16 - 데이터 전처리를 위한 유틸리티 파일 적용하기
이 내용은 learn.palantir.com ↗에서도 확인할 수 있으며, 접근성을 위해 여기에 제공됩니다.
📖 작업 소개
이 레포지토리 내의 모든 파일에서 접근 가능한 이러한 유틸리티를 생성한 후, 이를 원시 데이터셋에 적용하여 전처리된 데이터셋을 만들 것입니다. 이 작업은 이전 연습에서의 몇몇 단계를 재현하므로, 지시사항은 최소한의 방향성을 제공하며 연습할 기회를 제공하기 위해 간략하게 설명됩니다.
🔨 작업 지시사항
-
레포지토리의 Files 패널에서
/datasets폴더를 오른쪽 클릭하고 New folder를 선택합니다. -
새 폴더의 이름을
preprocessed로 지정하고 파일 생성 창의 오른쪽 하단에 있는 Create를 클릭합니다. -
새로운
preprocessed폴더에 다음 세 개의 파일을 생성합니다:flight_alerts_preprocessed.pypriority_mapping_preprocessed.pystatus_mapping_preprocessed.py
-
모든 세 개의 파일에 다음 코드 스니펫을 2번 라인에 추가하여 레포지토리의 유틸 파일을 참조하고 사용하도록 설정합니다:
from myproject.datasets import type_utils as types, cleaning_utils as clean -
세 개의 새로운 변환 파일 각각에서 SOURCE_DATASET_PATH를 이전 연습에서 생성된 원시 결과물 파일의 RID로 교체합니다. 아래 예시 이미지는
flight_alerts_preprocessed.py파일의 복사/붙여넣기 워크플로를 보여줍니다.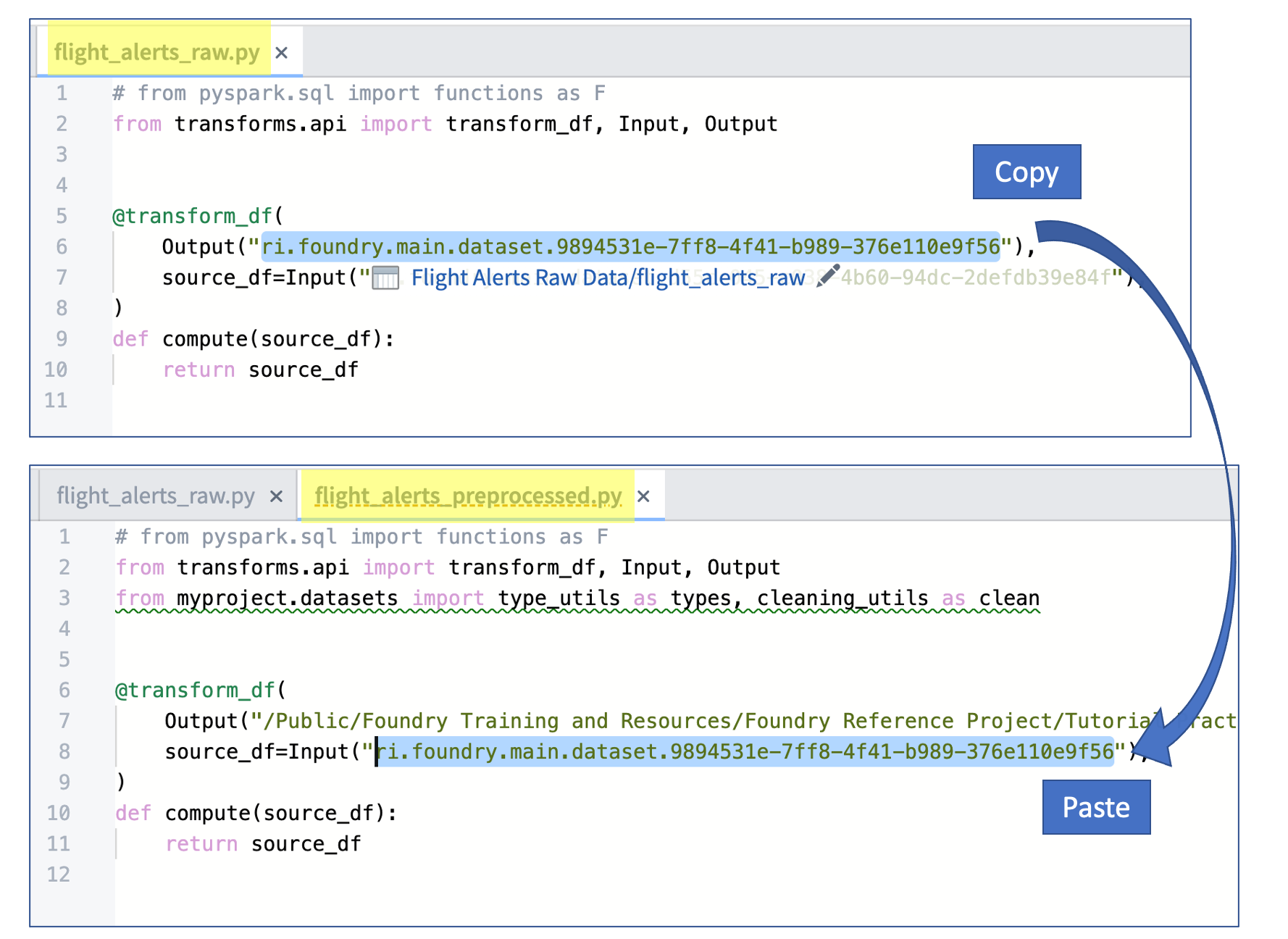
-
세 개의 새로운 변환 파일 각각에서 10번 라인 이후의 모든 내용을 해당 코드 블록으로 교체합니다:
-
아래는
flight_alerts_preprocessed.py파일 코드를 참고하세요.def compute(source_df): # define string columns to be normalized normalize_string_columns = [ 'category', ] # define columns to be cast to strings cast_string_columns = [ 'priority', 'status', ] # define columns to be cast to dates cast_date_columns = [ 'flightDate', ] # cast columns to appropriate types using functions from our utils files typed_df = types.cast_to_string(source_df, cast_string_columns) typed_df = types.cast_to_date(typed_df, cast_date_columns, "MM/dd/yy") # normalize strings and column names using functions from our utils files normalized_df = clean.normalize_strings(typed_df, normalize_string_columns) normalized_df = clean.normalize_column_names(normalized_df) return normalized_df -
아래는
priority_mapping_preprocessed.py와status_mapping_preprocessed.py파일 코드를 참고하세요 (두 파일 모두 동일한 코드 블록을 사용할 것입니다).def compute(source_df): # define string columns to be normalized normalize_string_columns = [ 'mapped_value', ] # define columns to be cast to strings cast_string_columns = [ 'value', ] # cast columns to appropriate types and normalize strings using functions from our utils files normalized_df = types.cast_to_string(source_df, cast_string_columns) normalized_df = clean.normalize_strings(normalized_df, normalize_string_columns) return normalized_df
전처리된 변환에서 어떻게 청소와 유형 유틸이 호출되는지 코드 주석과 문법을 검토하세요.
-
-
각 변환 파일을 미리보기 옵션을 사용하여 테스트하고, 유틸 함수의 적용이 결과물을 어떻게 변경하는지 확인하세요 (예:
flightDate열이 이제 date 유형이며, 매핑 파일의mapped_values열이 적절하게 형식화되어 있습니다). -
"기능: 전처리 변환 추가"와 같은 의미있는 메시지로 코드를 커밋합니다.
-
CI 검사가 통과되면, 기능 브랜치에서 각 데이터셋을 빌드합니다.
-
브라우저를 새로고침해야 할 수도 있습니다) 각 전처리된 변환 파일로 돌아가서 하이퍼링크 텍스트인 "Replace paths with RIDs"를 클릭하는 것을 고려하세요.
-
데이터셋 애플리케이션에서 브랜치의 결과물 데이터셋을 검증한 후, 기능 브랜치를
Master로 병합하세요. -
기능 브랜치를 삭제하세요.
-
Master브랜치에서 데이터셋을 빌드하고 데이터셋 애플리케이션에서 결과물을 확인하세요.