4 - 탭 형식 데이터 질문 검토
이 내용은 learn.palantir.com ↗에서도 확인할 수 있으며 접근성을 위해 여기에 제시되었습니다.
이 데이터셋은 몇 개의 파일로 구성되어 있습니까?
데이터셋 애플리케이션의 세부정보 탭에서는 파일 필드에 데이터셋 파일의 수와 총 파일 수가 표시됩니다. 이는 일반적으로 데이터베이스 파일 수 + 트랜잭션 중 생성된 Spark 로그 파일 수입니다.
답변은 Spark가 변형을 실행하는 방식에 따라 다를 수 있지만, 그 수는 일반적으로 5에서 8 사이입니다. 이는 Contour와 Code Workbook과 같은 탭 형식 데이터를 사용하는 애플리케이션의 성능이 Spark가 이러한 데이터셋 파일을 얼마나 효율적으로 생성했는지(즉, 파일의 크기와 수량)에 따라 달라지기 때문에 데이터 분석가에게 중요합니다. Spark의 작동 방식에 대한 자세한 정보는 Spark 개념을 검토하거나 녹화된 Spark 최적화 교육 ↗을 시청하는 것을 고려해 보세요.
마지막으로 성공적으로 이 파일들을 일관된 데이터셋으로 조립한 트랜잭션은 언제였습니까?
기록 탭에서는 이 데이터셋의 모든 빌드 시도를 볼 수 있습니다. 목록에서는 성공한 작업, 실패한 작업, 실행되지 않은 작업 등을 찾을 수 있습니다. 현재 데이터셋 뷰의 날짜, 상태, 트랜잭션 유형을 가장 빠르게 확인하는 방법은 세부정보 탭을 열고 화면 왼쪽에 있는 현재 트랜잭션 뷰 옵션을 클릭하는 것입니다.
아래의 이미지에서(등록 상황에 따라 다를 수 있습니다), 가장 최근의 성공적인 트랜잭션은 2022년 10월 6일 오전 9시 4분에 이루어진 스냅샷이었습니다.
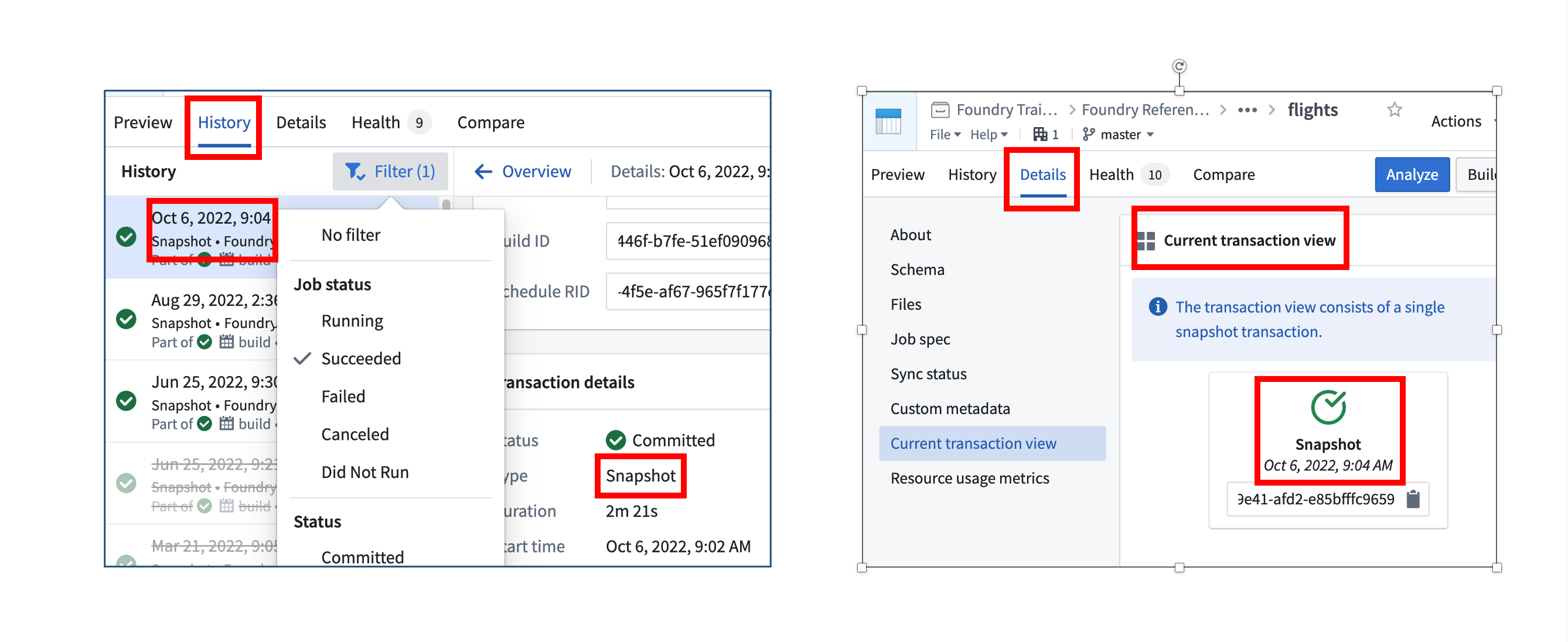
어떤 트랜잭션 유형이 현재 뷰를 생성했습니까?
