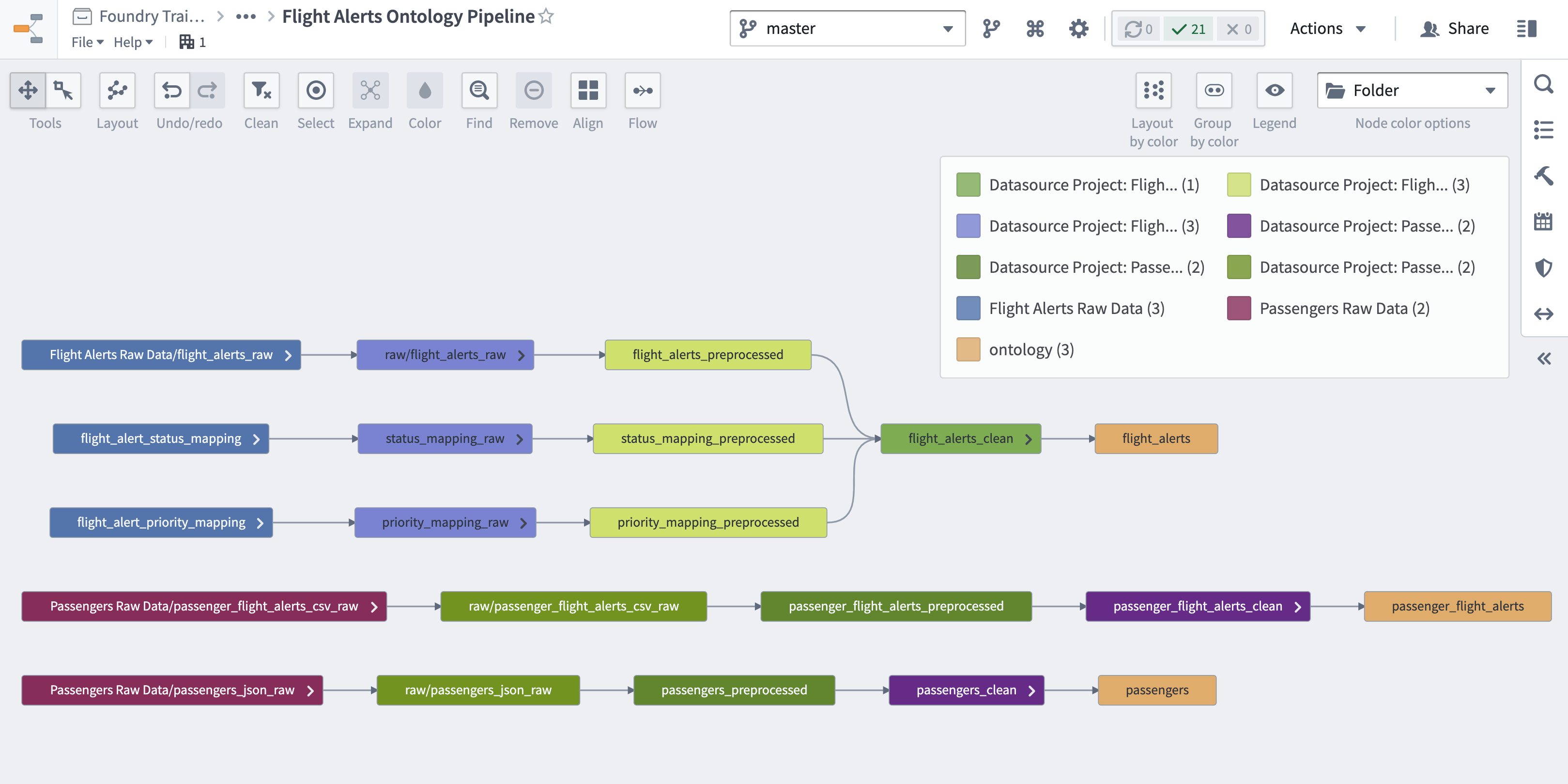
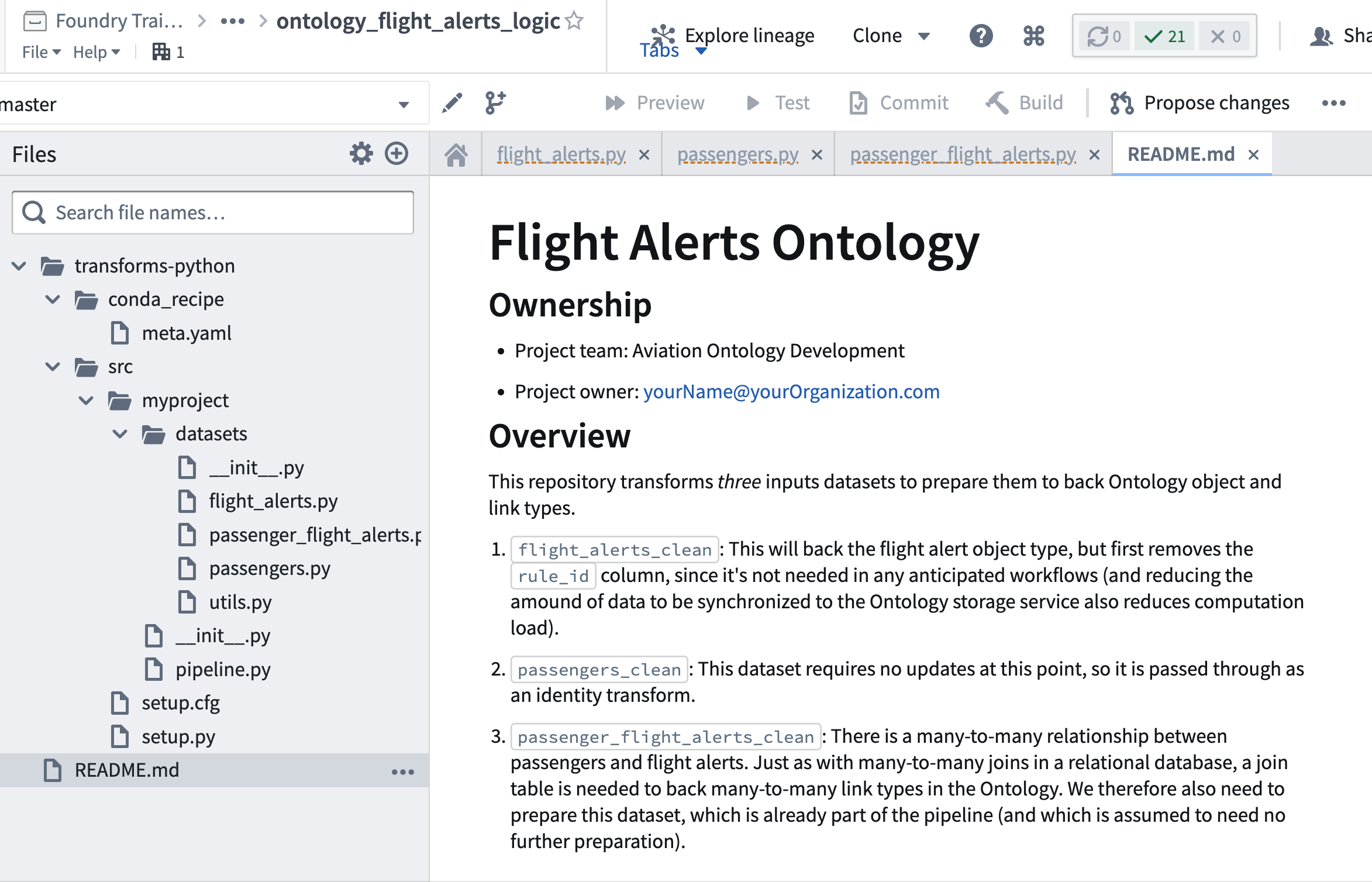
- 저장소에 다른 저장소를 위해 생성된 것들의 구조를 반영하는 README 파일을 추가합니다. 소유자 정보와 설명을 추가하는 것을 고려해 보세요. 이는 이전 튜토리얼 "프로젝트 결과물 생성" 섹션의 "파이프라인 문서 추가"에서 작업 소개를 참조하여 작성할 수 있습니다.
