3 - 승객 데이터소스 프로젝트 생성 및 채우기, 파트 2
이 내용은 learn.palantir.com ↗에서도 확인할 수 있으며, 접근성을 위해 여기에 제공됩니다.
📖 작업 소개
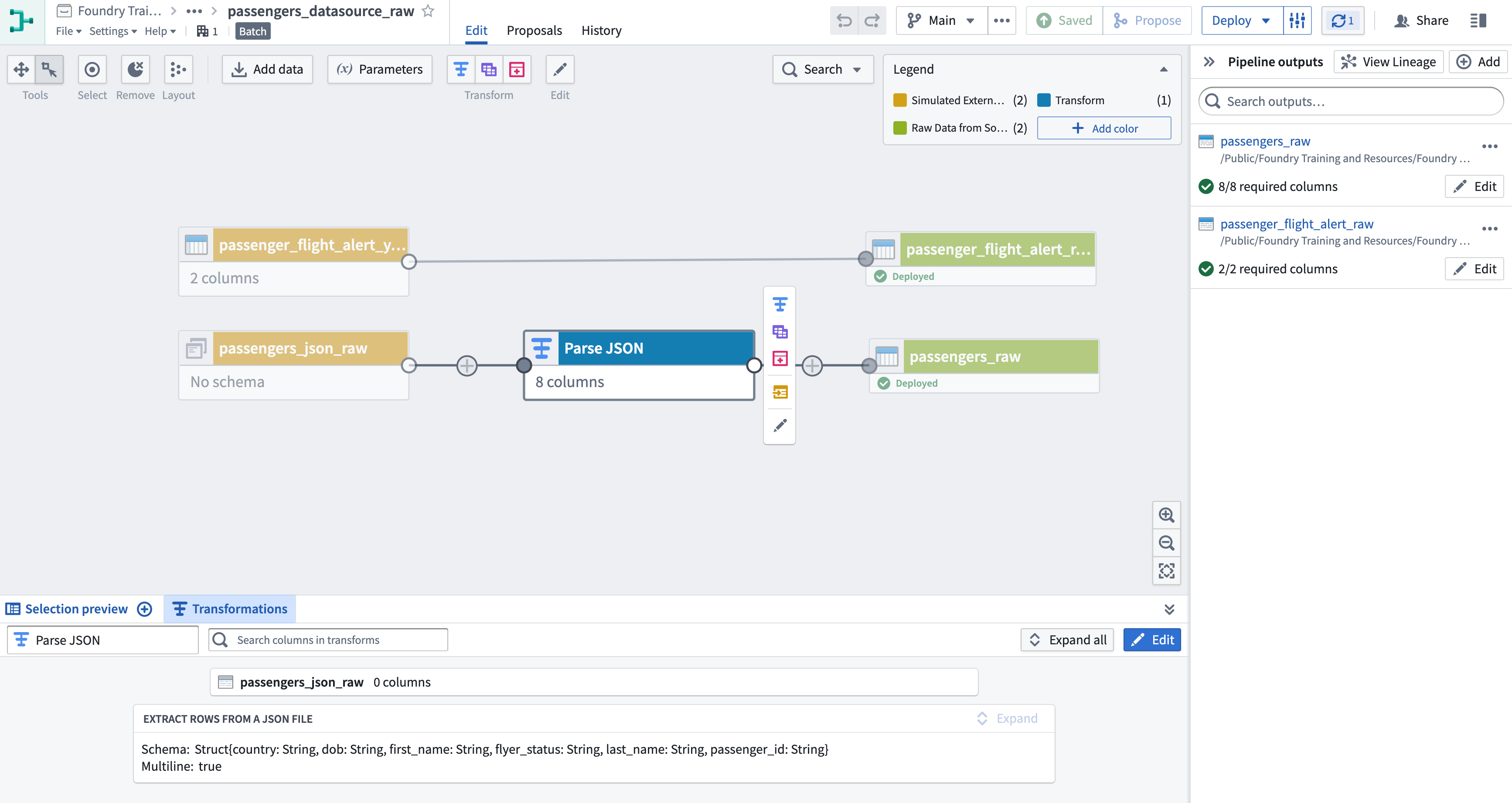
Pipeline Builder 그래프에서 볼 수 있듯이, passengers_raw_json에는 스키마가 없습니다. 이는 파일이 JSON으로 작성되어 있고 먼저 Spark가 작업할 수 있는 형식으로 변환되어야 하기 때문입니다. 이 작업은 Pipeline Builder가 JSON과 XML을 Foundry 데이터셋으로 파싱하는 방법을 보여줍니다.
🔨 작업 지시사항
-
JSON 파일에서 행 추출 보드를 사용하여
passengers_json_raw데이터셋에 변환을 추가합니다. -
변환 화면의 왼쪽 상단에서 변환의 이름을 "Parse JSON"으로 지정합니다.
-
예제 데이터 텍스트 영역에 원시 데이터에서 가져온 다음 JSON 오브젝트를 입력합니다. 그러면 Pipeline Builder에서 이 단일 오브젝트에서 스키마를 추론할 수 있습니다.
{ "passenger_id": "0f7a3494b080426ca95bb6d155c33e42", "first_name": "Benjamin", "last_name": "Payne", "dob": "7/16/73", "country": "Mexico", "flyer_status": "None" } -
스키마 생성 버튼을 클릭하고 적용을 클릭합니다.
-
그래프로 돌아가서 새로운 변환에서
passengers_raw라는 새로운 결과물을 생성합니다. -
아래에 표시된 것처럼 가져오기와 결과물에 노드 색상을 추가하는 것을 고려합니다.
-
파이프라인을 저장하고 배포합니다.