위의 답변을 참조하세요.
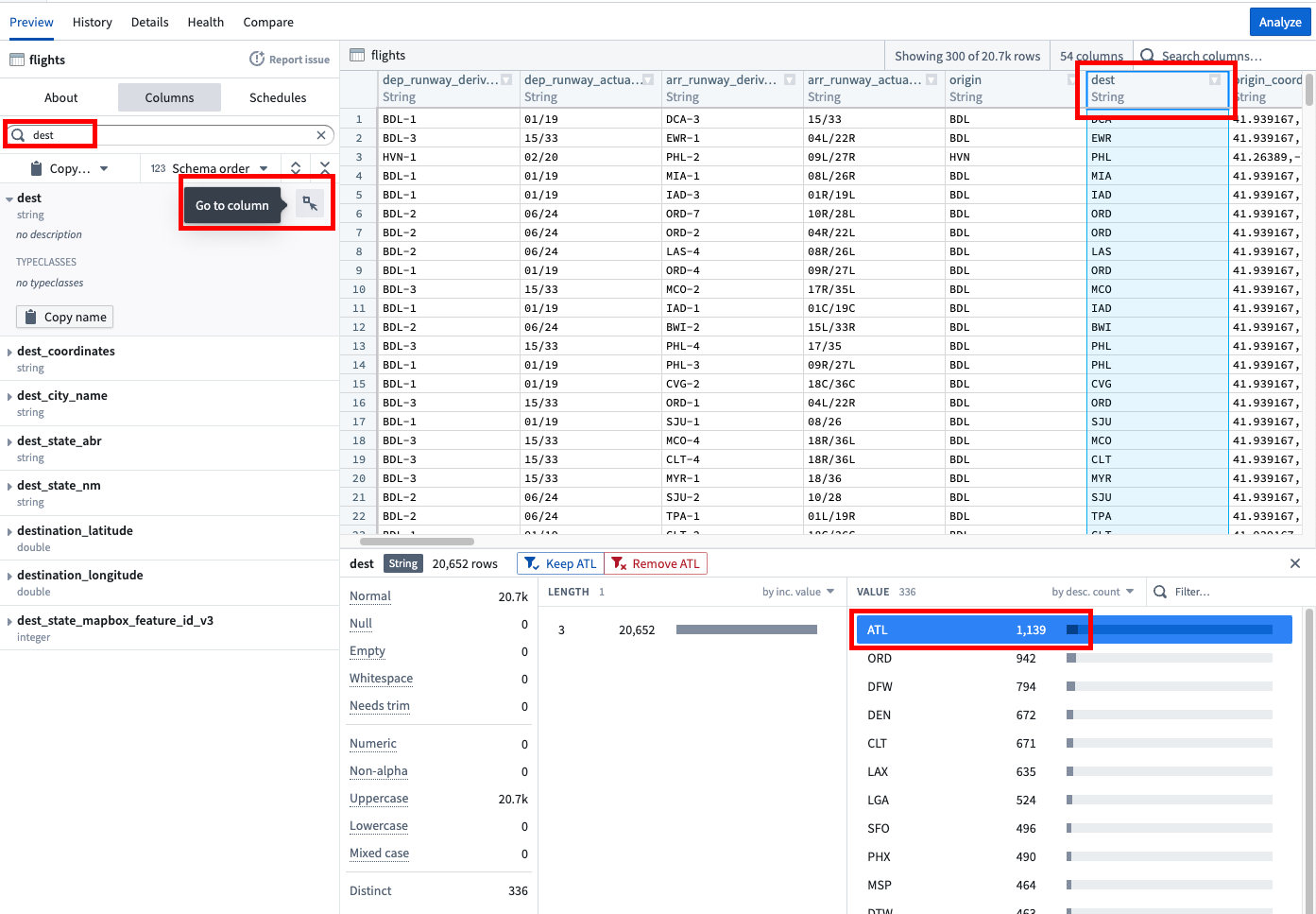
가장 흔한 목적지는 어디입니까?
Foundry의 분석 애플리케이션 중 하나로 데이터셋을 가져가기 전에, 미리보기 표를 사용하여 데이터 구조를 이해하고 데이터셋 값을 빠르게 탐색할 수 있습니다. 아래 이미지의 분석가는 목적지 열을 검색하고 데이터 뷰를 내림차순 카운트로 전환하여, 내림차순 카운트로 정렬된 목적지를 볼 수 있었습니다.
히스토그램을 검토해 보면, ATL에 가장 많은 항공편이 있다는 것을 알 수 있습니다.