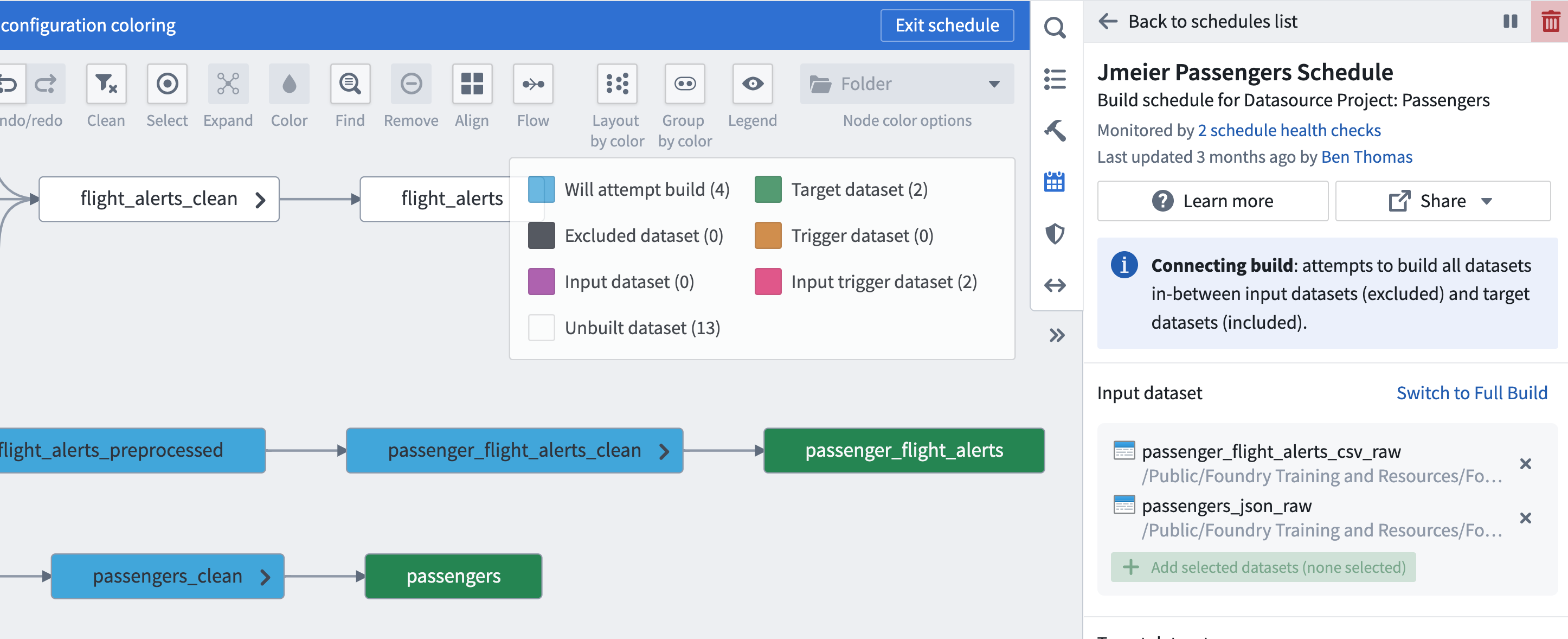
- Data Lineage 그래프에서 Schedules 도우미를 열고 Flight Alerts와 Passengers 일정을 편집해서 대상이 이전에 설정된 clean 데이터셋이 아닌 새로운 ontology 데이터셋이 되도록 합니다.
-
세 개의 새 ontology 데이터셋 각각에 다음의 건강 검사를 적용하고, 이를 관련 검사 그룹에 추가합니다:
- Schema Check (
COLUMN_ADDITIONS_ALLOWED_ STRICT). - Primary Key (severity = critical).
flight_alerts_passenger에 대해서는 검사를 수행하여alert_display_name와passenger_id의 조합을 확인합니다. - Time Since Last Updated (1 deviation > the median)
- Schema Check (
Ontology에서 오브젝트와 링크 유형을 설정한 후에 마지막 검사를 추가하도록 돌아올 것입니다. 참고로 이 새로운 모든 데이터셋은 자동으로 기존의 Schedule Status와 Schedule Duration 검사에 추가됩니다.