7 - 전처리 로직: 데이터셋 매핑
이 내용은 learn.palantir.com ↗에서도 사용할 수 있으며 접근성을 위해 여기에 제공됩니다.
📖 작업 소개
이제 두 매핑 데이터셋에 유사한 변환을 적용해봅시다. 두 데이터셋 모두 열 이름을 정규화하고 값들을 스트링으로 변환하고 표준화해야 합니다.
🔨 작업 지시사항
-
priority_mapping_raw와status_mapping_raw에 대해 변환 노드를 추가합니다(즉, 각각 하나씩). -
각 데이터셋 변환에 대해:
- 애플리케이션 왼쪽 상단에 있는 변환 이름을 각각 Preprocess priority mapping 및 Preprocess status mapping으로 지정합니다.
- 값 열을 스트링으로 Cast 합니다.
- mapped_value 열을 타이틀 케이스로 변환합니다.
-
추가로,
status_mapping_raw에서 공백을 제거하고 밑줄 없이 값을 타이틀 케이스로 변환하는 변환을 찾아 구성해 보세요. 만약 어려움이 있다면, 힌트에서 제안된 구현 방법을 참고하세요.힌트:
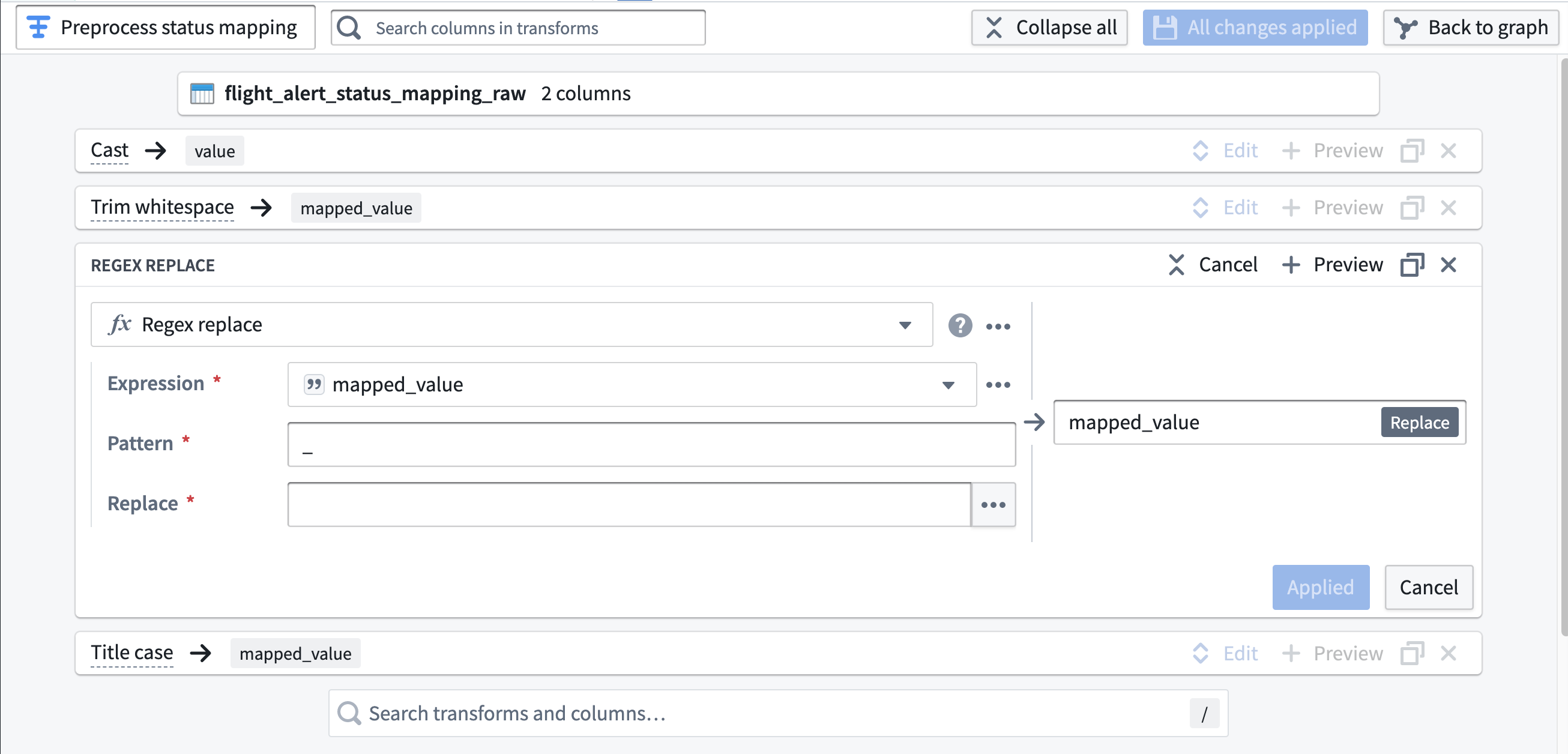
-
각각
priority_mapping_preprocessed와status_mapping_preprocessed라는 파이프라인 결과물을 추가합니다. -
파이프라인을 저장하기와 배포하기를 통해
/preprocessed폴더에 결과물을 빌드합니다.