7 - 데이터 전처리, 파트 1
이 콘텐츠는 learn.palantir.com ↗에서도 사용할 수 있으며 접근성을 위해 여기에 제공됩니다.
📖 작업 소개
Datasource Project: Flight Alerts 프로젝트의 데이터셋과 마찬가지로, 승객 및 passenger_flight_alerts(승객과 비행 알림을 매핑) 데이터셋에 대한 전처리 단계가 필요합니다. 예상할 수 있듯이, 첫 번째 작업은 데이터셋 파일을 읽고 Spark DataFrame으로 파싱하여 최적화된 Parquet 형식으로 작성하는 것입니다.
Parquet은 열 이름에 특수 문자나 공백을 허용하지 않으므로, 전처리 단계에서는 열 이름을 정리하는 작업도 포함됩니다. Foundry가 제공하는 API와 패키지 중 하나인 transforms.verbs.dataframes 패키지의 sanitize_schema_for_parquet을 사용하면 DataFrame 열 이름에서 Parquet 파일로 저장할 때 문제가 되는 문자를 제거하여 데이터셋이 성공적으로 빌드되지 못하는 것을 방지합니다.
🔨 작업 지침
-
먼저,
Master에서yourName/feature/tutorial_preprocessed_files라는 이름의 새로운 브랜치를 생성합니다. -
Code Repository의 Files 섹션에서
/datasets폴더를 마우스 오른쪽 버튼으로 클릭하고,/preprocessed라는 새 폴더를 생성합니다. -
/preprocessed폴더에passenger_flight_alerts_preprocessed.py라는 새로운 파이썬 파일을 생성합니다. -
passenger_flight_alerts_preprocessed.py파일을 열고 기본 내용을 아래 코드 블록으로 바꿉니다.from transforms.api import transform, Input, Output from transforms.verbs.dataframes import sanitize_schema_for_parquet @transform( parsed_output=Output("/${space}/Temporary Training Artifacts/${yourName}/Data Engineering Tutorials/Datasource Project: Passengers/datasets/preprocessed/passenger_flight_alerts_preprocessed"), raw_file_input=Input("${passenger_flight_alerts_csv_raw_RID}"), ) def read_csv(ctx, parsed_output, raw_file_input): # 입력 데이터셋의 파일 시스템에 대한 변수를 생성합니다 filesystem = raw_file_input.filesystem() # 입력 데이터셋의 파일에 대한 하둡 경로 변수를 생성합니다 hadoop_path = filesystem.hadoop_path # 입력 데이터셋의 각 파일의 절대 경로를 포함하는 배열을 생성합니다 paths = [f"{hadoop_path}/{f.path}" for f in filesystem.ls()] # 입력 데이터셋의 모든 CSV 파일에서 Spark 데이터프레임을 생성합니다 df = ( ctx .spark_session .read .option("encoding", "UTF-8") # UTF-8은 기본값입니다 .option("header", True) .option("inferSchema", True) .csv(paths) ) """ sanitize_schema_for_parquet 함수를 사용하여 출력 데이터셋에 데이터프레임을 작성하고, 열 이름에 출력 parquet 파일 작성을 방해할 수 있는 특수 문자가 포함되지 않도록 합니다 """ parsed_output.write_dataframe(sanitize_schema_for_parquet(df)) -
다음을 바꿉니다:
- 6행의
${space}를 당신의 공간으로 바꿉니다. - 6행의
${yourName}을 당신의 튜토리얼 연습 자료 폴더 이름으로 바꿉니다. - 7행의
${passenger_flight_alerts_raw_RID}를passenger_flight_alerts_csv_raw데이터셋의 RID로 바꿉니다. 이는passenger_flight_alerts_raw.py에서 정의된 출력입니다. 이전 작업에서 경로를 RID로 바꾸었다면 해당 파일에서 RID를 복사하여 이 파일에 붙여넣을 수 있습니다. - 아니면, 아래와 같이 Foundry Explorer 도우미를 사용하여 작업을 통해 RID를 얻을 수 있습니다.
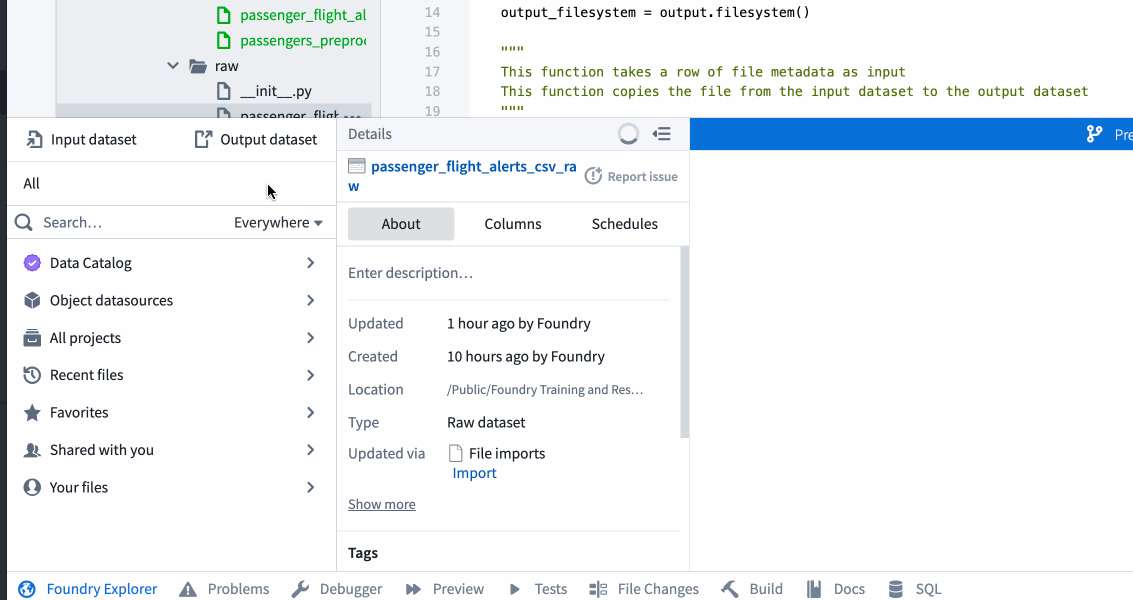
- 6행의
-
오른쪽 상단의 Preview 버튼을 사용하여 코드를 테스트하여 결과물이 원시 파일이 아닌 데이터셋으로 표시되는지 확인합니다. 미리보기 창에서 Configure input files를 클릭하라는 메시지가 표시되면
Configure...를 클릭하고 다음 화면에서passenger_flight_alerts.csv옆의 상자를 선택합니다. -
테스트가 예상대로 작동하면 의미 있는 메시지와 함께 코드를 커밋합니다. 예를 들어, "feature: add passenger_flight_alerts_preprocessed".
-
승객과 비행 알림을 매핑하는 두 열이 포함된 결과물 데이터셋이 있는지 확인하기 위해 기능 브랜치에서
passenger_flight_alerts_preprocessed.py코드를 빌드합니다.